







 本文详细介绍了如何在Python中使用Selenium和ChromeDriver进行自动化测试,包括检查Chrome版本、下载和配置ChromeDriver、设置环境变量,以及执行完整的爬虫操作,包括登录、高级检索和定制下载选项。
本文详细介绍了如何在Python中使用Selenium和ChromeDriver进行自动化测试,包括检查Chrome版本、下载和配置ChromeDriver、设置环境变量,以及执行完整的爬虫操作,包括登录、高级检索和定制下载选项。
目录
工具准备
Chrome浏览器
如果电脑上没有chrome浏览器或者当前chrome浏览器不是最新版,请先去chrome官网下载安装最新版chrome浏览器
https://www.google.cn/chrome/index.html
ChromeDriver驱动
什么是ChromeDriver
ChromeDriver是一种用于自动化和控制Google Chrome浏览器的工具。它是一个开源的项目,由Google维护,并提供给开发者使用。ChromeDriver充当一个桥梁,允许自动化测试工具或脚本与Chrome浏览器进行交互。
具体来说,ChromeDriver通过与Chrome浏览器通信,执行各种操作,如打开网页、模拟用户输入、获取页面元素等。这对于自动化测试、网页抓取、自动化任务等场景非常有用。
一般来说,如果你想使用Selenium(一个用于自动化测试的工具)来自动化Chrome浏览器,你需要下载并配置ChromeDriver。Selenium将通过ChromeDriver与Chrome浏览器进行通信,从而实现自动化测试脚本的执行。
下载安装
首先,需要检查Chrome浏览器的版本。请按照以下步骤进行:
打开Chrome浏览器后,如下图所示进行操作
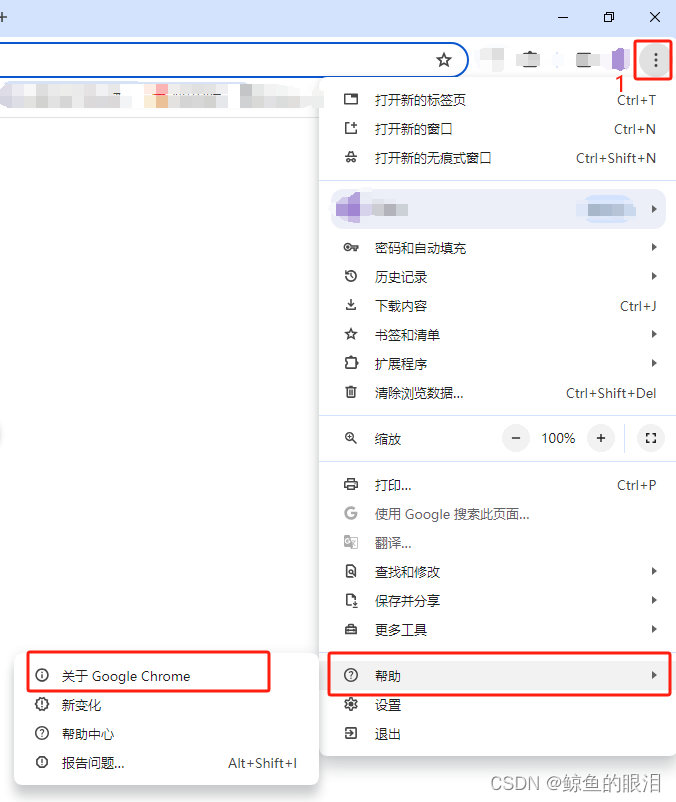
然后就可以看到我们Chrome浏览器的版本了:
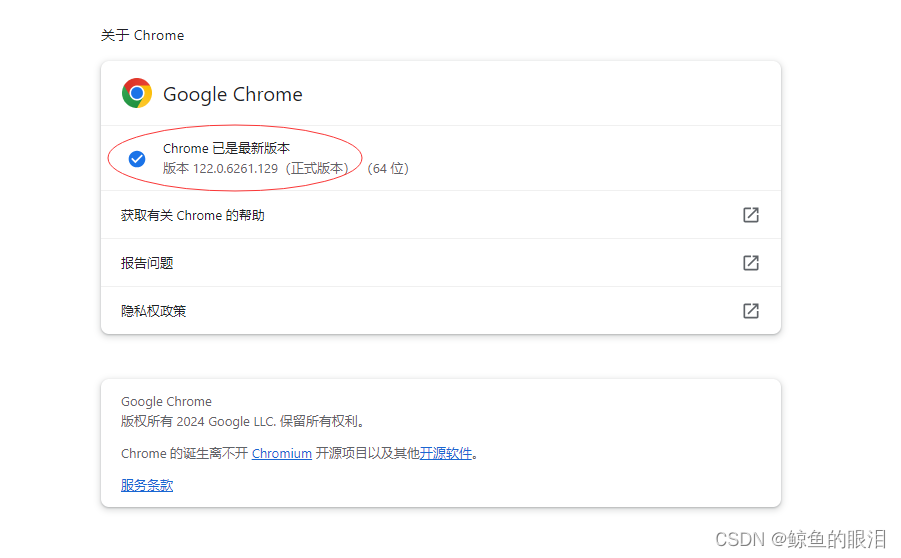
注意:如果你的Chrome浏览器是最新版,一般就不用看了,ChromeDriver也安装最新版即可!!
