







1. 分区表
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
2. 分区表基本操作
1)引入分区表(需要根据日期对日志进行管理,通过部门信息模拟)

2)创建分区表语法
hive (hive3)> create table dept_par(deptno int , dname string, loc string) partitioned by (day string) row format delimited fields terminated by'';
OK
Time taken: 2.547 seconds注意:分区字段不能是表中已经存在的数据,可以将分区字段看作表的伪列。
3)加载数据到分区表中
hive (hive3)> load data local inpath '/home/zzdq/hive/dept_20200401.log' into table dept_par partition(day='20200401');
Loading data to table hive3.dept_par partition (day=20200401)
OK
Time taken: 1.763 seconds
hive (hive3)> load data local inpath '/home/zzdq/hive/dept_20200402.log' into table dept_par partition(day='20200402');
Loading data to table hive3.dept_par partition (day=20200402)
OK
Time taken: 0.962 seconds
hive (hive3)> load data local inpath '/home/zzdq/hive/dept_20200403.log' into table dept_par partition(day='20200403');
Loading data to table hive3.dept_par partition (day=20200403)
OK
Time taken: 0.869 seconds4)查找全部数据(可以看到多了个分区字段,但这个字段不是放在表中,而是放在目录上,所以条件查分区的效率会高很多)
hive (hive3)> select * from dept_par;
OK
dept_par.deptno dept_par.dname dept_par.loc dept_par.day
10 ACCOUNTING 1700 20200401
20 RESEARCH 1800 20200401
30 SALES 1900 20200402
40 OPERATIONS 1700 20200402
50 TEST 2000 20200403
60 DEV 1900 20200403
NULL NULL NULL 20200403
Time taken: 3.684 seconds, Fetched: 7 row(s)5)条件查询
hive (hive3)> select * from dept_par where day = 20200401;
OK
dept_par.deptno dept_par.dname dept_par.loc dept_par.day
10 ACCOUNTING 1700 20200401
20 RESEARCH 1800 20200401
Time taken: 2.749 seconds, Fetched: 2 row(s)另外:分区的信息也存放在mysql的partition表中。
3. 分区的增删改查
单分区查询
hive (default)> select * from dept_partition where day='20200401';多分区联合查询
hive (default)> select * from dept_partition where day='20200401'
union
select * from dept_partition where day='20200402'
union
select * from dept_partition where day='20200403';
hive (default)> select * from dept_partition where day='20200401' or day='20200402' or day='20200403';5)增加分区
创建单个分区
hive (default)> alter table dept_partition add partition(day='20200404');创建多个分区
hive (hive3)> alter table dept_par add partition(day='20200404') partition(day='20200405') partition(day='20200406');
OK
Time taken: 0.844 seconds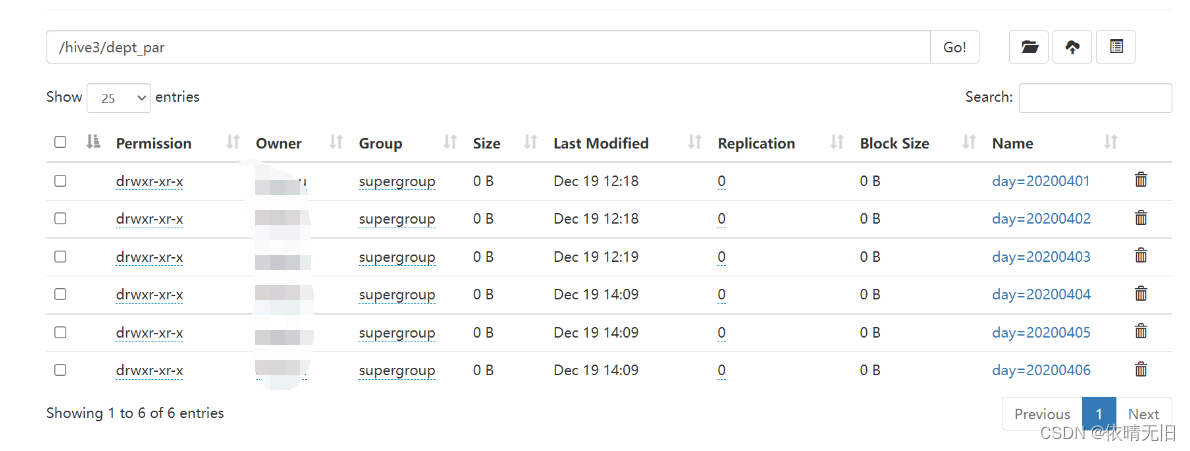
6)删除分区
删除单个分区
hive (default)> alter table dept_partition drop partition (day='20200406');同时删除多个分区
hive (hive3)> alter table dept_par drop partition(day='20200404'),partition(day='20200405'),partition(day='20200406');
Dropped the partition day=20200404
Dropped the partition day=20200405
Dropped the partition day=20200406
OK
Time taken: 0.981 seconds7)查看分区表有多少分区
hive (hive3)> show partitions dept_par;
OK
partition
day=20200401
day=20200402
day=20200403
Time taken: 0.296 seconds, Fetched: 3 row(s)8)查看分区表结构
hive (hive3)> desc formatted dept_par;
# Partition Information
# col_name data_type comment
day string 4. 二级分区
思考: 如何一天的日志数据量也很大,如何再将数据拆分?
