






根据自己学习计划的安排,在期末复习前还打一篇数据结构的博客,打好一下数据结构的基础,寒假数据结构的学习做下铺垫;
对于数据结构的基础语法我还是熟悉一点,毕竟暑假抽出了一点时间来学习数据结构,只是当时不知道要怎么敲代码,所以数据结构这块就没怎么敲过代码,唯一的一次还是照着别人的代码敲的,当时不知道什么原因,反正对于那些节点,next的理解有些阻碍吧。因为这个原因,这次准备实践一次数据结构代码,我还特意把c语言关于结构体,tepedef,exit,等一些内容又来了一波比较系统的学习(抄书,还是抄c primer plus,尴尬吧);关于结构体的博客,这几天也会打出来的。不说闲话了,进入主题;
关于学习数据结构前的预备知识;
一;编写代码时的准备;
1;先说一下typedef和#define;
1.1;
#define通过宏定义用一个符号常量来表示一个结构体类型;
#define STUDENT struct student
STUDENT {
int date;
....
....
};1.2;
用typedef定义新类型名来代替已有类型名,即给已有类型重新命名;
一般格式为;typedef 已有类型 新类型名;
typedef int Elem;
typedef struct{
int date;
.....
.....
}STUDENT;
STUDENT stu1,stu2;1.3;这两个代替在数据结构中的意义;
这两个的用在数据结构中的意义就是提高程序的灵活性,以及可读性;
看后面代码的实例;
typedef int Elem ;//使用typedef来代替
typedef struct node
{
Elem data;
struct node * next;
}ListNode;
Elem可以来提高程序的灵活性,如果节点的数据域类型改变,只需改变这里和输入输出即可,其他都不需要做改动;
ListNode就是提高程序的可读性和简洁性,用ListNode代替了struct node,大大减少了编写代码的量;2;malloc()函数和free()函数;
malloc()函数的作用就是动态分配内存;
介绍;
malloc 向系统申请分配指定size个字节的内存空间。
返回类型是 void* 类型。void* 表示未确定类型的指针。C,C++规定,void* 类型可以通过类型转换强制转换为任何其它类型的指针;
头文件为;#include
总结;
1;malloc只分配内存不初始化值,
2;注意malloc分配内存后,要来个判断是否成功分配;
3;malloc返回的指针需要强制转化;
4;malloc和free是配对使用的;
5;free之后,要将那指针指向NULL;3;exit()和return()
exit(1);表示进程非正常退出,
exit(0);表示进程正常退出;
头文件为;#include
//关于节点的表示方法;
typedef int Elem ;//使用typedef来代替
typedef struct node//表示节点的内容;
{
Elem data;//数据域;
struct node * next;//指针域,指向他后面的那个节点,到达连接作用
}ListNode;3;创建链表;
声明一个头结点,就是相当于完成节点的建立。
ListNode head;//只需声明一个头结点即可,4;对节点初始化,就是将输入的数据已链表的形式创建起来;有两种创建的方法;
main方法里面;
printf("输入初始化节点个数\n");
scanf("%d",&n);
creat1(&head, n);
//creat2(&head, n);4.1;头插法;
//头插法创建链表; 接下来的节点都是直接插到head后面,其余之前创建的节点之前;因此会改变顺序;
//这里的s是没有变化的,始终指向的是刚创建的节点,达到头插法的目的;
//}
void creat2(struct node * s, int num)//用结构体指针指向head,达到通过s来创建链表;
{
if(num <= 0)
{
printf("输入的节点数不对\n");
exit(1);
}
struct node * p, *p1;
int i;
p = (struct node *)malloc(sizeof(struct node));//先创建第一个节点;并赋值;
if(p == NULL)
{
exit(1);
}
scanf("%d",&p->data);
p->next = NULL;//最后一个节点的next要为NULL;
s->next = p;//将创建并赋值的节点p连接到head上。
for(i = 1; i <= num-1; i++)//相同操作,创建节点赋值连接到head后面,只是每个新节点都直接放到head后面,
