







导读:本文源自风控技术专家、AI技术专家和算法专家梅子行老师知乎专栏的大数据风控答疑文档,有关大数据风控的问题都在这里了。
作者:梅子行
https://zhuanlan.zhihu.com/p/77095933

1. 芝麻信用分的主要计算维度?
答:主要维度
个人属性:职业类型、学历学籍等
稳定性:手机稳定性、地址稳定性、账户活跃时长等
资产状况:账户资产、有无住房、有无车辆
消费能力:消费金额、消费层次、消费场景丰富度
社交情况:人脉圈信用度、社交广度、社交深度
信用历史情况:信用历史时长、信用履约记录数、信用履约场景、公共事业缴费记录
违约历史情况:违约场景数
2. 如果用borderline_smote会不会导致某一箱内坏的比例过大呀 ?
答:应该是badrate越高的箱插的越多,从而差异最大化
3. 有什么好的模型调参的方法么?网格搜索?贝叶斯优化?
答:课上讲过的,offks + (offks - devks) * 0.8 最大化。这个0.8自己来调整,看你是希望跨时间验证集上的KS更高,还是希望模型更稳定。然后模型内部的参数搜索建议贝叶斯优化,推荐原因是因为快一点。精度其实差别不大。然后精细化调参,一般都是千分位上的提升。
4. U型特征怎么转化为单调?
答:转化成中值差值的绝对值。
5. 什么是baviar图?
答:横轴特征升序,纵轴badrate

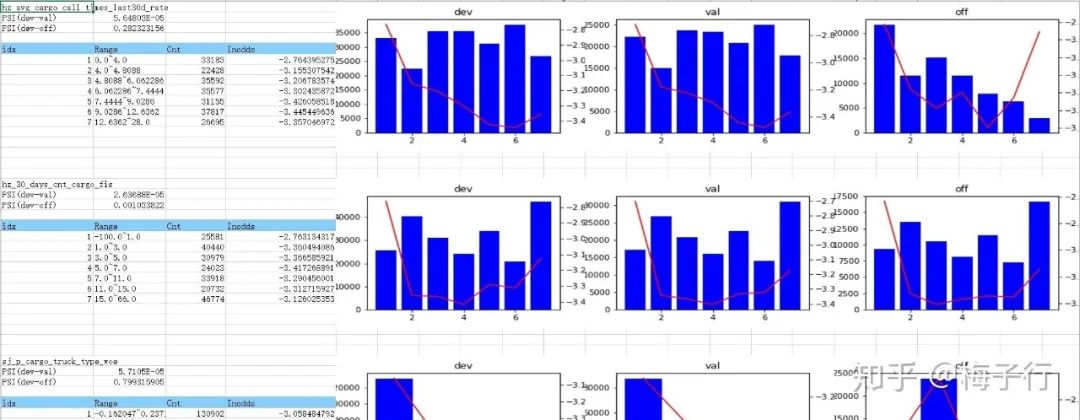
6. 过采样怎么做效果才会好?
答:数据集清洗了嘛,还有特征呈线性了嘛,这两个不满足过采样很难保证效果的,通常xgboost不保证线性也行,但是要用smote最好做一下。
7. 什么我们做评分卡的时候要用woe编码,而不是用别的编码方式呢?比如onehot之类的,仅仅是因为woe可以把特征从非线性变成线性的吗?
答:因为onehot后高维稀疏,模型学习是有困难的。一般模型会做embedding,但是做了embedding就不可解释了。所以用woe来代替。
8. 深度学习的风控模型,从经验上看,样本量大概要多少条啊
答:不同的模型不一样,而且也不光要注意样本量,比如RNN其实希望序列长度至少在12个月以上,粗略的说,样本量五十万以上效果比较好
9. 分箱后,各箱badrate单调递增从业务上怎么理解呀?
答:我们有个先验知识,多头越多badrate越大,历史逾期越多badrate越大...等等,如果变量分箱后不符合这个先验,可能就把他剃掉了。
10. 我这更换了数据源 现在有标签的样本只有一万过条 有什么方法建议的吗?
答:一般先建议做一下过采样,负样本均衡一下
11. 5万正样本,200负样本,B卡,不只是提高额度,会拒绝一部分客户,怎么建模?
答:5万负样本是没有做下采样的必要的,200正样本无论用什么方法做过采样说实话由于自身携带的信息量比较少,学习的应该也不是完全的。
所以这时候建议先略作改动,评价函数加一项,负样本的召回率,也就是说这时候不是主要关注KS,而是对负样本究竟能抓到多少,然后负样本学习的时候一定要加权,权重就按照sklearn中逻辑回归默认的balanced方法就ok,而且如果是我可能生成一个决策树,把坏账从0.4%下降到0.12%左右我觉得就蛮好的了。
12. leader 给我的任务是对短信打标签,也就是判断出短信属于的标签是哪一类,这样一个任务是提取文本关键词的任务吧?
答:我建议先确定每个词对每个类别的贡献度。简单来做就是每种类别找几个词,手动划分一下有这个词,就属于这个类别。复杂一点来做,就训练个模型,确定每个词对每种类别的贡献度,然后对每条记录做个预测,排名前几的标签都给他。
13. 那简单的除了您之前说的那种统计坏的词,然后正则匹配的还有其他的吗?leader 之前说拿到词的重要度,是在整个语料中的一个重要度的话,tf-idf 是不可行的,现在要出一个版本的话,您有什么建议吗?
