






摘要: Docker的监控原则:根据docker官方声明,一个容器不建议跑多个进程,所以不建议在容器中使用agent进行监控(zabbix等),agent应该运行在宿主机,通过cgroup或是docker api获取监控数据。
kubernetes+docker监控
Docker的监控原则:根据docker官方声明,一个容器不建议跑多个进程,所以不建议在容器中使用agent进行监控(zabbix等),agent应该运行在宿主机,通过cgroup或是docker api获取监控数据。
1、监控分类介绍:
①、自行开发:
通过调用docker的api接口,获取数据、处理、展示,这里不做介绍。
例如:
1)、爱奇艺参照cadvisor开发的dadvisor,数据写入graphite,等同于cadvisor+influxdb,爱奇艺的dadvisor并没有开源
②、Docker——cadvisor:
Google的 cAdvisor 是另一个知名的开源容器监控工具。
只需在宿主机上部署cAdvisor容器,用户就可通过Web界面或REST服务访问当前节点和容器的性能数据(CPU、内存、网络、磁盘、文件系统等等),非常详细。
默认cAdvisor是将数据缓存在内存中,数据展示能力有限;它也提供不同的持久化存储后端支持,可以将监控数据保存、汇总到Google BigQuery、InfluxDB或者Redis之上。
新的Kubernetes版本里,cadvior功能已经被集成到了kubelet组件中
需要注意的是,cadvisor的web界面,只能看到单前物理机上容器的信息,其他机器是需要访问对应ip的url,数量少时,很有效果,当数量多时,比较麻烦,所以需要把cadvisor的数据进行汇总、展示,就看【cadvisor+influxdb+grafana】
③、Docker——Cadvisor+InfluxDB+Grafana:
Cadvisor :将数据,写入InfluxDB
InfluxDB :时序数据库,提供数据的存储,存储在指定的目录下
Grafana :提供了WEB控制台,自定义查询指标,从InfluxDB查询数据,并展示。
此组合仅是监控Docker,不含kubernetes
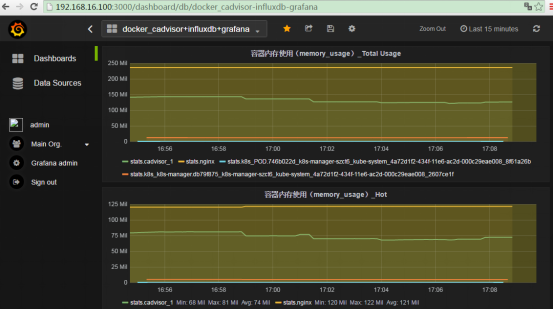
④、Kubernetes——Heapster+InfluxDB+Grafana:
Heapster:在k8s集群中获取metrics和事件数据,写入InfluxDB,heapster收集的数据比cadvisor多,却全,而且存储在influxdb的也少。
InfluxDB:时序数据库,提供数据的存储,存储在指定的目录下。
Grafana:提供了WEB控制台,自定义查询指标,从InfluxDB查询数据,并展示。