{
p1 = (struct node *)malloc(sizeof(struct node));
if(p1 == NULL)
{
printf("未正常分配内存");
exit(1);
}
scanf("%d",&p1->data);
p1->next = p;//新创建的节点next指向前一个建立的节点;
s->next = p1;//head的next指向新创建的节点,
p = p1;//把新创建的节点变成下一个要创建节点的前一个节点;
}
//这里的最后节点next赋值NULL只能放到最前面赋值,因为第一个创建的节点就是链表最后一个节点;
}4.2;尾插法;
//尾插法创建链表; 接下来的节点是按顺序依次接到前个节点的后;
//这里s的作用是移动,每次都是指向刚创建完的节点,也就是指向即将创建的节点的前一个节点,尾连接的目的
void creat1(struct node * s, int num)//用结构体指针指向head,达到通过s来创建链表;
{
if(num <= 0)
{
printf("输入的节点数不对\n");
exit(1);
}
struct node * p;
int i;
for(i = 1; i <= num; i++)
{
p = (struct node *)malloc(sizeof(struct node));
if(p == NULL)//注意不能丢,使用malloc就要判断是否成功;
{
exit(1);
}
scanf("%d",&p->data);
s->next = p;//将s的next执行刚创建的节点;达到连接节点的作用
s = p;//s执行刚创建的节点;
}
s->next = NULL;//表示最后一个节点的next指向NULL。
}5;链表的遍历输出;
main方法里面;
printf("原链表节点\n");
print(&head,n);
//依次遍历链表并输出;
void print(const struct node *s,int n)
{
int i;
for(i = 1; i <= n; i++)//遍历;
{
s = s->next;//移动指针进行遍历输出;
printf("第%d节点数据域为%d\n",i, s->data);
}
}6;关于对链表节点查询;有两种一个是对值的查询,一个是对节点序号的查询;
6.1;
main方法里面的;
/* 测试按值查找
printf("输入要查找的值\n");
scanf("%d",&data1);
getdata(&head,data1);
*/
//按值查找链表;
void getdata(const struct node * s , Elem data1)
{
int k = 0,flag = 0;
while(s->next != NULL)//遍历链表,到最后一个节点NULL
{
s = s->next;
k++;
if(s->data == data1)//进行比较查找
{
flag = 1;
printf("%d ",k);
}
}
if(flag == 0)
{
printf("在该链表中没有找到%d",data1);
}
printf("\n");
}6.2;
//main方法里面的
/* 测试返回第num个节点的数据域;
printf("输入要查找数据域节点的标号\n");
scanf("%d",&num);
getlocate(&head,num);
*/
//输出某个节点的数据域;
void getlocate(const struct node *s, int num)
{
if(num <= 0 || num > getlen(s))
{
printf("输入的节点数不对\n");
exit(1);
}
int i;
for(i = 1; i <= num; i++)//遍历到,是s指向第num个节点;
{
s = s->next;
}
printf("该链表的第%d的节点的数据域为%d\n",num,s->data);
} 7,返回链表长度;
调用的方法;
getlen(&head);
//计算链表的长度;
//指针s是变化的,遍历整个链表,链表结束的标志就是最后一个节点的next为NULL;
int getlen(const struct node * s)
{
int num = 0;
while(s->next != NULL)//遍历;
{
s = s->next;
num++;
}
return num;
}8;删除节点的操作;
8.1;
main方法里面;
/*验证删除函数;delete1(&head,num);
printf("输入要删除节点的节点号\n");
scanf("%d",&bh1);
delet1(&head,bh1);