答:是这样的啊,你们首先需要每篇文档的标签,然后去找词的重要度,不然只能拍脑袋呀 。
然后想知道每篇文档的标签,你们可以先用之前的方法挑选一些特别明显的词 。给文档打标签。然后这样迭代着做。
14. 请问欺诈标签如何定义?
答:反欺诈的千古难题。现在使用的方法:外部黑名单,客服的反馈,明显坏的行为(例如贷款逾期M3+。通讯录造假) ,根据已有标签进行染色,负样本上聚类(已有标签明显多的一类)
无花果童鞋提供的答案:

15. 最近面试数据分析师岗位,和算法岗有什么不一样么?会提到数据敏感,究竟应该怎么回答?
答:区别是分析师是业务+报表+算法,工程师是业务+算法+工程。数据敏感是玄学,关键要知道数据怎么分析,你告诉他,数据要对比着分析,随便拿出一个值就知道这个值是什么水平还是比较困难的。
比如我们分析模型表现,分析变量稳定性。不是给出一个月份的分布我们就知道模型好不好,而是要两个月作对比才知道。
16. 想问一下,现在公司是不是先准入规则,然后再进入一个pre-A模型,然后再是反欺诈模型,然后是A卡之类的?
答:可以理解成模型是嵌在规则里面的,规则到处都有。
17. 梅老师,就是你说准入规则,pre-A, 反欺诈规则反欺诈引擎,还有风控模型,一般都不会选用相同的特征?因为客户群体会越来越少,这个我有点不理解......
答:这个问题不只有一个同学问过我。也是不单单我们这个场景才有的。基本上每个机器学习模型或多或少都会遇到我们这种问题。我们一般是不会用相同的特征做重复筛选的。这样会导致样本偏移更严重。
就是说,被拒绝的人,是由于某些特征表现差,被拒绝的,那随着时间推移,下次建模的样本里面,就没有这些人了...这些这些特征上的样本分布就变了。
18. 我看之前逻辑评分卡 ,评分转化的部分 ,ln(odds) =X*beta+intercept
但是我看您写的转换没有考虑常数项,行业内都是这么做的么,不考虑常数项?
答:我记得代码里面有一项应该把他平衡掉了,那个公式的目的其实是,()中的那一项决定等于基础分的概率值,()的系数决定步长,()+决定基础分等于多少
19. 用三种标签学出来的三个模型,从三个维度给一个人的欺诈风险打分,怎么给这三个模型进行融合,因为单个用户申请线上预测,无法根据客户在各个模型排名取平均。但这三个模型的输出的概率区间又是不同的,比如模型A的输出区间是[0-0.4],模型B输出区间[0-0.9],也不是正态分布,zscore标准化不能用,只能MinMax先进行标准化?再进行分数融合?
答:对的,一般要minmax,规约到一样的范围内
20. 请问梅老师,使用BiLSTM 对用户行为进行建模时,神经网络的输入层是什么?输出层是什么?怎么把用户行为数据转换成神经网络输入层的向量?
答:打个比方啊,额度使用率按照月份的时间序列就是,前0-30天的额度使用率,前30-60的额度使用率,前60-90的额度使用率...变成一个列向量。有多少特征(额度使用率是一个特征)就有多少个列向量。然后输入层就是这些列向量,输出层一般就是用户的标签。最终可以把输出的score丢进逻辑回归,或者把中间测参数拿出来也可以。
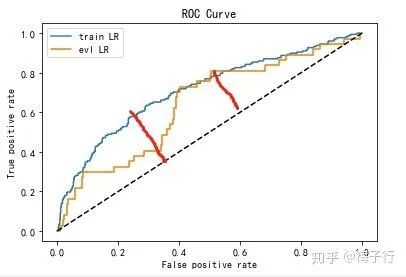
21. 在ks上训练集和测试集相差不大,但在auc上却相差较大,这是为啥?
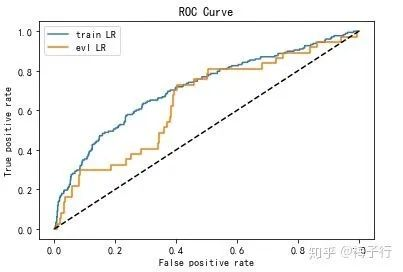
答:下图是KS的差距,两者差不多,曲面面积可以理解成是AUC的差距,差的就很多了。
22. 在xgboost或者lightgbm建模之前是否进行相关性处理,去掉相关性较高的变量?
答:要的。lr中我们是为了对向量空间描述的最好。在xgb主要是想去掉相互替代性较强的特征。
比如一个特征给他找相关性特别强的9个特征放在模型里面,存成不同的名字,你会发现他本来重要性是10,每划分一次,一个特征就比另一个好用那么一点,这么弄了之后十个特征的重要性都变成了1,然后被我们用feature_importance>5给筛掉了......这多尴尬
23. 在评分卡上线以后。进行监控的时候,监控的周期是多少,是将新数据下载到本地来计算ks、psi以及变量稳定性等这些指标吗?
答:一般有日报周报月报,看客群量大的话,周期可以短一点,量少的话,计算指标没什么意义
24. 请问梅老师,怎么样才能具备招聘中所反欺诈岗位所要求的?

