







代码存于github:https://github.com/zuodaoyong/Hadoop
Hadoop作业在运行时维护了若干个内置计数器,方便用户监控已处理数据量和已产生的输出数据量
1、采用枚举的方式统计计数
Counter getCounter(Enum<?> var1);
enum CustomCounter{
normal,abnormal
}
context.getCounter(CustomCounter.normal).increment(1);
2、采用计数器组,计数器名称的方式统计
Counter getCounter(String var1, String var2);
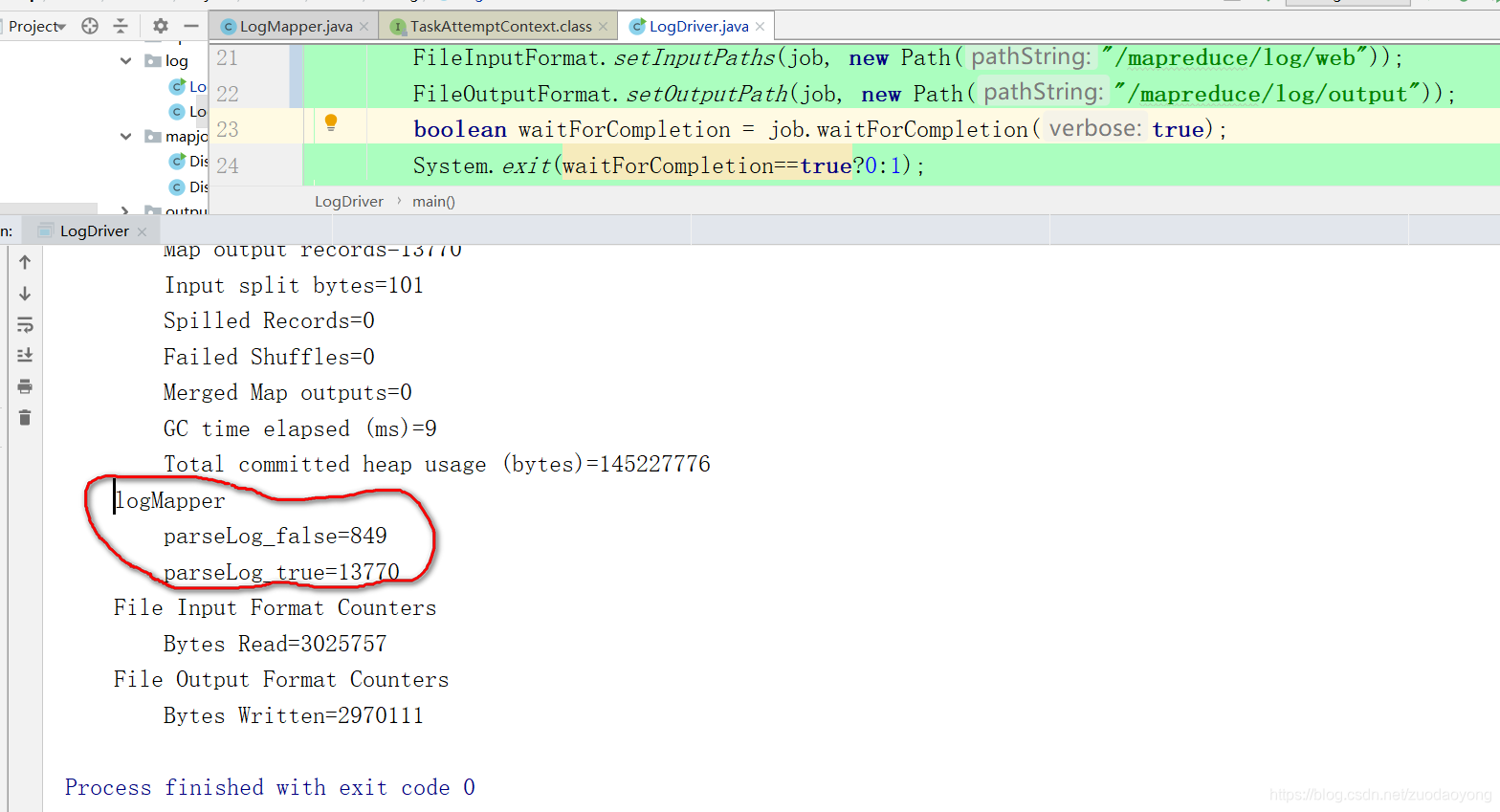
context.getCounter("logMapper","parseLog_true").increment(1);
3、实例
public class LogMapper extends Mapper<LongWritable,Text,Text,NullWritable>{
String[] splits=null;
Text k=new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//获取一行
String line = value.toString();
//解析log
boolean result=parseLog(line,context);
if(!result){
return;
}
k.set(line);
context.write(k, NullWritable.get());
}
private boolean parseLog(String line,Context context) {
splits = line.split("\\s");
if(splits.length>11){
context.getCounter("logMapper","parseLog_true").increment(1);
return true;
}
context.getCounter("logMapper", "parseLog_false").increment(1);
return false;
}
}
public static void main(String[] args) throws Exception{
System.setProperty("HADOOP_USER_NAME", "root");
Configuration configuration=new Configuration();
Job job = Job.getInstance(configuration);
job.setMapperClass(LogMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0);
FileInputFormat.setInputPaths(job, new Path("/mapreduce/log/web"));
FileOutputFormat.setOutputPath(job, new Path("/mapreduce/log/output"));
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion==true?0:1);
}














 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









