







记录一些自己可能会忘的解法
题目合集:https://github.com/yanring/jianzhi-Offer-Leetcode?tab=readme-ov-file
LCR 120. 数组中重复的数字
我直接map暴力。。结果空间复杂度不如下面这个
参考解法
原地交换,时间复杂度O(n),空间复杂度O(1)。
可以做原地交换是因为题目中有个限制,长度为n的数组里数据都是0~n-1。
240. Search a 2D Matrix II
我用了个行/列的二分。结果时间复杂度还是很高。
参考解法
利用特性。从右上角走。找到第一个比target大的数的下标x。此时x上方的所有行都比target小(因为x比target小,x的左边、上边的数都比x小)。当前列处理完毕,左移继续判断。
LCR 122. 路径加密
本身题目是.变成空格。但是题解里的题目貌似是空格变成“%20”。参考题解的空间复杂度更低。先开辟空间然后添加符号。
参考题解
11旋转数组的最小数字:154. Find Minimum in Rotated Sorted Array II
我的做法是边遍历边判断,数组x2遍历。
看了下其他人解法还有二分的。但是二分需要注意数组可以有重复的。
12√矩阵中的路径:https://leetcode.com/problems/word-search/description/
非常简单的dfs。记录这道题是因为一直超时。
超时原因是:vector赋值传参太慢了,所以传vector最好用引用传参。
13机器人的运动范围:LCR 130. 衣橱整理
大多数人解法是dfs/bfs,但是其实可以找规律。发现一定是左上角蔓延开来(题目中带提示,往右和往下走)。因此可以直接从初始左边,自左向右、自上向下判断。
此外,应该还有数学解法,计算边界值直接计算满足条件的区域点数。
18√删除链表的节点 ->(简单版)
我的第一反应是修改前一个节点的next,第二个反应是依序复制val。
做完发现题解里有更快的方法。。即只复制下一个的val,然后直接跳过下个节点(真实地删除下个节点)。
19正则表达式匹配
这道题问题在于题意理解,a*整体表示a可以0或者多次,即空字符串也是满足需求的。.*表示任意字符的任意次数,即空字符串、abc也是满足需求的。
class Solution {
public:
bool isMatch(string s, string p) {
int dp[22][22]; //0表示不能匹配 1表示刚好匹配(不能多字符了) 3表示匹配且可以更长的字符串匹配当前模式
memset(dp, 0, sizeof(dp));
s = "#" + s;
p = "#" + p;
int s_len = s.length();
int p_len = p.length();
dp[0][0] = true;
int sub = 1;
while(sub + 1 <= p_len){
if(p[sub+1] == '*'){
dp[0][sub+1] = 1;
sub += 2;
}
else{
break;
}
}
for(int i = 1; i <= s_len; i++){
for(int j = 1; j <= p_len; j++){
int yes = 0;
if(p[j] == '.'){
if(dp[i-1][j-1] > 0) yes = 1;
}
else if(p[j] == '*'){
// zero: b - ba*
if(j-2>=0 && dp[i][j-2] > 0) yes = 1; // 刚好符合不能再多了
// one: b - b*
if(dp[i][j-1] == 1) yes = 3;
// more: bb - b*
if(dp[i-1][j] == 3){
if(s[i] == s[i-1] || p[j-1] == '.') yes = 3;
}
}
else{// 普通字符
if(s[i] == p[j] && dp[i-1][j-1] > 0) yes = 1;
}
dp[i][j] = yes;
}
}
return dp[s_len][p_len];
}
};
22√链表中倒数第K个节点
双指针题解通过双指针来处理“倒数第x个节点”问题。
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
int num = 0;
ListNode* vhead = new ListNode(-1, head);
ListNode* first = vhead;
ListNode* second = vhead;
while(n) first = first->next, n--;
while(first->next) first = first->next, second = second->next;
second->next = second->next->next;
return vhead->next;
}
};
24 √反转链表
反转
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* vhead = new ListNode(-1, nullptr);
ListNode* curr = head;
while(curr){
ListNode* nex = curr->next;
curr->next = vhead->next;
vhead->next = curr;
curr = nex;
}
return vhead->next;
}
};
31√栈的压入、弹出序列
https://leetcode.com/problems/validate-stack-sequences/description/
算是经典题。模拟。
35√复杂链表的复制
https://leetcode.com/problems/copy-list-with-random-pointer/description/
每个节点有两个指针next和random。因为random所以难以直接复制。常见做法可以用map存下每个节点和random的映射。
更好的解法,把新node穿插到旧node之间
class Solution {
public:
Node* copyRandomList(Node* head) {
if(head == nullptr) return nullptr;
// 插入新的节点
Node *curr = head;
while(curr){
Node *nex = curr->next;
Node *n = new Node(curr->val);
n->next = nex;
n->random = curr->random;
curr->next = n;