答:归纳一下就是,要明确欺诈的定义,使用数据分析方法,对接第三方数据。
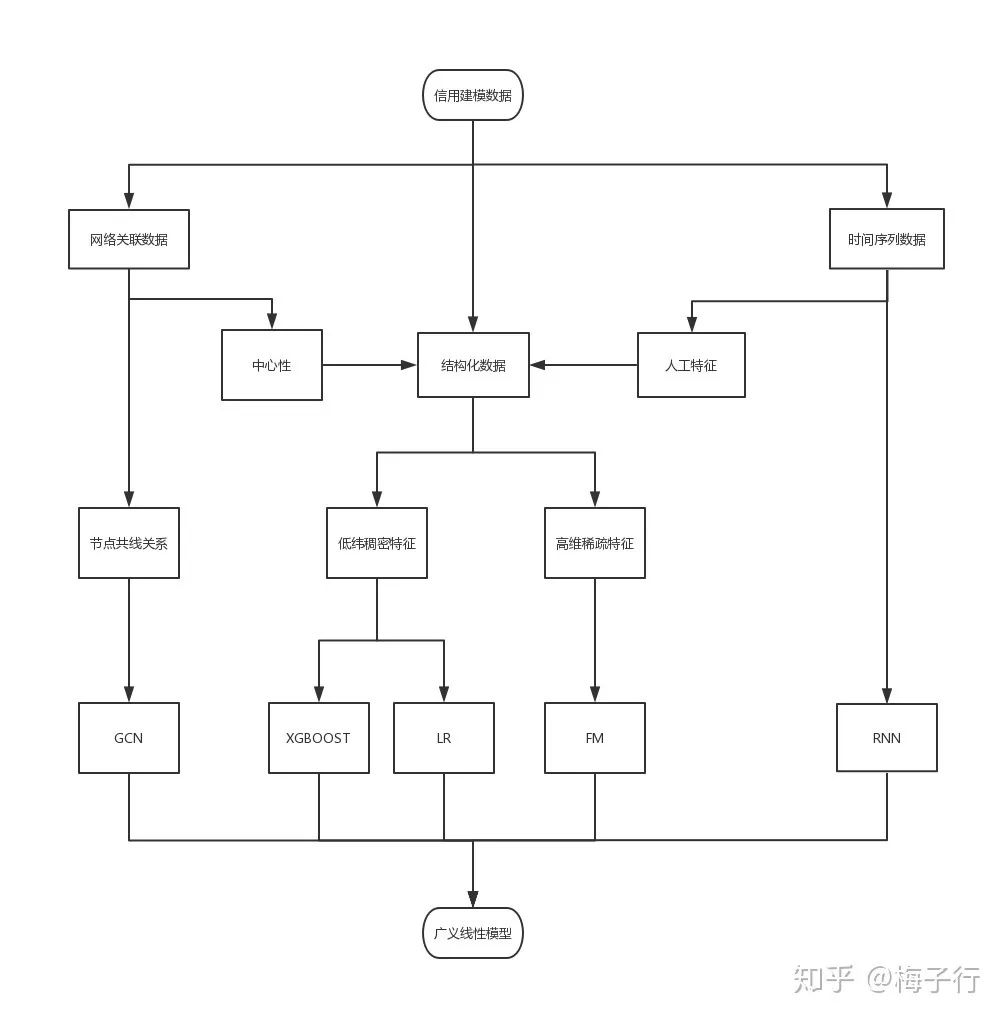
25. 想了解下金融风控的架构知识,能不能发点资料学习下
答:见思维导图
26. 关于xgboost使用泰勒展开式的优点?泰勒展开取得函数做自变量的二阶导数形式, 可以在不选定损失函数具体形式的情况下, 仅仅依靠输入数据的值就可以进行叶子分裂优化计算, 本质上也就把损失函数的选取和模型算法优化/参数选择分开了. 请问为什么在 可以在不选定损失函数具体形式的情况下, 仅仅依靠输入数据的值就可以进行叶子分裂优化计算?
答:下图中,g和h都是和损失函数有关的,所以不可能完全不考虑损失函数,这个表述是错误的。
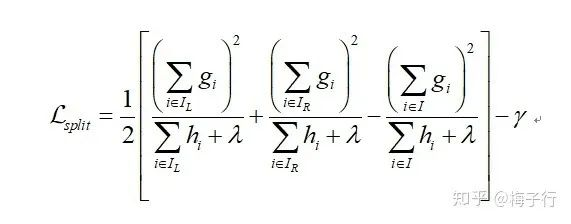
27. 不平衡场景下的过采样(朴素、SMOTE)后训练的模型都需要结果概率校正吧?如何操作?
答:只有单个模型不需要做校正,如何需要和其他模型做融合或者做比较的时候可以做
28. 请问回归决策树针对离散变量使用,是否先转成one-hot?否则1)如果是没转码的字符变量。直接报错2)如果转成数值。就会把我们的编码,当做连续变量进行回归处理?
