







HTTP传输大文件
早期网络传输的文件非常小,只是一些几K大小的文本和图片,随着网络技术的发展,传输的不仅有几M的图片,还有可以达到几G和几十G的视频;
在这些大文件传输的情况下,100M的光纤或者4G移动网络都会因为网络压力导致在上传或者下载的情况下导致网络传输链路挤的“满满当当”;
数据压缩
通常浏览器在发送请求时都会带上"Accept-Encoding"头字段,该字段用来声明浏览器支持的压缩格式列表,例如gzip,deflate,br等,这样服务器就可以从中选择一种压缩算法,并将其放进"Content-Encoding"响应头中,最后将元数据压缩后发给浏览器;
这种情况下下,如果压缩率是50%,也就是100K数据可以变成50K大小的文件进行传输,从网络的角度考虑,就类似于网络提升了一倍;
这种方法的缺点是,gzip等压缩算法通常只是对文本文件有较好的压缩率,而图片,音频,视频的多媒体文件由于本身已经是高度压缩的,此时再使用gzip处理不会变小(甚至还有可能会增大一点),所以这种方法就不适用了;
由于这种方法对文本类型的数据压缩效果比较好,所以大部分网站会使用该技术作为"保底";
例如,Nginx里就会使用"gzip on"指令,启用对"text/html"的压缩;
数据分块传输
分块传输编码(Chunked transfer encoding)是超文本传输协议(HTTP)中的一种数据传输机制,是一种"化整为零"的思路;分块传输允许HTTP将发送的数据分解成一系列数据块,并以一个或多个块发送;即报文中的body部分不是一次性发送的,而是分成许多块的"chunk"并进行逐个发送,这样程序可以先发送数据而不需要预先知道发送内容的总大小;
在头部加入Transfer-Encoding:chunked之后,就代表这个报文采用了分块编码;这时,报文中的实体需要改为用一系列分块来传输;分块传输编码只在HTTP协议 1.1版本(HTTP/1.1)中提供;
相对于数据压缩那种将大文件整体变小来说,数据分块传输可以保证在大文件无法因压缩处理变小的时候,可以将其拆解,分成多个小块,然后将这些小块分批发给浏览器,浏览器收到后会对拆解后的文件再进行组装复原;这样的好处是,在浏览器的和服务器的内存中都不会在内存中保存文件的全部,每次只是发送一小部分,从而网络不会被大文件占用,内存,宽带等资源就会被节省;
分块传输也可以用于"流式数据",例如由数据库动态生成的表单页面,这种情况下body数据的长度也是未知的,无法在头字段"Content-Length"里给出确切的长度,所以只能通过chunked方式分块发送;
