






面对对象3大特性?
封装,继承,多态
封装
概念:
将类的某些信息(属性)隐藏在类的内部,不允许外部对象去直接访问,而是通过该类提供的方法去访问该信息(属性)。
好处:
a.只能通过规定的方法访问数据
b.隐藏类的实例细节,方便修改和实现
3、封装的实现步骤
①修改属性的可见性——设为private
②创建getter/setter方法,用于属性的读写
③在getter/setter方法中加入属性控制语句,对属性值的合法性进行判断
public class Person {
private String name; //私有化属性
public String getName() { //提供访问方法
return name;
}
public void setName(String name) {/提供修改方法
this.name = name;
}
}继承
继承是类与类的一种关系,例如:动物和狗的关系,动物是父类(或基类),狗是子类(或派生类)。
要注意的是,在Java中的继承是单继承,也就是说一个儿子只能有一个爸爸
继承的好处:
子类拥有父类的所有属性和方法(private除外)
子类对父类代码的复用
继承的语法规则:
class 子类 extends 父类
class animal {
}
class dog extends animal {
}方法的重写:
1、什么是方法的重写:
如果子类对继承父类的方法不满意,是可以重从写父类继承的方法,当调用时会优先调用子类的方法。
2、语法规则:
返回值类型、方法名、参数类型及个数 都要与从父类继承的方法相同,才叫方法的重写。
继承的初始化顺序:
若创建一个子类对象,系统会先创建父类的属性进行初始化,再调用父类的构造方法,然后再创建子类的属性进行初始化,最后调用子类的构造方法。
多态
多态指对象的多种引用形态,继承是多态的前提
1、引用多态
父类的引用可以指向本类对象 Animal object1=new Animal();
父类的引用可以指向子类对象 Animal object2=new Dog();
注意:子类的引用不可以指向父类对象Dog object3=new Animal();
2、方法多态
创建本类对象时,调用的方法为本类的方法;
创建子类对象时,调用的为方法为子类重写的方法或者继承的方法
注意:本类对象不能调用子类的方法
引用类型转换:
Dog dog=new Dog();
Animal animal=dog(); //向上类型转换:(不存在风险)
Dog dog2=(Dog)animal; //向下类型转换:(存在风险,可能出现数据溢出)
if(animal instenceof Cat){ //用instanceof运算符,来解决引用对象的类型,避免类型转换的安全问题,返回布尔值,来判断animal能否转换为Cat类型
Cat cat=(Cat)animal;
}hashmap put操作具体流程是什么?
1.判断table数组是否存在并且长度大于0,不满足则进行扩容操作
2.获取key的hash值,将key的hashcode值高16位和低16位进行异或操作生成hash值,目的是降低key的碰撞概率。
3.根据key的hash值找到数组对应的下标的node结点
3.1如果结点为空,则创建一个参数为key,value的node结点加入数组
3.2如果结点不为空,则获取头结点,如果头结点是为红黑树则执行红黑树的插入流程。如果头结点是列表,则遍历列表,执行列表插入流程,如果插入后列表长度大于等于8,则将列表转化为红黑树。设置callbacks扩展(LinkedHashMap会通过次扩展方法将node移动到链表尾)
4.检查添加后的链表长度是否大于threshold,如果大于则进行扩容
5.如果node为空,返回null,否则返回原有的oldNode的value值
SpringMVC执行流程
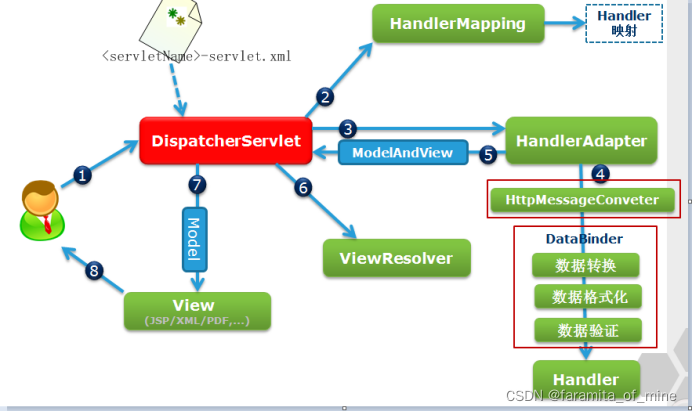
一:发送请求到DispatchServlet(中央控制器)
二:DispatcherServlet(中央控制器)调用HandlerMapping(处理器映射器)根据请求url找到需要执行的处理器(此处做了简化实际返回的是执行链)
三:DispatcherServlet(中央控制器)通过HandlerAdapter(处理器适配器)调用处理器
四:执行处理器,返回ModelAndView给中央控制器
五:中央控制器调用ViewResolver(视图解析器)根据处理器返回的ModelAndView中的逻辑视图名为中央控制器返回一个可用的view实例。
六:中央控制器根据View渲染视图(将模型填充到视图),并响应给用户。
Caffeine和Guava缓存的区别?
caffeine和guava都是通过builder的方式进行初始化操作,生成缓存对象,通过builder的方式可以生产两种缓存对象,LoadingCache(同步填充)和Cache(手动填充),LoadingCache相比于cache可以在get获取的时候如果不存在值,则通过load方法加载数据并返回。
不同点:
guava初始化重写的load方法不能返回null值,而caffeine可以。
caffeine支持异步加载的方式进行数据的加载,在特定场景可以提高性能。
guava和caffeine都支持通过两种策略来进行数据回收,expireAfterWrite、expireAfterAccess,缓存数据都是惰性删除,在get的时候去进行判断是否过期。
不同点:
caffeine还支持通过设置expireAfter参数实现Expiry接口的方法来自定义过期策略
caffine通过异步删除旧值,优化了guava通过队列同步移除旧值,减少了过期处理对get性能的影响,并且caffeine使用面向JDK8的ConcurrentHashMap进行数据存储,由于在JDK8中ConcurrentHashMap增加了红黑树,在hash冲突严重时也有良好的可读性
基于大小的驱逐策略,无论caffeine还是guava通过设置过期时间是无法使缓存值从缓存中驱逐出去,只会在指定时间后被新值替代,所以在使用时,必须设置maximumSize,否则有内存泄漏的风险。设置了maximumSize后,guava和caffeine会在get或put时,根据设置的大小进行清除。
不同点:
caffeine采用的是Tiny-LFU实现,guava采用的是LRU算法实现。















 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