2、Cadvisor+Heapster+InfluxDB+Grafana的注意事项:
①、Cadvisor注意事项:
Cadvisor,只需要在kubelet命令中,启用Cadvisor,和配置相关信息,即可。
不需要作为pod或是命令启动
| --cadvisor-port=4194 --storage-driver-db="cadvisor" --storage-driver-host="localhost:8086" |
②、InfluxDB注意事项:
1)、Influxdb必须是0.8.8版本的,否则,Cadvisor的日志会出现:
| E0704 14:29:14.163238 05655 memory.go:94] failed to write stats to influxDb - Server returned (404): 404 page not found |
http://blog.csdn.net/llqkk/article/details/50555442
说是Cadvisor不支持Influxdb的0.9版本,所以这里使用0.8.8的,【ok了】
不同版本的Cadvisor和Influxdb对照表(测试ok):
| Cadvisor版本 | Influxdb版本 |
| 0.7.1 | 0.8.8 |
| 0.23.2 | 0.9.6(以上) |
【Cadvisor和Influxdb的版本不对应,就可以在Cadvisor看到404的报错】
2)、influxdb的数据,需要定期清理,单台Cadvisor,半天的数据就有600M
| #单位:【小时:h】、【天:d】 #删除一小时内: delete from /^stats.*/ where time > now() - 1h #删除一小时外: delete from /^stats.*/ where time < now() - 1h |
3)、关于influxdb可用性的问题,可以写脚本,定期检查是否有相关的数据库和表,没有就出现创建
| #检查是否有某个库 curl -G 'http://192.168.16.100:8086/db?u=root&p=root&q=list+databases&pretty=true' curl -G 'http://192.168.16.100:8086/db?u=root&p=root&q=show+databases&pretty=true' #检查某库中的表【points部分】 curl -G 'http://192.168.16.100:8086/db/cadvisor/series?u=root&p=root&q=list+series&pretty=true' #创建库: 库名:cadvisor curl "http://www.perofu.com:8086/db?u=root&p=root" -d "{\"name\": \"cadvisor\"}" |
③、Grafana注意事项:
Grafana的数据检索,很需要花功夫,可以查看官网相关的语句,也可以直接借用其他人的模板
Influxdb查询语句:
https://docs.influxdata.com/influxdb/v0.8/api/query_language/
④、Heapster注意事项:
对于较大规模的k8s集群,heapster目前的cache方式会吃掉大量内存。
因为要定时获取整个集群的容器信息,信息存储在内存会成为问题,再加上heaspter要支持api获取临时metrics。
如果将heapster以pod方式运行,很容易出现OOM。所以目前建议关掉cache,并以standalone的方式独立出k8s平台,建议每个node都单独运行容器
heapster最大的好处是其抓取的监控数据可以按pod,container,namespace等方式分组,
这样就能进行监控信息的隐私化,即每个k8s的用户只能看到自己的应用的资源使用情况。
heapster收集的数据比cadvisor多,却全,而且存储在influxdb的也少,虽是Google的,但是作用却不尽相同
Heapster容器单独启动时,会连接influxdb,并创建k8s数据库
heapster收集的数据metric的分类有两种,【grafana搜索时,要注意】
1)、cumulative :聚合的是【累计值】,包括cpu使用时间、网络流入流出量,
2)、gauge :聚合的是【瞬时值】,包括内存使用量
参考:https://github.com/kubernetes/heapster/blob/master/docs/storage-schema.md
|
| 描述 | 分类 |
| cpu/limit | cpu预设值,yaml文件可设置 | 瞬时值 |
| cpu/node_reservation | kube节点的cpu预设值,类似cpu/limit | 瞬时值 |
| cpu/node_utilization | cpu利用率 | 瞬时值 |
| cpu/request | cpu请求资源,yaml文件可设置 | 瞬时值 |
| cpu/usage | cpu使用 | 累计值 |
| cpu/usage_rate | cpu使用速率 | 瞬时值 |
| filesystem/limit | 文件系统限制 | 瞬时值 |
| filesystem/usage | 文件系统使用 | 瞬时值 |
| memory/limit | 内存限制,yaml文件可设置 | 瞬时值 |
| memory/major_page_faults | 内存主分页错误 | 累计值 |
| memory/major_page_faults_rate | 内存主分页错误速率 | 瞬时值 |
| memory/node_reservation | 节点内存预设值 | 瞬时值 |
| memory/node_utilization | 节点内存使用率 | 瞬时值 |
| memory/page_faults | 内存分页错误 | 瞬时值 |
| memory/page_faults_rate | 内存分页错误速率 | 瞬时值 |
| memory/request | 内存申请,yaml文件可设置 | 瞬时值 |
| memory/usage | 内存使用 | 瞬时值 |
| memory/working_set | 内存工作使用 | 瞬时值 |
| network/rx | 网络接收总流量 | 累计值 |
| network/rx_errors | 网络接收错误数 | 不确定 |
| network/rx_errors_rate | 网络接收错误数速率 | 瞬时值 |
| network/rx_rate | 网络接收速率 | 瞬时值 |
| network/tx | 网络发送总流量 | 累计值 |
| network/tx_errors | 网络发送错误数 | 不确定 |
| network/tx_errors_rate | 网络发送错误数速率 | 瞬时值 |
| network/tx_rate | 网络发送速率 | 瞬时值 |
| uptime | 容器启动时间,毫秒 |














 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