所以"Tranfer-Encodeing:chunked"和"Content-Length"这两个字段是互斥的,也就是说响应报文中的两个字段是不可以同时出现的,一个响应报文的传输长度要么已经知道了,要么是未知的(chunked);
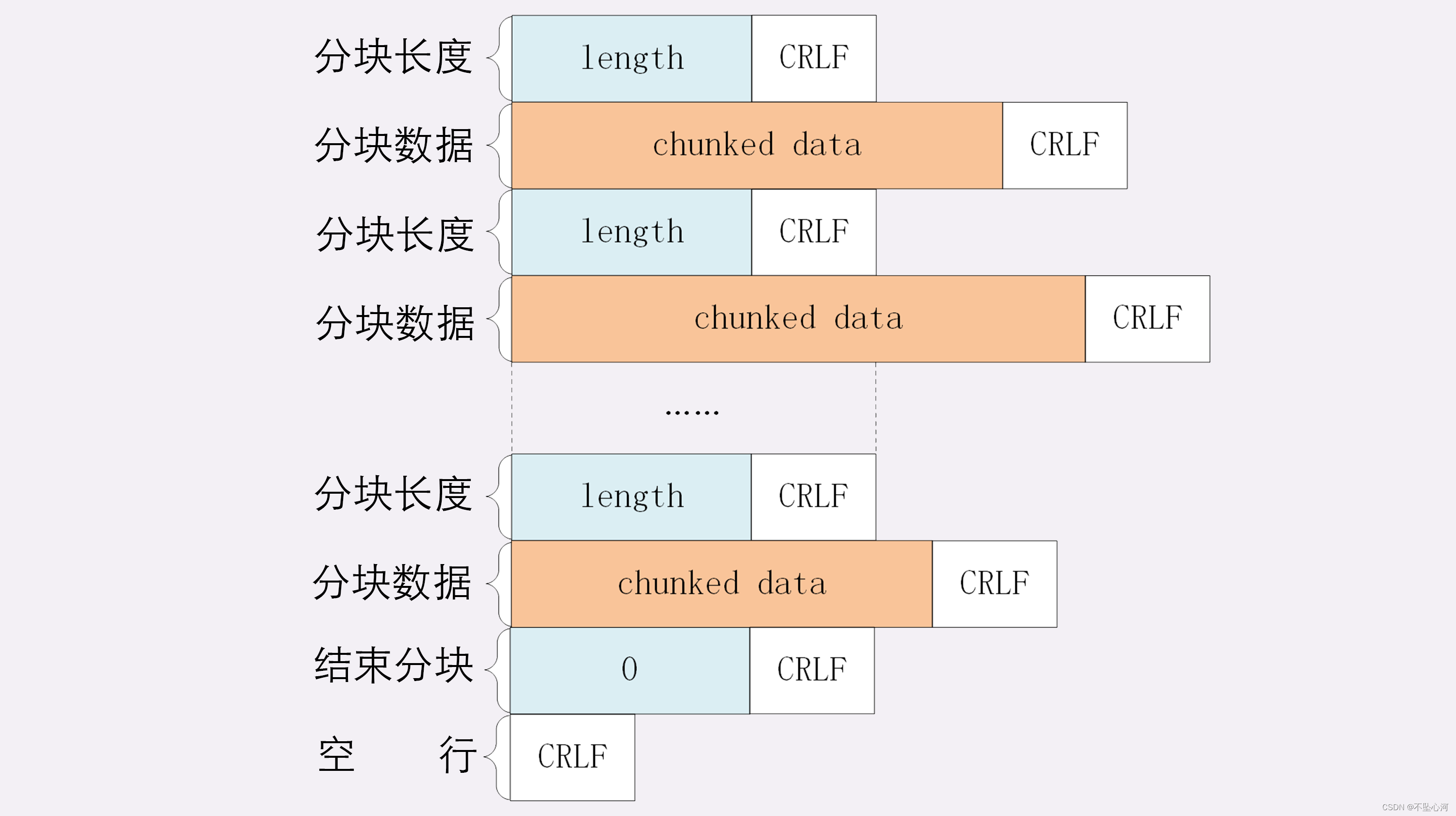
分块传输的编码规则类似于响应头,同样采用了明文的方式;
- 每个分块包含两部分,长度头和数据块;
- 长度头是以CRLF (回车换行,即\r\n) 结尾的一行明文,用16进制数字表示长度;
- 数据块紧跟其后,最后同样使用CRLF结尾,但数据长度不包含CRLF;
- 最后用一个长度为0的块(即最后的空行)来表示实体结束,即"0\r\n\r\n";
这样就可以继续保持连接,为下一个响应做准备;
图示:
注意:
- 分块传输编码只在 HTTP 协议 1.1 版本(HTTP/1.1)中提供;
- 分块传输可以在长度标识处加上分号“;”作为注释;但是几乎所有可以识别Transfer-Encoding数据包的WAF,都没有处理分块数据包中长度标识处的注释,导致在分块数据包中加入注释的话,WAF就识别不出这个数据包了;如:
| 9;kkkkk 1234567=1 4;ooo=222 2345 0 (两个换行) |
数据分块传输的响应流如下

分块编码传输的译码过程:
首先需要先确认收到的数据时使用的 chunked 编码,也就是找到 Transfer-Encoding: chunked;如果找到了,那接下来就可以按照下面的步骤开始进行解析了:
- 找到数据开始地方,也就是第一个 chunk size 开始的地方,这个地方的标识符为:\r\n\r\n
- 获取到这一块的数据长度;
注意:数据长度用十六进制的 ASCII 码表示,所以字符串需要转成数字;
- 获取到数据块长度后,就可以 copy 数据了;
- 接下就跳过 \r\n 去获取下一个数据块长度,然后 copy 数据;直到遇到一个数据块的长度为 0,到这里数据就完全获取成功了;
Content-Encoding 和 Transfer-Encoding 二者经常会结合来用,其实就是针对 Transfer-Encoding 的分块再进行 Content-Encoding压缩;
范围请求(Range Request)
有了分块传输编码,服务器就可以轻松地收发大文件了,但对于上 G 的超大文件,还有一些问题需要考虑;
比如:
- 你在看当下正热播的某穿越剧,想跳过片头,直接看正片,或者有段剧情很无聊,想拖动进度条快进几分钟,这实际上是想获取一个大文件其中的片段数据,而分块传输并没有这个能力;
- 如果下载过程中遇到网络中断的情况,那就必须重头开始;因此需要一种可恢复的机制,所谓恢复是指能从之前下载中断处恢复下载;(和断点续传感觉有点像?)