答:正常是要做onehot,但是特征高纬稀疏,还需要做embedding,这样就没有解释性了,所以个人建议可以做WOE,或者按照每个取值的badrate做一个排序然后labelencoder
29. 梅老师,有个问题想请教您一下。比如说在建模的时候,有一个特征是性别,我是应该在男和女情况下建立两个模型 还是 将性别放进x里建立一个模型
答:个人一般都是放进x,电商推荐里面男女买的东西不一样所以会拆开,贷款这件事情,差不多吧
30. 对于分期账单,在进行逾期分析的时候,是以每个到期用户的第一期来计算,还是以每个到期用户的最近那个到期来计算,还是按照账单每一期来计算?现在就是出现有些用户,第一期没有逾期,但第二期就会逾期或者不还这种就是把每一期当做一个账单或者一个人,然后进行分析?
答:如果大家都有很多期的话,尽量做每一期的。不是的,每一期当作一个人不太合理,如果想做的严格一点,可以选最大逾期作为标记。
31. 忽然有个问题有点模糊:KS值=max(TPR—FPR)的说法对吗?怎么图形和公式都和上课老师讲的很像,这个公式可以在KS曲线上求出来,通过改变概率阈值。@金融梅老师 请问老师,KS值和KS曲线通过调节概率阈值,得出的KS值是一回事吗?
答:当箱分的足够细的时候应该是一回事,一般箱分的越多KS越大咩
32. 梅老师,计算模型的psi一般用等频分还是等距分?一般分几份?
答:通常都是等频,个人一般分十箱
33. 我lgb在不平衡分类上训练了一个模型,训练集上输出概率分布呈偏态分布(偏向0,好样本),但在测试集上呈近似正态分布。如果设置pos_scale_weight参数,会产生这种情况,如果不设置,测试集上的概率分布还是和训练集类似这种现象正常吗?
答:正常吧,scala pos weight相当于改变了训练集的标签分布,不过我理解,输出概率分布不一样,对排序模型没有影响吧~,只不过和别的模型的分数不能直接比较。
34. 想问一下您,就是做风控的话还需要会一些sql和spark之类的吗
答:sql我理解算法岗都是需要滴,spark不做图谱其实还好,一般也不太需要分布式训练。基本都是在大数据环境里面用dataframe或者sql。hadoop和spark原理属于加分项吧。
35. 梅老师,面试问你们公司的主要业务是什么,我该怎么说?
答:
属于什么类型的贷款产品(现金贷、消费分期等等)
客户一般来自什么渠道,是特定的群体(比如滴水贷只借给滴滴平台的司机),还是面向所有人的(比如常规的p2p公司)
贷款额度、还款周期?
36. 面试问你都负责哪些业务?
答:
准入策略
风控模型
贷后监控
主要是风控模型这块。监控也是必须的,我们要时刻关心模型的通过率和贷后表现是否有异常,警惕欺诈。
37. 面试问讲一讲你模型是怎么做的?
答:确定y如何标记(逾期几天为1,几天为0,每种产品不一样,如果不知道,我建议你说15天为分割点,没什么大问题)。
前期数据准备(数据来自 HIVE?MySQL?MongoDB?Spark?)。
这里就可以接上学过的风控项目。
包括各种算法,建模技巧,基本上都是这里引出的。
38. 你是如何标记客户好坏的?
答:
可以说迁徙率
也可以说逾期天数作为标记好坏的依据
因为本身样本不均衡,会偏向扩充坏人的数量(比如以pd1来标记好坏,坏人肯定比pd15会多很多)
注意很多公司建模的时候,去除一部分灰色客户(比如去掉pd1~pd5的客户)
39. 你做模型时用到了哪些数据源?
答:
征信数据
运营商数据
埋点数据
平台自有数据
用户手填数据
数据有很多,每家都各有不同,小心点也可能问你数据来自哪家平台哦。
ps:见过很多小型公司都喜欢用运营商数据,因为便宜,很多都是免费的。
40. 面试问模型的效果怎么样?
答:
测试集和跨时间验证集的KS和AUC是多少
上线后一个月或者几个月后,模型的KS是多少,AUC是多少
41. 你们模型是怎么部署上线的?
答:我经历过的几种上线方法可以分享给大家。
最简单的,把评分卡每个区间加多少分减多少分,怎么做映射的逻辑,讲给开发小哥,他会帮你在线上写 if else
生成一个pmml文件,给开发小哥调用
公司自己做的决策引擎,或者是租的,自己写变量逻辑上线
用flask或者Django自己写接口上线
42. 梅老师,面试问上线需要注意什么,我该怎么说?
答:线上线下变量的逻辑必须完全一致,这是最重要的。
很多公司会做类似于A\B test,两套模型竞争(一个champion做决策,和一个challenger空跑,也有可能champion 70%,challenger 30%)。
43. xgb变量重要性用哪一个指标?
答:
通常我会直接用weight,他们筛选出的变量略有区别,但是使用下来区别主要在于重要性最低的那几个可以互相替代的特征,具体用谁其实并不重要。经验告诉我们total_gain效果可能会略好。
是的,xgb筛选特征,然后用新的特征建模,但是通常不建议筛选后还用xgb建模,这不符合模型融合的策略。
xgb其实是没法解释的,如果希望有逻辑回归的可解释度,建议相同数据、相同变量,带入lr建立一个陪跑的模型,寻求解释的时候去lr中找原因。特征相同的前提下,不会有太大出入的。
xgb筛选特征可以理解为用均方差最小来做特征筛选,和IV、WOE属于同一种筛选方式,,描述的都是特征对分类任务的贡献度,一般用一个就行了,每个人的方法都不一样,见仁见智。
44. 如果我们做完模型,只是一个人逾期的概率,那不同的人还有不同的额度和手续费,我们直接对最终收益进行建模那多好??最大化收益不就是我们的业务目标么?