请记下这个版本号,因为需要确保下载与Chrome浏览器版本相匹配的ChromeDriver
相同版本号只需第一位数字相同即可,比如Chrome版本号是122.0.6261.129,所以ChromeDriver下载版本号122开头的即可
ChromeDriver最新版本链接:https://googlechromelabs.github.io/chrome-for-testing/
打开链接后如下图所示:
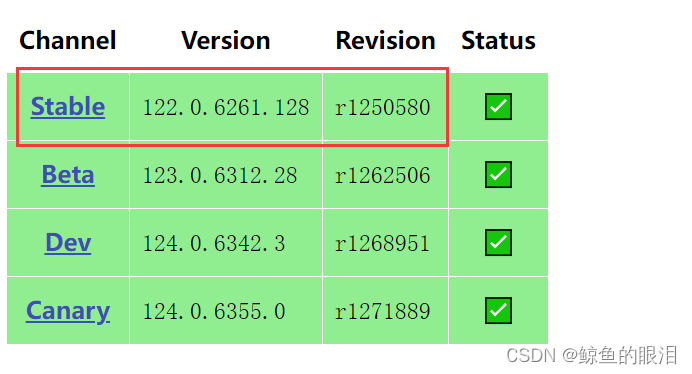

按照自己电脑的系统选择url进行下载
(像我是windows系统,电脑64位的下载win64就行)
实现细节
ChromeDriver下载完成后解压缩,打开
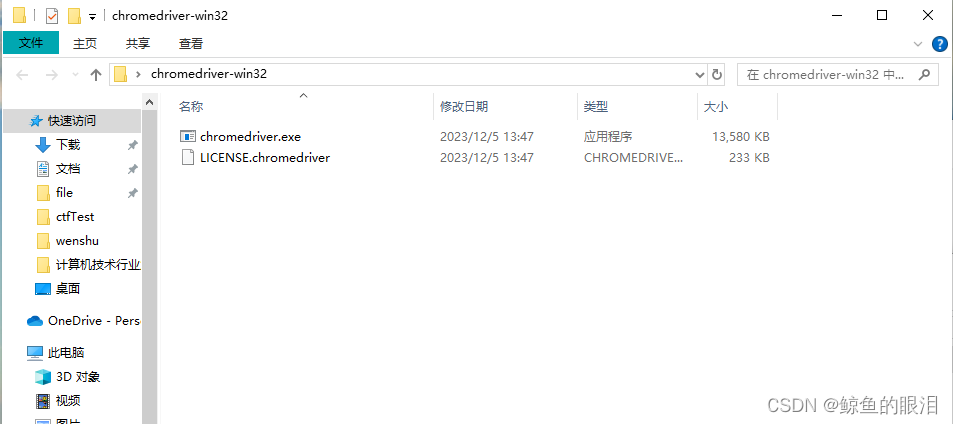
- 我们需要把chromedriver.exe文件复制到chrome的安装路径
如果不记得自己Chrome的安装路径的话,就找到Chrome浏览器的快捷方式,右键->打开文件所在的位置
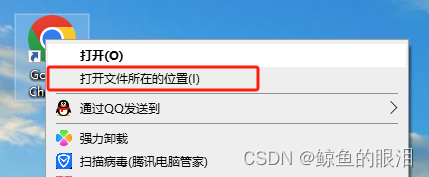
- 如果此时显示的位置Chrome仍是快捷方式不是chrome.exe的话,继续执行右键->打开文件所在的位置
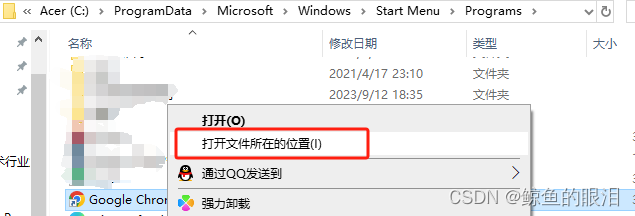
- 然后找到了chrome安装位置,将chromedriver.exe拷贝进来,如下图
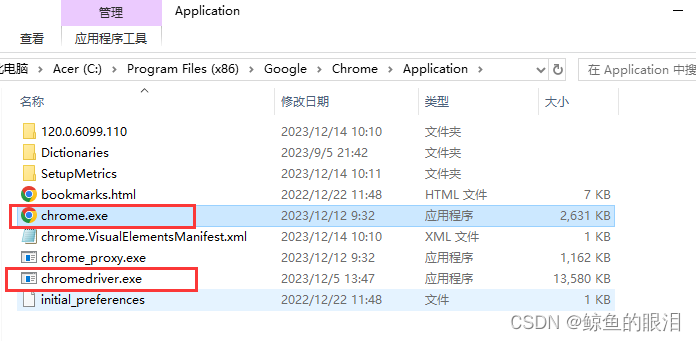
4. 完成复制后,不要急着关闭文件夹,复制一下当前文件路径,也就是chrome.exe的所在路径,后面会用到,比如:C:\Program Files (x86)\Google\Chrome\Application(系统默认安装位置)
环境变量配置
这一步非常关键!!
