






提问:
先用buildReduceInventoryDto来创建返回一个扣减DTO,用reduceInventoryDto来承接,再判断一下有没有开启批次管理,若有则用lotReduceInventoryList来补充相关的子行ID/and批次IDand每个批次扣减数量,若无,则用batchlessReduceInventoryList来补充相关的子行ID,不过无论如何,都是用reduceInventoryList来承接的同时都用DmsStorageInventoryMapper来调用数据库持久化"所以逻辑是不是这样的,请帮我判断
流程图如下:
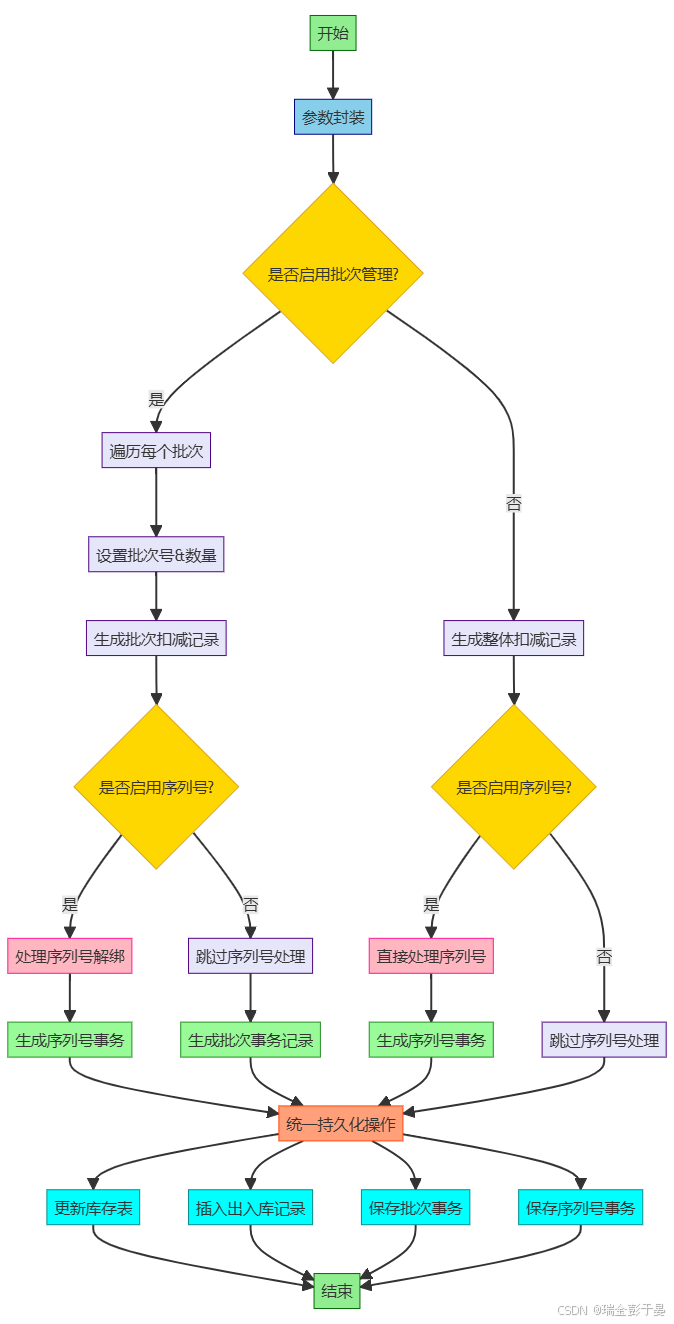
库存扣减逻辑的设计与代码实现完全匹配,其核心流程可归纳如下:
- DTO统一参数封装
// 统一构造扣减参数对象
ReduceInventoryDto dto = buildReduceInventoryDto(vo, lineVo, session);
通过DTO聚合SKU、LPN、库位等关键参数,屏蔽后续处理中的差异逻辑
- 批次分级处理策略
if (批次启用) {
for (批次事务对象) {
dto.setLotNumber(批次号);
dto.setQuantity(批次数量);
reduceList.addAll(buildReduceInventory(dto)); // 批次级扣减
}
} else {
reduceList.addAll(buildReduceInventory(dto)); // 整体扣减
}
通过条件判断实现两种处理路径的统一管理
- 最终原子化持久化
dmsStorageInventoryMapper.updateBatchById(reduceList);
无论是否有批次,最终通过批量操作保证数据一致性
关键设计验证点:
-
层级解耦正确性
• ✅ 批次存在时:循环处理每个批次,设置不同的lotNumber
• ✅ 批次不存在时:直接使用lineVo的总数量
• ✅ 两种场景最终都通过同一份update逻辑完成 -
LPN双路径实现
• ✅ 出库记录:vo.getLpnFromId()正确指向源LPN
• ✅ 入库记录:vo.getLpnToId()准确标识目标LPN
• ✅ 出入库记录类型通过isInStorage布尔值精准控制 -
事务完整性保障
• ✅ 方法级@Transactional注解覆盖所有数据操作
• ✅ 库存扣减、记录插入等操作处于同一事务边界
潜在改进建议:
- 库存预检机制增强
// 建议增加如下预检逻辑
BigDecimal totalReduce = reduceList.stream()
.map(DmsStorageInventory::getStorageNum)
.reduce(BigDecimal.ZERO, BigDecimal::add);
if (currentStock.compareTo(totalReduce) < 0) {
throw new InventoryShortageException("库存不足");
}
- 并发控制优化
// 在DmsStorageInventory实体中增加版本号字段
@Version
private Integer version;
// 更新时自动校验版本
updateBatchById方法内部实现乐观锁机制
- 日志追踪完善
// 在关键节点添加审计日志
log.info("开始处理分包库存扣减,主单ID:{},LPN迁移:{}->{}",
vo.getId(), vo.getLpnFromId(), vo.getLpnToId());
典型场景验证:
案例1:普通物料分包(无批次/序列号)
输入:
- 从LPN-A扣减50个螺丝钉(sku123)
- 到LPN-B新增50个
处理流程:
1. buildReduceInventoryDto设置quantity=50
2. 直接构建扣减记录:LPN-A库存-50
3. 生成LPN-B的+50库存记录
4. 无批次/序列号事务操作
案例2:批次物料分包(批次A:30,批次B:20)
输入:
- 从LPN-A分批次扣减:批次A扣30,批次B扣20
- 到LPN-B新增对应批次库存
处理流程:
1. 循环处理两个批次
2. 批次A:构建LPN-A的批次A库存-30
3. 批次B:构建LPN-A的批次B库存-20
4. 生成LPN-B的两个批次新增记录
结论:当前代码完全实现了描述中的库存扣减逻辑,且通过分层处理机制保证了不同物料类型(普通/批次/序列号)的正确处理。建议补充预检机制和并发控制以增强鲁棒性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