HTTP 协议为了满足这样的需求,提出了“范围请求”(range requests)的概念,允许客户端在请求头里使用专用字段来表示只获取文件的一部分,相当于是客户端的“化整为零”;
范围请求不是 Web 服务器必备的功能,可以实现也可以不实现,所以服务器必须在响应头里使用字段“Accept-Ranges: bytes”明确告知客户端:“我是支持范围请求的”;
如果不支持的话该怎么办呢?服务器可以发送“Accept-Ranges: none”,或者干脆不发送“Accept-Ranges”字段,这样客户端就认为服务器没有实现范围请求功能,只能老老实实地收发整块文件了;
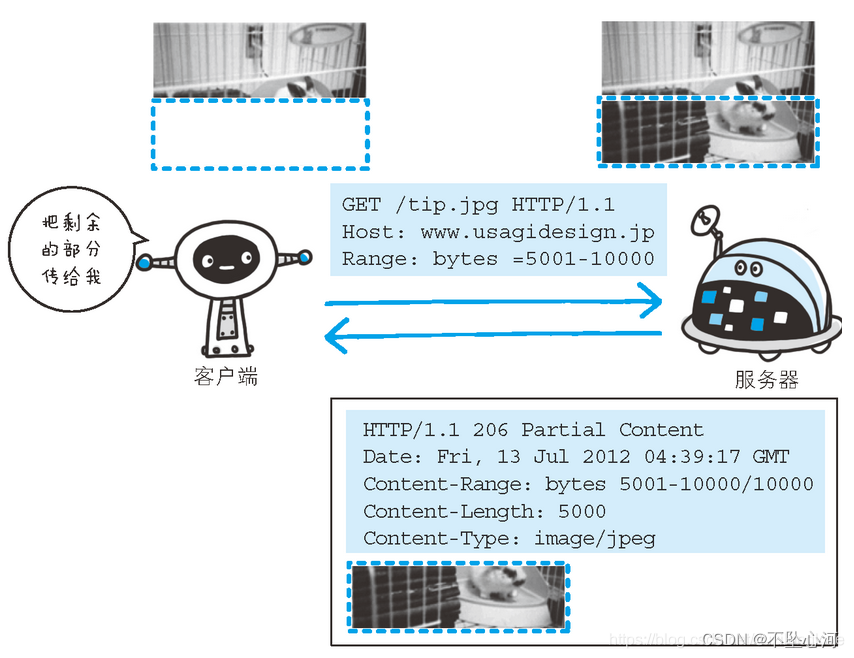
执行范围请求时,会用到首部字段 Range 来指定资源的 byte 范围,格式是“bytes=x-y”,其中的 x 和 y 是以字节为单位的数据范围;
要注意 x、y 表示的是“偏移量”,范围必须从 0 计数,例如前 10 个字节表示为“0-9”,第二个 10 字节表示为“10-19”,而“0-10”实际上是前 11 个字节;
Range 的格式也很灵活,起点 x 和终点 y 可以省略,能够很方便地表示正数或者倒数的范围;
假设文件是 100 个字节,那么:
- “0-”表示从文档起点到文档终点,相当于“0-99”,即整个文件;
- “10-”是从第 10 个字节开始到文档末尾,相当于“10-99”;
- “-1”是文档的最后一个字节,相当于“99-99”;
- “-10”是从文档末尾倒数 10 个字节,相当于“90-99”;
例如:
对一份 10 000 字节大小的资源,如果使用范围请求,可以只请求 5001~10 000 字节内的资源;
多段数据
刚才说的范围请求一次只获取一个片段,其实它还支持在 Range 头里使用多个“x-y”(用逗号分隔),一次性获取多个片段数据;
例如:
Range: bytes=-3000, 5000-7000
这种情况需要响应报文需要使用一种特殊的 MIME 类型:“multipart/byteranges”,表示报文的 body 是由多段字节序列组成的,并且还要用一个可选参数“boundary=xxx”给出段之间的分隔标记;
所以多段数据的格式与多部分对象集合比较类似,可以通过图来对比一下:

解析:
- 每一个分段必须以“- -boundary”开始(前面加两个“-”);
- 之后要用“Content-Type”和“Content-Range”标记这段数据的类型和所在范围;
- 然后就像普通的响应头一样以回车换行结束,再加上分段数据,最后用一个“- -boundary- -”(前后各有两个“-”)表示所有的分段结束;
例如:
| multipart/byteranges:状态码 206(Partial Content,部分内容)响应报文包含了多个范围的内容时使用 HTTP/1.1 206 Partial Content Date: Fri, 13 Jul 2012 02:45:26v GMT Last-Modified: Fri, 31 Aug 2007 02:02:20 GMT Content-Type: multipart/byteranges; boundary=THIS_STRING_SEPARATES
--THIS_STRING_SEPARATES Content-Type: application/pdf Content-Range: bytes 500-999/8000