- 在桌面找到此电脑图标,右键–>属性,然后找到高级系统设置
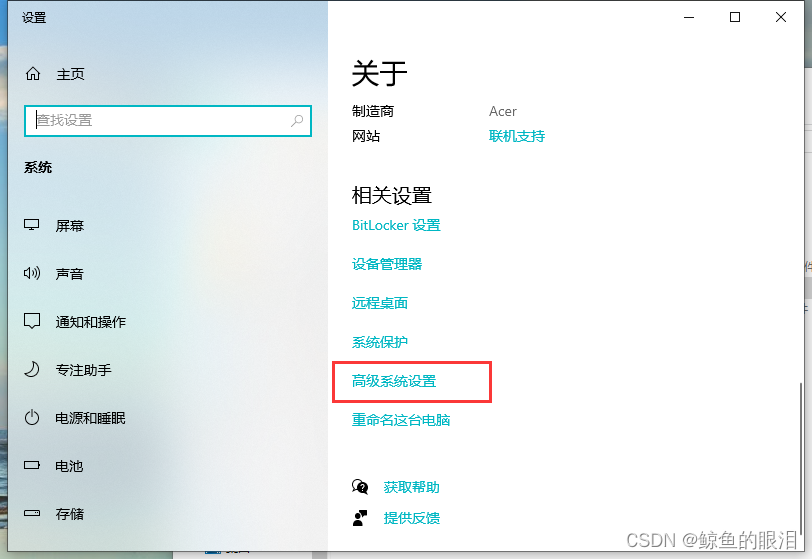
- 然后点击环境变量
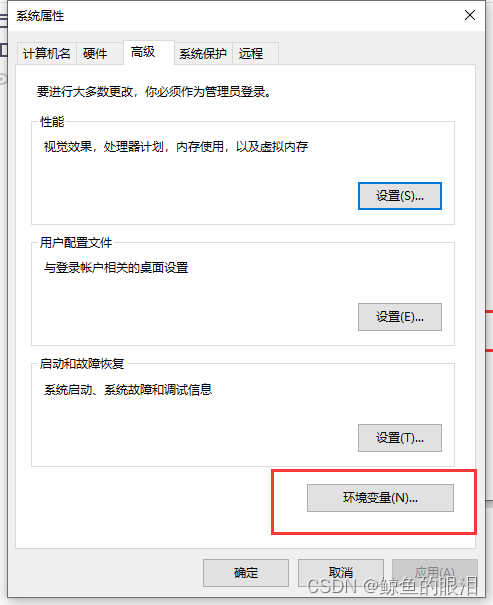
- 在用户变量中找到Path变量,选中path变量后点击编辑

- 点击新建按钮,然后把刚才复制的chrome.exe的路径位置粘贴到此处,如下图所示:
.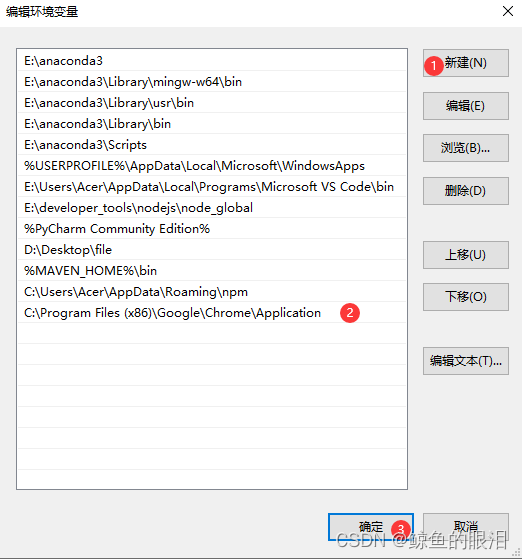
- 然后切记:退出时有确定键一直选择”确定“键才能使保存生效
Python库安装
- 将代码拷贝到Pycharm编辑器中,选择好自己的Python环境(关于如何配置Python环境如果大家不会的话就自行百度一下,网上很多教程)
- 如果看到如下图所示的selenium爆红