curr = nex;
}
// 更新random指针
curr = head;
while(curr){
curr = curr->next; // new node
if(curr->random) curr->random = curr->random->next;
curr = curr->next; // old node
}
// 恢复原list和新list的next指针
Node *vhead = new Node(-1);
vhead->next = head->next;
curr = head;
while(1){
Node *nex = curr->next;
if(!nex) break;
Node *nnex = nex->next;
curr->next = nnex;
curr = nex;
}
return vhead->next;
}
};
38√字符串的排列 (有重复值)
dfs,每次判断第i个位置可以放什么数。prev记录当前位置的数的前一个相同数的下标。
放数的时候判断,当前数x的前一个数是否已经被用了。从而确保对于相同数是按照下标顺序取的。
class Solution {
public:
int prev[11];// i下标对应值的上一个相同值的下标
int sub[21];
bool vis[10];
vector<vector<int>> ans;
vector<int> mynums;
int n;
void dfs(vector<int> x, int data){
x.push_back(data);
if(x.size() == n){
ans.push_back(x);
return;
}
for(int j = 0; j < n; j++){
if(vis[j])continue;
if(prev[j] != -1 && !vis[prev[j]])continue;//前一个相同的数没有用
int tmp_data = mynums[j] + 10;
vis[j] = true;
dfs(x, mynums[j]);
vis[j] = false;
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
n = nums.size();
mynums = nums;
memset(vis, 0, sizeof(vis));
memset(sub, -1, sizeof(sub));
for(int i = 0; i < n; i++){
int tmp_data = nums[i] + 10;
prev[i] = sub[tmp_data];
sub[tmp_data] = i;
}
vector<int> x;
// 第一个位置是哪个数
for(int i = 0; i < n; i++){
if(prev[i] != -1) continue;
vis[i] = true;
dfs(x, mynums[i]);
vis[i] = false;
}
return ans;
}
};
39√数组中出现次数超过一半的数字
常见做法是用map存储和更新目前的众数。但是hashmap太慢了,还需要空间。【特点是,数量占比大,考虑抵消】
参考解法
记录和更新 众数x和x出现的次数f。如果当前数和x不一样,f–,反之++。如果f==-1更新众数。
这是因为,众数超过了一半(而不是等于)。
极限情况1,x全部出现后出现其他数,最后f的结果=x的数量-其他的数量。
极限情况2,其他数全都出现后出现x,最后f的结果=-前面的处理结果+x的数量。但是x是真的众数,所以最后肯定能更新x为众数。
极限情况3,其他数和x交叉,因为x的数量更多,所以肯定能在f±抵消的情况下,x更多。
class Solution {
public:
int majorityElement(vector<int>& nums) {
int n = nums.size();
int x = 0, num = 0;
for(int i = 0; i < n; i++){
if(num == 0) x = nums[i];
if(nums[i] == x) num++;
else num--;
}
return x;
}
};
39√数组中出现次数超过1/3的数字们(升级版)
假设有两个结果x和y,其他的结果为z。|x|表示x的数量。则|x|+|y| > |z|*2,左式>右式
所以可以维护x和y各自的出现次数。
遇到x和y各自次数+1,左式+1。但是右边遇到z就得+2,即左式x和y的数量各自-1。
class Solution {
public:
bool check(vector<int>&nums, int x){
int n = nums.size();
int num = 0;
for(int i = 0; i < n; i++)
if(nums[i] == x) num += 1;
return num > n/3;
}
vector<int> majorityElement(vector<int>& nums) {
int v1, v2;
int n1 = 0, n2 = 0;
int n = nums.size();
for(int i = 0; i < n; i++){
if(n1 == 0 && nums[i] != v2){
v1 = nums[i];
n1 += 1;
}
else if(n2 == 0 && nums[i] != v1){
v2 = nums[i];
n2 += 1;
}
else{// n1 != 0 && n2 != 0
if(nums[i] == v1){
n1 += 1;
}
else if(nums[i] == v2){
n2 += 1;
}
else{//nums[i] != v1 && nums[i] != v2
n1--;
n2--;
}
}
}
vector<int>x;
// printf("%d %d\n", v1, v2);
if(n1 && check(nums, v1)) x.push_back(v1);
if(n2 && check(nums, v2)) x.push_back(v2);
return x;
}
};
40√最小的k个数
直接排序O(nlogn),但是不需要有序,所以考虑让前k-1个数都小于第k个数,后面的其他数都大于第k个数。这样第k个数就是要求的结果。
快排分治。
或者用一个最小堆优先队列维护目前为止最大的k个数。
41√数据流中的中位数
用的权值线段树,但是有一个问题是c++中-5/2=-2,5/2=2。这就导致权值线段树计算mid会出问题。所以这里我统一转换为正数处理。
const int maxn = 6e5 + 10;
class MedianFinder {