1)创建二级分区表
hive (hive3)> create table dept_par2(deptno int , dname string , loc string) partitioned by (day string , hour string) row format delimited fields terminated by '';
OK
Time taken: 0.172 seconds2)正常的加载数据
hive (hive3)> load data local inpath "/home/zzdq/hive/dept_20200401.log" into table dept_par2 partition(day='001',hour='401');
Loading data to table hive3.dept_par2 partition (day=001, hour=401)
OK
Time taken: 1.221 seconds
hive (hive3)> load data local inpath "/home/zzdq/hive/dept_20200402.log" into table dept_par2 partition(day='001',hour='402');
Loading data to table hive3.dept_par2 partition (day=001, hour=402)
OK
Time taken: 0.899 seconds
hive (hive3)> load data local inpath "/home/zzdq/hive/dept_20200403.log" into table dept_par2 partition(day='001',hour='403');
Loading data to table hive3.dept_par2 partition (day=001, hour=403)
OK
Time taken: 1.011 seconds
hive (hive3)> load data local inpath "/home/zzdq/hive/dept_20200403.log" into table dept_par2 partition(day='002',hour='404');
Loading data to table hive3.dept_par2 partition (day=001, hour=404)
OK
Time taken: 0.878 seconds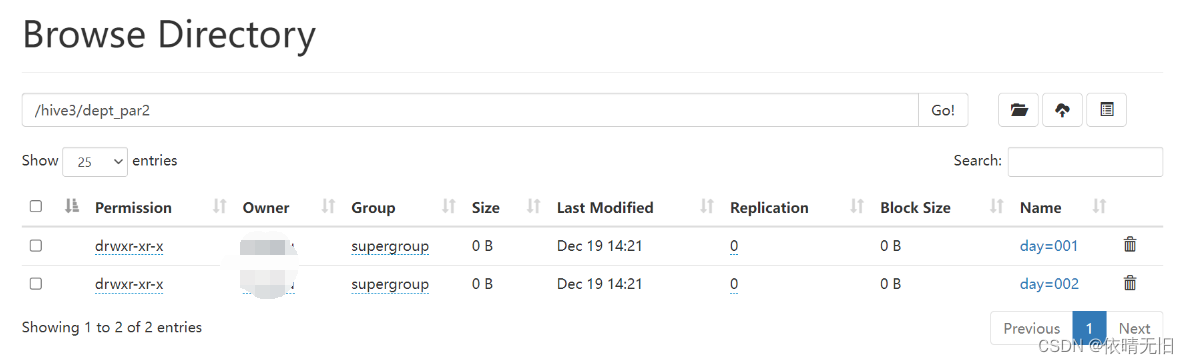
查询
hive (hive3)> select * from dept_par2 where day = '001' and hour = '404';
OK
dept_par2.deptno dept_par2.dname dept_par2.loc dept_par2.day dept_par2.hour
50 TEST 2000 001 404
60 DEV 1900 001 404
NULL NULL NULL 001 404
Time taken: 0.692 seconds, Fetched: 3 row(s)3)把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式
(1)方式一:上传数据后修复
上传数据
hive (default)> dfs -mkdir -p /user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=13;
hive (default)> dfs -put /opt/module/datas/dept1.txt /user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=13;查询数据(查询不到刚上传的数据)
hive (default)> select * from dept_partition2 where day='20200401' and hour='13';让分区信息产生关联的操作:执行修复命令
hive> msck repair table dept_partition2;再次查询数据
hive (default)> select * from dept_partition2 where day='20200401' and hour='13';(2)方式二:上传数据后添加分区
上传数据
hive (default)> dfs -mkdir -p /user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=14;
hive (default)> dfs -put /opt/module/hive/datas/dept_20200401.log /user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=14; 执行添加分区
hive (default)> alter table dept_partition2 add partition(day='201709',hour='14'); 查询数据
hive (default)> select * from dept_partition2 where day='20200401' and hour='14';(3)方式三:创建文件夹后,使用load
load 数据到分区创建目录
hive (default)> dfs -mkdir -p /user/hive/warehouse/mydb.db/dept_partition2/day=20200401/hour=15; 上传数据
hive (default)> load data local inpath '/opt/module/hive/datas/dept_20200401.log' into table dept_partition2 partition(day='20200401',hour='15'); 查询数据