答:事实上我们的策略是不停的调整的,如果想计算最终受益,然后建模的话,以后上线了这个模型就必须要固定策略不能变,不然稍一改变,这个模型就不适用了,这显然是不符合我们实际业务的,所以我们都是固定模型,让策略来调整,最终达到一个比较好的收益。
45. 什么是多头借贷?
答:多头借贷,即单个借款人向2家或者2家以上的金融机构提出借贷需求的行为。由于单个用户的偿还能力是有限的,向多方借贷必然蕴含着较高的风险。一般来说,当借贷人出现了多头借贷的情况,说明该借贷人资金需求出现了较大困难,有理由怀疑其还款能力。
46. 模型开发中,one-hot编码好还是哑变量编码好?
答:相比于这俩,woe最好
47. 市面上很多数据机构,特征变量时间用累计的,30天,90天,180天这样累计的,尤其是一些多头申请数据。那这样是不是意味着特征衍生是不够专业或者还存在缺失的。
答:不会,一般这都是他们筛选过后较稳定有效的特征表示形式。
48. 模型的ks和auc有多少可以上线了?一般训练集和测试集之间的ks和auc相差多少算是比较合理的呢?
答:KS至少20%,不然和瞎猜没啥区别。业内都认为训练集和测试集之间的KS相差5个百分点以内才算没有明显过拟合。
49. A和B相关性强,B和C相关性强,这种情况去除哪个变量?
答:去掉VIF最大的或者重要性最低的。
50. 关于缺失值处理。您提到,某些变量不应该处理,标记出来即可,我理解这是针对分类变量。假设类似芝麻分,缺失了60%,但剩下的40%依然能看出KS,这时候除了做是否确实芝麻分的衍生外,也想保留芝麻分的数值型特征,但此时使用中位数,或者平均数,填充,其实都会严重影响 芝麻分的分布。不知道,您是怎么处理的?
答:先搞清楚为什么缺失,通常我们会默认认缺失的属于同一类,如果确认只是随机缺失的话,可以分别尝试一下各种填补看看哪个效果最好,刚刚tom提到的极大似然也可以尝试一下
51. 现在做xgb模型还需要分箱编码嘛?
答:xgb有些做的,比如城市这个变量取值比较多,用woe指定一下分箱,牺牲一些精度来增强鲁棒性。
52. lr那种模型里变量分箱编码以后都是单调齐次的了,树模型并不需要这种性质是不是及时树模型做了分箱也没必要分的很少几个bin弄成单调的,只是分几个箱防止过拟合就可以了?
答:正常是这样的,我之前做过一家是 线上xgb,线下lr,解释性的问题用线下的lr来说明,所以要在xgb前面做bivar,为了保证xgb和lr的变量完全一致的。
53. 基于gini指数的分箱代码可以再分享一次嘛?
答:【链接】python实现连续变量最优分箱--CART算法
https://link.zhihu.com/?target=https%3A//blog.csdn.net/weixin_42097808/article/details/80172824
54. 分箱法的主要目的?
答:由于分箱方法考虑相邻的值,因此是一种局部平滑方法。分箱的主要目的是去噪,将连续数据离散化后,特征会更稳定。
55. 请问类似特征 “近30天通过率”,出现空值的情况应该怎么处理?因为这是因为用户近30天没有申请。补0的话,会和用户有申请但没有通过件这样的情况混淆。补其他值感觉也不符合业务逻辑。
答:这种应该单独赋值的,后面分箱也尽量不要和别的放在别的箱里面
56. 要是公司里做lgb的A卡,我搓出来几千维特征模型重要度都>0,这种模型能用吗?
答:可以用,不过要关注一下稳定性。也见过线上模型变量近千维的
57. 请问无监督做特征选择都有什么方法呀?
答:word2vec,autoencoder
58. 做特征衍生的时候 经常会衍生出不稳定的特征(训练与测试集上分布相差比较大) 有没有什么自动化的方法可以帮助剔除和检验出这些特征呢?
答:单变量PSI值算是最自动化的了,bivar图可能不太自动化,需要你扫一眼。
59. 下探一般要选多少样本进行下探?下探的样本评分很低,但选取哪些呢?
答:按照期望得到的坏客户量进行选择。不知道下探后会收获多少坏样本对不对?上一次模型迭代时候的测试集模拟就派上用场了。用那个百分比作为下探区间的预期百分比,然后去算吧。
60. 训练出来的模型如果出现了误判的情况(假正和假负),应该怎样去让模型学到这部分误判的情况,而后正确的预测呢?一般是怎么操作的呢?
答:算法来说这就是adboost,然后有个东西叫做 bad sample 分析,就是针对错分样本来分析为什么错分。具体百度。
61. 实际分箱过程中如果用等频分箱,怎么使得每箱都有好坏样本,保证后面计算WOE有意义?
答:等频分箱之后,每一箱坏样本占比不同才有趋势呀,主要还是看趋势,也就是说等频分箱后,要在根据好坏样本占比来合并初始的分箱,手动合并的话一般保持单调趋势就行了,自动的话,可以考虑把相邻两箱IV值的差,小于某个阈值则合并为一箱
62. 地址数据具体怎么用比较好?