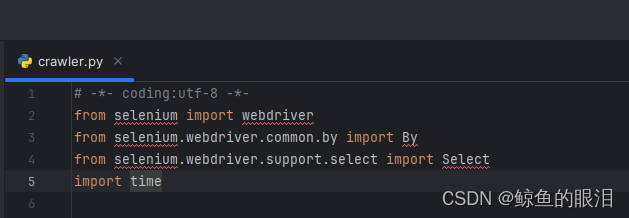
- 在编辑器中左下角找到Terminal(终端),
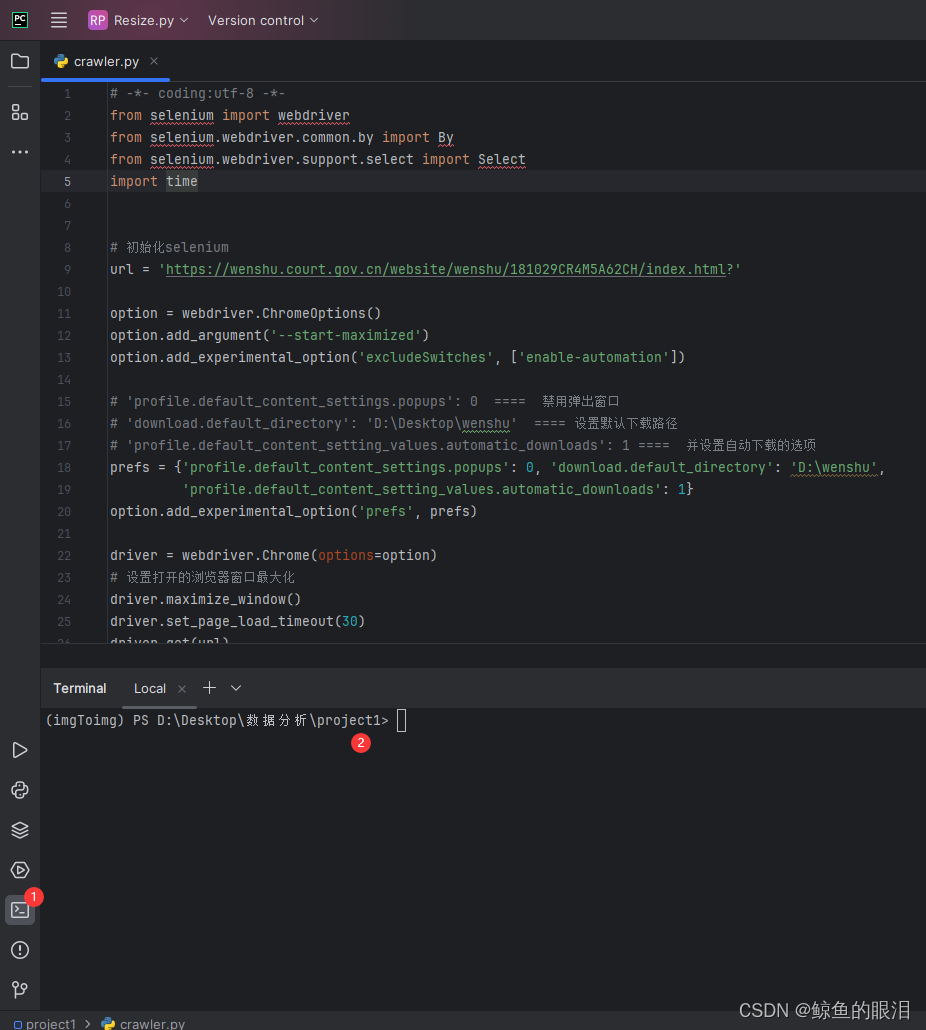
- 输入命令安装selenium库
pip install selenium
- 如果time库爆红,同样的命令安装time库
pip install time
完整代码
现在前面的准备工作已全部就绪,先贴完整python代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
import time
# 初始化selenium
url = 'https://wenshu.court.gov.cn/website/wenshu/181029CR4M5A62CH/index.html?'