...(范围指定的数据)... --THIS_STRING_SEPARATES Content-Type: application/pdf Content-Range: bytes 7000-7999/8000
...(范围指定的数据)... --THIS_STRING_SEPARATES-- |
| HTTP/1.1 206 Partial Content Date: Fri, 13 Jul 2012 02:45:26 GMT Last-Modified: Fri, 31 Aug 2007 02:02:20 GMT Content-Type: multipart/byteranges; boundary=THIS_STRING_SEPARATES --THIS_STRING_SEPARATES Content-Type: application/pdf Content-Range: bytes 500-999/8000
…(范围指定的数据)… --THIS_STRING_SEPARATES Content-Type: application/pdf Content-Range: bytes 7000-7999/8000
…(范围指定的数据)… --THIS_STRING_SEPARATES-- |
服务器收到Range字段后的响应过程
- 第一,它必须检查范围是否合法,比如文件只有 100 个字节,但请求“200-300”,这就是范围越界了;服务器就会返回状态码 416,意思是“你的范围请求有误,我无法处理,请再检查一下”;
- 第二,如果范围正确,服务器就可以根据 Range 头计算偏移量,读取文件的片段了,返回状态码“206 Partial Content”,和 200 的意思差不多,但表示 body 只是原数据的一部分;
- 第三,服务器要添加一个响应头字段 Content-Range,告诉片段的实际偏移量和资源的总大小,格式是“bytes x-y/length”,与 Range 头区别在没有“=”,范围后多了总长度;
例如,对于“0-10”的范围请求,值就是“bytes 0-10/100”;
- 最后剩下的就是发送数据了,直接把片段用 TCP 发给客户端,一个范围请求就算是处理完了;
- 另外,对于多重范围的范围请求,响应会在首部字段 Content-Type 标明 multipart/byteranges 后返回响应报文;
- 如果服务器端无法响应范围请求,则会返回状态码 200 OK 和完整的实体内容;
有了范围请求之后,HTTP 处理大文件就更加轻松了,看视频时可以根据时间点计算出文件的 Range,不用下载整个文件,直接精确获取片段所在的数据内容。不仅看视频的拖拽进度需要范围请求,常用的下载工具里的多段下载、断点续传也是基于它实现的,要点是:
- 先发个 HEAD,看服务器是否支持范围请求,同时获取文件的大小;
- 开 N 个线程,每个线程使用 Range 字段划分出各自负责下载的片段,发请求传输数据;
- 下载意外中断也不怕,不必重头再来一遍,只要根据上次的下载记录,用 Range 请求剩下的那一部分就可以了;















 808
808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