答:最近好像是提取城市、省份、经纬度,以及房价信息
63. 计算模型的psi一般用等频分还是等距分?一般分几份?
答:通常都是等频,个人一般分十箱
64. 老师,不平衡场景下的过采样(朴素、SMOTE)后训练的模型都需要结果概率校正吧?如何操作?
答:我理解只有单个模型不需要做校正,如何需要和其他模型做融合或者做比较的时候可以做。
【链接】不平衡数据集过(欠)采样后预测概率的调
https://link.zhihu.com/?target=https%3A//blog.csdn.net/nickzzzhu/article/details/83821372
65. feature_importance 和 iv有时候选出的变量差别很大,该以哪个为准,怎么判别
答:个人感觉IV和目标函数的关系更大,但是一半用IV做初筛,iv很低,不用进模型,但是IV是单个变量的作用,而feature_importance有一个特征组合效应在里面。我个人是这么理解的。所以按理也可以推出,不一定是选IV最高的变量组合在一起就一定能够ks最高,而是特征组合在一起综合效应最高的才是KS能够达到最高的。
66. 怎么解决测试集上auc偏低的问题?我这个数据集比较小,训练集有1000个,是前20天,测试集有200多个,是后10天,这个是纯多头数据,原始多头变量120个,自己做衍生变量到7000左右。训练集违约率20%左右,测试集违约率14%左右。
答:太小了,感觉模型学不到什么的,应该不会有太明显的改善的,做个单变量分析看看比现有特征的强弱就可以了。
67. 如果客群风险发生变化,会怎么做?我想的是
1)看变化前后用户特征(重要特征)的分布是否发生变化
2)是不是有欺诈的可能
3)如果以上都不是,是不是需要调整准入规则或者申请模型。
答:对的,一般不是欺诈就是该迭代了
68. 一般在业务中哪种分箱用得更多啊?
答:一般用基于iv或者卡方的自动分箱
69. 现在市面上在金融风控中用的无监督算法都有哪些?
答:主要是基于图的离群检测和聚类,其次还有孤立森林,LOF这种,还有通过聚类进行特征衍生
70. 利用rf看特征的重要性,碰到了类别型的特征,是直接做one_hot处理还是分箱转为woe,或者不参与特征的排序
答:一般woe效果比较好
71. 构建一个申请评分卡需要多长时间,就是从数据库选择数据、拉取数据,到最后生成一个评分卡需要多久,然后部署上线稳定运行又需要多长时间?
答:最慢能一个月,别人给上线得排期,还得慢慢核对变量逻辑,最快能一两天,自己开发自己上线
72. 有30天的放款表现数据,其中有不连续10天的用户逾期率较低,有不连续20天的用户逾期率较高,那么一般是什么原因造成,该怎么找到造成这样的原因?
答:跟业务发生的时间线对一下看看吧,我理解这个是需要分析一下的,可能对完了发现是哪个渠道不好,或者是量比较小导致的偶然现象。
73. 梅老师,AUC计算时的那个threshold是怎么确定的?当时觉得thresholds应该小于1,这里出现了1.8
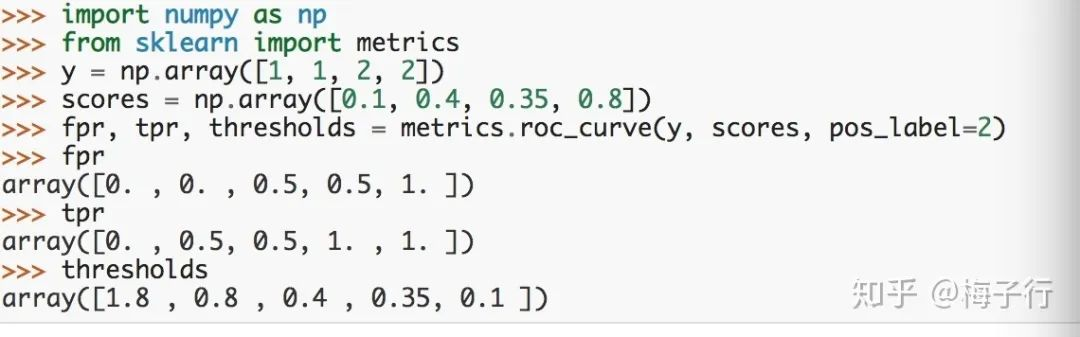
答:y_true:真实的样本标签,默认为{0,1}或者{-1,1}。如果要设置为其它值,则 pos_label 参数要设置为特定值。例如要令样本标签为{1,2},其中2表示正样本,则pos_label=2。把pos_label参数去掉就是默认为1了。
74. 想问下梅老师,进行线性相关性和多重共线性检验的时候,特征是用原始特征还是WOE编码后的特征呢?
答:woe编码后的。
75. 对于评分卡模型,是先特征选择还是先对特征进行分箱处理?对于特征非常多的情况下,分箱的效果也不太好,我就考虑是不是先对特征进行选择再处理呢?