printf("删除第%d个节点后的链表\n",bh1);
print(&head,n-1);
*/
//删除链表的第num个节点;
//指针s是变化的,最初是指向head的,后面指向num节点前的一个节点,
void delet1(struct node * s, int num)
{
if(num <= 0 || num > getlen(s))
{
printf("输入的节点数不对\n");
exit(1);
}
struct node *p1;
int i;
for(i = 1; i <= num-1; i++)//遍历s指向第num节点的前一个节点
{
s = s->next;
}
p1 = s->next;//将要p1指向要删除的节点,为后续释放空间做准备;
s->next = s->next->next;//到达删除目的,删除节点前的节点的next指向删除节点后的节点;
free(p1);//释放空间。
}8.2;删除一段节点
main函数中;
/*测试删除一段节点的函数
printf("输出要删除的节点区域\n");
scanf("%d %d",&st,&end);
delet2(&head,st,end);
printf("输出删除节点后的链表\n");
print(&head,n-(end-st));
*/
//删除一段区间的节点;从num1到num2,包前不包为,删除num1不删除num2;
void delet2(struct node *s, int num1, int num2)
{
ListNode * p, * p1;
int i;
if(num1 > num2)
{
printf("输入的两个节点序号顺序有错\n");
}
pd(s,num1);
pd(s,num2);
for(i = 1; i < num2; i++)
{
if(i == num1)
{
p = s;
}
s = s->next;//先判断再移动;
}
p1 = s->next;
p->next = p1;
}9;插入函数;
main方法里面;
/* 验证插入函数,insert(&head,num);
printf("输入要插入到节点后的节点号\n");
scanf("%d",&bh2);
insert(&head,bh2);
print(&head,n+1);
*/
//在第num个节点后插入节点;
//指针s是变化的,最初是指向head的,后面指向num节点。
void insert(struct node *s, int num)
{
if(num <= 0 || num > getlen(s))
{
printf("输入的节点数不对\n");
exit(1);
}
struct node * p;
int i;
p = (struct node*)malloc(sizeof(struct node));
if(p == NULL)
{
exit(1);
}
printf("输入相对应的节点信息\n");
scanf("%d",&p->data);
for(i = 1; i <= num; i++)
{
s = s->next;
}
//这里两部的先后关系不能乱, 先赋值再指向;
p->next = s->next;//将s->next赋值为p->next,站在s的角度;
s->next = p;//s->next指向p;
} 三;线性表的单循环链表;
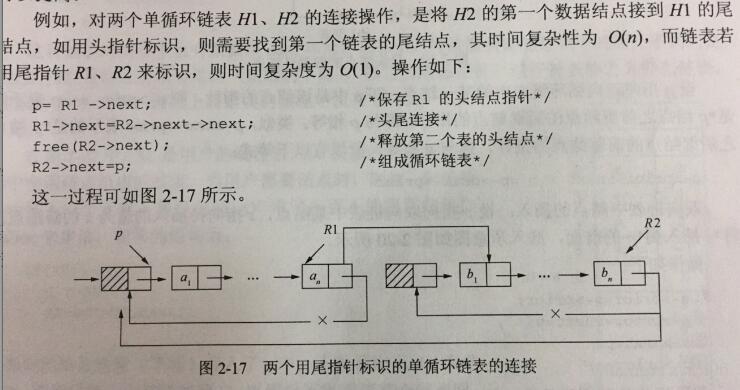
对于单链表而已,最后一个节点的指针是空指针,如果将该链表的表头指针置入该指针域,则使用链表头尾节点相连,就构成了一个单循环链表;意思就是吧最后一个节点的指针域指向头节点;达到循环的目的;
其操作;
在单循环链表上的操作基本上非循环的链表相同,只是将原来判断指针的是否为NULL改为是否为头指针,其余的没什么大变化,
优势;对于单链表只能从头结点开始遍历整个链表,而对于单循环链表则可以从表中任意一个节点开始遍历
整个链表,不仅如此,有时候对链表的操作在表头和表尾的时候,循环链表就是很方便的。
四;双向链表;
双向链表就是有两个指针域,一个指向它的前一个节点,一个指向它后面的后个节点。
定义节点的方式与单链表的唯一不同是有两个指向节点的指针。
typedef int Elem ;//使用typedef来代替
typedef struct node
{
Elem data;
struct node * next, prior;//一个前指针一个后指针,
}ListNode;
其余的操作其实跟单链表的思路差不多,只要是指针修改的时候前后指针都要修改,















 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