public:
int nums[maxn];
int root = 1;
int base = 100000;
int B = -100000;
int E = 100000;
MedianFinder() {
memset(nums, 0, sizeof(nums));
}
void add(int id, int num, int b, int e){
nums[id] += 1;
if(b == e) return;
int mid = (b+e)/2;
//[b, mid], [mid+1, e]
if(num <= mid) add(id<<1, num, b, mid);
else add(id<<1|1, num, mid+1, e);
}
void addNum(int num) {
add(root, num+base, B+base, E+base);
}
int getk(int id, int k, int b, int e){
if(b == e) return b;
int mid = (b+e)/2;
int lson = id<<1;
int rson = id<<1|1;
if(nums[lson]>=k) return getk(lson, k, b, mid);
else return getk(rson, k-nums[lson], mid+1, e);
}
double findMedian() {
int total = nums[root];
if(total&1){
return 1.0 * getk(root, total/2 + 1, B+base, E+base) - base;
}
else{
int k1 = total/2;
int k2 = total/2+1;
int v1 = getk(root, k1, B+base, E+base) - base;
int v2 = getk(root, k2, B+base, E+base) - base;
return 0.5* (v1+v2);
}
}
};
43√1~n整数中1出现的次数
单独计算每个数位上的1的可能性。比如对于43527,百位上有1的数字数量为44100;
对于43127,百位有1的数量为:43100+128(指最开始两位是43,则百位后的数字只能在0到27共28个数)。
对于43027,百位有1的数量为:43100,即百位前的数字只能在0到42,而百位后的数字从0到99都可以。
typedef long long ll;
class Solution {
public:
//value 43527: x=43, t=5, y=27, base=100 算百位
// ans = 44 * 100
ll func(ll value, ll base){
ll y = value % base;
ll t = value / base % 10;
ll x = value / (10 *base);
if(t > 1) return (x+1) * base;
// t < 1, e.g., 43027: 43*100
if(t < 1) return x * base;
// t == 1, e.g., 43127: 43*100+1*28
return x * base + (y+1);
}
ll countDigitOne(int n) {
ll ans = 0;
ll base = 1;
while(n >= base){
ans += func(n, base);
base *= 10;
}
return ans;
}
};
49 丑数 Ugly Number II
解法1暴力求n次
const int maxn = 2e3 + 10;
typedef long long ll;
class Solution {
public:
void add(priority_queue<ll, vector<ll>, greater<ll>>&q, ll res, map<ll, bool>&vis){
if(!vis[res]){
vis[res] = true;
q.push(res);
}
}
ll nthUglyNumber(int n) {
priority_queue<ll, vector<ll>, greater<ll>>q;
map<ll, bool>vis;
q.push(ll(1));
vis[1] = true;
ll ans = 1;
for(int i = 1; i <= n; i++){
ans = q.top();
q.pop();
add(q, ans*2, vis);
add(q, ans*3, vis);
add(q, ans*5, vis);
}
return ans;
}
};
解法2dp,逐步生成下一个最小的数。对2、3、5维护下一个乘2、3、5最小的数。因此整体下一个最小的数就从这三者中选。
const int maxn = 2e3 + 10;
typedef long long ll;
class Solution {
public:
ll ugly[maxn];
ll nthUglyNumber(int n) {
ugly[1] = 1;
int i2 = 1, i3 = 1, i5 = 1;
for(int i = 2; i <= n; i++){
ll u2 = ugly[i2] * 2;
ll u3 = ugly[i3] * 3;
ll u5 = ugly[i5] * 5;
ll m = min(min(u2, u3), u5);
ugly[i] = m;
if(u2 == m) i2++;
if(u3 == m) i3++;
if(u5 == m) i5++;
}
return ugly[n];
}
};
50逆序对
https://leetcode.com/problems/reverse-pairs/description/
经典题 树状数组。最普通的版本是求i<j并且nums[i]>nums[j]的数量。这里改成了nums[i]>2*nums[j]。
但是思路是一样的。预处理找到x<nums[i] * 0.5并且x是nums内的数据。然后从右往左遍历,对于第i个数据,找到目前遍历过的(即 都是j)小于等于x的数量。
由于数据范围很大,但是数据量不高,这里要做离散化。
const int maxn = 5e4+10;
class Solution {
public:
int n;
int real_n;
int num[maxn];
int value[maxn];
int nex[maxn];
int c[maxn];
int lowbit(int x){
return x & -x;
}
void add(int id, int v){