答:是这样的,分箱是单特征之间进行的,和特征多少是否筛选没有关系。
所以你说的应该是单个特征取值特别多的情况下如何进行分箱是么?分箱的时候首先考虑用什么算法。lr必须做分箱,不然鲁棒性会很差。xgboost做了,稳定性上升,准确度下降,有舍有得。lightgbm绝对不要做,直方图算法加上分箱对性能影响比较大。
然后分箱分两种情况,一种是对连续变量做分箱,一种是将字符变量做合并。前期粗分箱通过等频和IV(卡方)进行划分。后期通常根据bivar图来确定。
个人建议,类别变量统一做woe处理。省心效果还好。
76. 对于信贷评分卡模型 数据量一般在多少范围比较合适?
答:首先合适的样本量和预计入模特征数量有关系,模糊的说,可能是5000一档,5万一档,50万一档。5000档以下模型不稳定,负样本通常非常少。5000-5万档模型逐步稳固,特征通常不超过样本的百分之一,lr相应的要用更少的特征。5万到50万感觉提升不明显,更多的是对正样本做下采样,进行均衡学习。50万以上深度学习效果突出。
77. 小微正常过反欺诈,主要考虑哪些?
答:信用风险,行业情况。挺多的,我抛个砖你参考下,发票流水进项,销项 的金额 、频次,和时间以及传统统计指标 做笛卡尔乘积,还有行业指标,区域指标,企业间销售关系,专票循环网络造假骗贷啥的。
78. 我们的模型基本上都是基于样本不均衡的数据的,那么问题就来了,特征工程里不做采样处理的话,样本是极不均衡的,那么做出来的模型有的时候也会失真。
如果做采样的话,那么虽然模型有保证了,但是训练模型的好坏分布并不符合线上的实际好坏分布。这个问题怎么解决呢?
答:我们是把采样权重记录下来,不参与模型训练,只作为计算KS和最终模型模拟时候的权重。然后测试集是没有做采样变换的,所以直接就是真实的
79. 如果采样特征完备性比较好,是不是采样全中就不需要考虑了。或者这个权重怎么把它和ks计算结合起来?
答:因为采样后的训练集这张表长得会不一样嘛,所以会把权重丢进去,就是算样本数量的时候,再乘以一个权重。
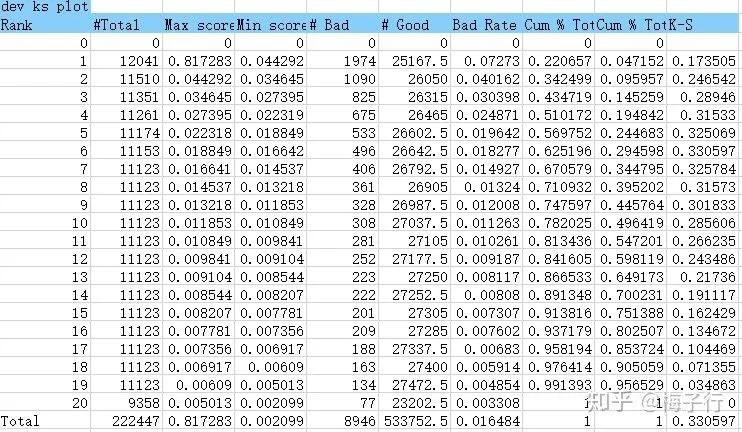
80. 那么ks指标计算,会考虑这个权重吗,还是继续使用采样过后的?
答:训练过程里面,训练集我是没有考虑还原的,只是最终报告里面还原成真实的了
81. neo4j 上线,实时构建图谱的 性能如何?
答:实时性问题基本上可以达到一秒以内一个用户。2亿节点,5亿关系。
82. 梅老师,无监督与xgboost结合的反欺诈模型该如何做?
答:首先聚类,得到每一个簇的聚类中心,然后取出所有的聚类中心,对这些点进行异常值检测(本质是在对簇做异常簇检测)。比如说放进孤立森林中,得到异常值作为整个簇的异常值,带入xgboost进行训练。
83. 想问一下老师,群里面提到的根据业务构造损失函数,能举个例子么?
答:为业务定制损失函数,说起来高级,其实很简单的。假设现在有一个preA模型,用处是拒绝5%的客户,那么他的损失函数也使用AUC,并不能保证捕获率足够大。所以可以改写一个优化捕获率的损失函数,只要保证是凸函数或者满足使用算法的优化条件就行。
# 自定义损失函数需要
def loglikelood(preds, train_data):
labels = train_data.get_label()
preds = 1. / (1. + np.exp(-preds))
grad = preds - labels
hess = preds * (1. - preds)
return grad, hess
# 自定义评估函数
def binary_error(preds, train_data):
labels = train_data.get_label()
dct = pd.DataFrame({'score':preds})
#取百分位点对应的阈值
key = dct['score'].quantile(0.05).values
#按照阈值处理成二分类任务
dct= dct['score'].map(lambda x :1 if x <= key else 0)
return 'error', np.mean(labels != (dct.score> 0.5)), False
gbm = lgb.train(params,
lgb_train,
num_boost_round=10,
init_model=gbm,
fobj=loglikelood,
feval=binary_error,
valid_sets=lgb_eval)84. 催收主要工作就是失联修复,本质上是催收成本与收益的平衡,过程中需要考虑安全与体验性,这样说对吗?