hive (default)> select * from dept_partition2 where day='20200401' and hour='15';5. 动态分区调整
关系型数据库中,对分区表 Insert 数据时候,数据库自动会根据分区字段的值,将数据插入到相应的分区中,Hive 中也提供了类似的机制,即动态分区(Dynamic Partition),只不过,使用 Hive 的动态分区,需要进行相应的配置。
1)开启动态分区参数设置
(1)开启动态分区功能(默认 true,开启)
hive.exec.dynamic.partition=true(2)设置为非严格模式(动态分区的模式,默认 strict,表示必须指定至少一个分区为静态分区,nonstrict 模式表示允许所有的分区字段都可以使用动态分区。)
hive (hive3)> set hive.exec.dynamic.partition.mode=nonstrict;(3)在所有执行 MR 的节点上,最大一共可以创建多少个动态分区。默认1000
hive.exec.max.dynamic.partitions=1000(4)在每个执行 MR 的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。比如:源数据中包含了一年的数据,即 day 字段有365 个值,那么该参数就需要设置成大于365,如果使用默认值100,则会报错。(4)在每个执行 MR 的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。比如:源数据中包含了一年的数据,即 day 字段有365 个值,那么该参数就需要设置成大于365,如果使用默认值100,则会报错。
hive.exec.max.dynamic.partitions.pernode=100(5)整个 MR Job 中,最大可以创建多少个 HDFS 文件。默认100000
hive.exec.max.created.files=100000(6)当有空分区生成时,是否抛出异常。一般不需要设置。默认 false
hive.error.on.empty.partition=false2)案例实操
需求:将 dept 表中的数据按照地区(loc 字段),插入到目标表 dept_partition 的相应分区中。
(1)创建目标分区表
hive (hive3)> create table dept_no_par(dname string, loc string) partitioned by (deptno int) row format delimited fields terminated by '';
OK
Time taken: 0.185 seconds(2)设置动态分区
hive (hive3)> set hive.exec.dynamic.partition.mode=nonstrict;(3)导入数据
hive (hive3)>insert into table dept_no_par partition(deptno) select dname,loc,deptno from dept;
OK
Time taken: 0.062 seconds
Query ID = atguigu_20211219145313_ad874c4a-da69-43f2-a0bb-6e0e9ea0ce6c
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2021-12-19 14:53:33,924 Stage-1 map = 0%, reduce = 0%
2021-12-19 14:53:41,638 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.93 sec
2021-12-19 14:53:51,240 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.7 sec
MapReduce Total cumulative CPU time: 4 seconds 700 msec
Ended Job = job_1639880318289_0007
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.7 sec HDFS Read: 14680 HDFS Write: 773 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 700 msec
OK
dname loc deptno
Time taken: 42.654 seconds(4)查看目标分区表的分区情况
hive (hive3)> show partitions dept_no_par;
OK
partition
deptno=10
deptno=20
deptno=30
deptno=40
deptno=70
Time taken: 0.39 seconds, Fetched: 5 row(s)动态分区也可以这么写(3.0新增):
hive (hive3)> create table dept_no_par2(dname string, loc string) partitioned by (deptno int) row format delimited fields terminated by '';
OK
Time taken: 0.188 seconds
hive (hive3)> insert into table dept_no_par2 select dname,loc,deptno from dept;
hive (hive3)> show partitions dept_no_par2;
OK
partition
deptno=10
deptno=20
deptno=30
deptno=40
Time taken: 0.137 seconds, Fetched: 4 row(s)














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