while(id<=real_n){
c[id] += v;
id += lowbit(id);
}
}
int sum(int id){
int ans = 0;
while(id > 0){
ans += c[id];
id -= lowbit(id);
}
return ans;
}
int reversePairs(vector<int>& nums) {
memset(c, 0, sizeof(c));
n = nums.size();
map<int,int>mp;// 离散化后 数据从1开始
for(int i = 0; i < n; i++) value[i+1] = nums[i];
sort(value+1, value+1+n);// [1, 1+n)
real_n = 0;
for(int i = 1; i <= n; i++){
if(i == 1){
real_n++;
mp[value[1]] = real_n;
}
else{
if(value[i] == value[i-1]) continue;
real_n++;
mp[value[i]] = real_n;
value[real_n] = value[i];
}
}
int j = 1;// nex[i]表示小于1/2 * value[i]的第一个数的下标
for(int i = 1; i <= real_n; i++){
while(j <= real_n && value[j] < 0.5 * value[i]) j++;
nex[i] = j-1;
}
int ans = 0;
for(int i = n-1; i >= 0; i--){
int real_v = nums[i];
int new_v = mp[real_v];
if(nex[new_v] != 0) ans += sum(nex[new_v]);
add(new_v, 1);
}
return ans;
}
};
56 数组中数字出现的次数
https://leetcode.com/problems/single-number-iii/description/
题意:给定数组,里面除了特定的两个数x和y之外,其他数字都出现2次。而x和y只出现1次。要求在线性时间、常数空间内找到这两个数
重点是两个限制:1.其他数字都出现2次;2.x和y只出现一次。
而异或操作可以让出现两次的数字抵消。从而得到x xor y。
因为x和y不同,异或值肯定不为1,并且两者不同。可以根据1的位置找到同类的数字,并异或,结果就为x或y。
因为x^y^x=y 易得x和y。
class Solution {
public:
int lowbit(int x){
return x & -x;
}
vector<int> singleNumber(vector<int>& nums) {
int all = 0;
int n = nums.size();
for(int i = 0; i < n; i++) all ^= nums[i];
int a = 0;
int lb = lowbit(all);
for(int i = 0; i < n; i++){
if((lb&nums[i]) != 0) a ^= nums[i];
}
int b = a^all;
return vector<int>{a, b};
}
};
59 队列的最大值
题意是维护区间的max。第一反应用的权值线段树进行点操作。后来发现可以用优先队列来维护。速速可以更快一点:
struct node{
int id;
int v;
bool operator <(const node x) const{
return v < x.v;
}
node(int _id, int _v){
id = _id;
v = _v;
}
};
class Solution {
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
vector<int> ans;
priority_queue<node> q;
int l = 0, r = 0;
int n = nums.size();
while(r < k) q.push(node(r, nums[r])), r++;
ans.push_back(q.top().v);
while(r < n){
q.push(node(r, nums[r]));
l++, r++;
while(q.top().id < l)q.pop();
ans.push_back(q.top().v);
}
return ans;
}
};
62 圆圈中最后剩下的数字
约瑟夫环
参考思路
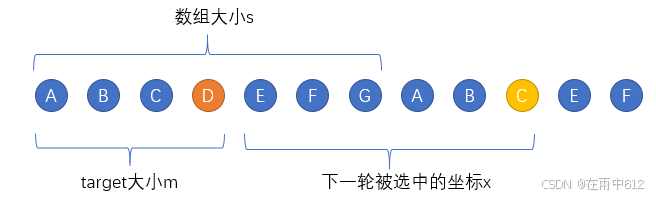
易得,下一轮选中的对象C的坐标x在上一轮s中的坐标为(m+x)%s
class Solution {
public:
int iceBreakingGame(int num, int target) {
int index = 0;
int siz = 2;
while(siz <= num){
index = (index + target) % siz;
siz += 1;
}
return index;
}
};
64 求1+2+…+n ->
求和,难点在于不能用循环、选择结构,不能用乘除操作。题解
主要做法:用&&代替选择结构。
class Solution {
public:
int mechanicalAccumulator(int target) {
target && (target += mechanicalAccumulator(target-1));
return target;
}
};
此外,可以使用位操作。然后使用快速乘(拆位计算)。
65 不用加减乘除做加法
class Solution {
public:
int bitx(int value, int x){
return (value >> x) & 1;
}
int add(int x, int y){
int v1 = (x&y) << 1;
int v2 = x^y;
if(v2 == 0) return v1;
if(v1 == 0) return v2;
return add(v1, v2);
}
int encryptionCalculate(int dataA, int dataB) {
return add(dataA, dataB);
}
};
二进制做法,易得x+y = (x&y)*2+(x^y)
乘2可以用<<1操作,+可以用递归。结束条件为x==0或者y==0。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