答:催收工作的直接目的是回收逾期账款减少不良产生。长远目的是改变债务人的还款习惯,让债务良性循环。
这里有个前提概念需要清楚的是,信贷本来就是为有还款能力的人提供适当超前消费服务的,并不是为没有还款能力的人应急用的,所以目前的市面上的绝大部分信贷产品的产品设计出发点是有一定偏差的。存在即合理你知道就好,反正一时半会儿也无法改善。
催收成本与收益的平衡和过程的考虑安全性与体验性这句话是没错的。可以这样来理解:催收成本包含了很多,最大一块就是人力成本,解决人力成本是催收的未来出路,所以自动化催收工具及智能催收是市场的主流研究方向,只是现在仍旧处于初级阶段,本质原因是合规问题。
因为样本少,无法通过常规的方法论得到想要的预测结果,这就会导致一个奇怪的现象,每家都有C卡,但是每家C卡的请开给你只对自己的案件有效果,平移同类就没办法保证预测结果,或者随着时间的推移自己的C卡结果都会有很大程度的波动。
这是一个方面,但是说回来如果为了回收账款导致支出过大是完全不可取的。
通常解决办法有两个,一个是用其他的盈利去补贴(一些股份制或者大行有自有催收团队的都会这么做,具体做法很多可以脑补充,可以说只有想不到没有做不到)。
一个是采用外包(这里包含人力外包或系统外包)所谓安全和体验安全是指客户信息数据的安全合规合法、体验是客户体验,因为获取客户的成本很高很贵所以一般银行做法都会有交叉营销或者客户重复利用。典型的如平安。
85. 催收策略是如何设计、优化,具体怎么制定及优化催收策略。策略规则在决策引擎中是怎么测试及部署上线的?
答:我是一直在催收业务线进行工作的,具体策略模型我并没有实际研究过,这里我只能用业务的理解给你解答,仅供参考
催收策略一般都会有2套以上,后台的运作一般都是同时运行,比如进入策略的的案件100个,一般会3:7 或者2:8开,少的部分就是测试,多的部分就是常规。通过产生的两组不同数据进行监控效果,如果少的部分效果比多的部分好和稳定那么就会逐步替代多的部分作为主要运行,如此更迭。算法上决策树和xgboost都是比较常用的办法。
实际就是关键区分指标要找到。举个例子。我们在做经济复苏模型(哪些人在未来会还款)关键指标选择调整的时候有一条对于设备安装APP的种类作为关键指标,我们选择了母婴类APP作为关键区分项效果很好。乍一看感觉和还款没啥关系,但是实际想想不难推测为什么这类人未来还款会很强。
这类APP如果不是刚性需求是没有人会安装的。即使出厂有安装也多半都会被卸载。反过来急然有需求那么一定说明经济状况还不错家庭情况也相对稳定才会考虑哺育后代的。所以这也说明安装这类人的经济情况已经好转。
以上的情况可能比较跳跃但是我想说的是关键的指标调整除了一些常规的什么申请次数之类的也要多想想一些被拆分的很碎的指标的衍生用途。多尝试。
另外我接触比较多的一线的催收人工策略就是诸如什么时候打电话,什么时候发信息,要怎么个频率。以及话术的一些应用的策略,这个没有什么算法,都是通过在线的案件表现和最终的效果进行积累和调整的,这个应该不在你的工作范围中,不过建议有空可以多和一线管理人员交流看到真实的表现这样对你的催收策略调整设计都很有用。
(如何设置规则方法论:市面上常见是通过决策树算法(聚类分析)得出,平衡其触发率和命中率还是要通过风控指标的监控进行调整.)
86. 就是说评分卡做好以后,先在原有基础上等上一段时间,积累一定的数据量,然后再将积累的数据和线下的评分模型比较;那么我上线以后,在通过一些指标监控的时候,什么样的情况下模型变得不好需要重新调整,什么样的情况下模型良好而不需要调整?
答:一般有套完整的监控体系,监控PSI KS capture_rate 超过一定阈值就可以refit或者rebuild了。
87. 怎么更新评分卡或模型,比如通过决策规则获得数据构建评分卡或模型,上线一段时间之后,想更新模型,该用什么数据去建模
答:refit就是用最新的数据来,rebuild就是按照之前的逻辑重新做一次。
关于作者:梅子行,风控技术专家、AI技术专家和算法专家,现就职于满帮科技,负责机器学习在风控领域的算法优化。历任多家知名金融科技公司的风控算法研究员、数据挖掘工程师。师承Experian、Discover等企业的风控专家,擅长深度学习、复杂网络、迁移学习、异常检测等非传统机器学习方法,热衷于数据挖掘以及算法的跨领域优化实践。
延伸阅读《智能风控:原理、算法与工程实践》
推荐语:以当前流行的机器学习模型作为技术线,以信贷业务的风险管控作为场景图,以线带面勾勒出了信贷领域智能风控的最佳实践,是一本贴合当前智能风险管理业务需要的佳作!

有话要说????
Q: 你还有哪些问题要问?
欢迎留言与大家分享
猜你想看????
更多精彩????
在公众号对话框输入以下关键词
查看更多优质内容!
PPT | 读书 | 书单 | 硬核 | 干货
大数据 | 揭秘 | Python | 可视化
AI | 人工智能 | 5G | 中台
机器学习 | 深度学习 | 神经网络
合伙人 | 1024 | 大神 | 数学
据统计,99%的大咖都完成了这个神操作
????




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