option = webdriver.ChromeOptions()
option.add_argument('--start-maximized')
option.add_experimental_option('excludeSwitches', ['enable-automation'])
# 'profile.default_content_settings.popups': 0 == 禁用弹出窗口
# 'download.default_directory': 'D:\Desktop\wenshu' == 设置默认下载路径
# 'profile.default_content_setting_values.automatic_downloads': 1 == 并设置自动下载的选项
prefs = {'profile.default_content_settings.popups': 0,
'download.default_directory': 'D:\wenshu', # 设置自己的下载路径
'profile.default_content_setting_values.automatic_downloads': 1}
option.add_experimental_option('prefs', prefs)
driver = webdriver.Chrome(options=option)
# 设置打开的浏览器窗口最大化
driver.maximize_window()
driver.set_page_load_timeout(30)
driver.get(url)
# 转到登录界面自动输入手机号密码进行登录
driver.find_element(By.XPATH, '//*[@id="loginLi"]/a').click()
text = driver.page_source
time.sleep(10) # 等待页面渲染
# 进入iframe框
iframe = driver.find_elements(By.TAG_NAME, 'iframe')[0]
driver.switch_to.frame(iframe)
# 下面的‘手机号’‘密码’输入自己中国裁判文书网注册的真实手机号密码
username = driver.find_element(By.XPATH, '//*[@id="root"]/div/form/div/div[1]/div/div/div/input')
username.send_keys('手机号')
time.sleep(3)
username = driver.find_element(By.XPATH, '//*[@id="root"]/div/form/div/div[2]/div/div/div/input')
username.send_keys('密码')
time.sleep(2)
driver.find_element(By.XPATH, '//*[@id="root"]/div/form/div/div[3]/span').click()
time.sleep(3)
# 必须加上表单退出,否者就是死元素无法定位
driver.switch_to.default_content()
# 这行代码的作用就相当于你手动点了一下‘刑事案件’那个按钮
# 要下载民事案件就把下一行代码里的刑事案件改成‘民事案件’,以此类推
driver.find_element(By.LINK_TEXT, '刑事案件').click()
time.sleep(10)
# testHtml(driver.page_source)
_lastWindow = driver.window_handles[-1]
driver.switch_to.window(_lastWindow)
# 选择案件批量下载
# 这行代码的作用就相当于你手动点了一下‘法院层级’那个按钮
# driver.find_element(By.LINK_TEXT, '法院层级').click()
# 按照裁判日期排序显示最新600条
# driver.find_element(By.LINK_TEXT, '裁判日期').click()
# 按照裁判日期从前到后显示最老600条
# driver.find_element(By.LINK_TEXT, '裁判日期').click()
# 按照审判程序排序显示最新600条
# driver.find_element(By.LINK_TEXT, '审判程序').click()
# 按照审判程序从前到后显示最老600条
# driver.find_element(By.LINK_TEXT, '审判程序').click()
# 按照法院层级、地域及法院进行检索
driver.find_element(By.LINK_TEXT, '高级法院(146202)').click()
time.sleep(3)
driver.find_element(By.LINK_TEXT, '上海市(1188)').click()
# 在搜索框输入关键词进行高级检索
# 定位到搜索框
keyword = driver.find_element(By.XPATH, '//*[@id="_view_1545034775000"]/div/div[1]/div[2]/input')
time.sleep(3)
# 输入高级检索关键词,例如 工程纠纷
keyword.send_keys('工程纠纷')
time.sleep(3)
# 点击搜索按钮
driver.find_element(By.XPATH, '//*[@id="_view_1545034775000"]/div/div[1]/div[3]').click()
# 将每页文件数设置为最大,15条
page_size_box = Select(driver.find_element(By.XPATH, '//*[@id="_view_1545184311000"]/div[8]/div/select'))
page_size_box.select_by_visible_text('15')
def test_exceptions(xpath):
try:
driver.find_element(By.XPATH, xpath)
return True
except:
return False
page = 1
# 最多显示600条文件,也就是40页
while page <= 40:
time.sleep(5+page/10)
for i in range(15):
time.sleep(5+i/10)
event_xpath = '//*[@id="_view_1545184311000"]/div[' + str(i+3) + ']/div[6]/div/a[2]'
if test_exceptions(event_xpath) == True:
driver.find_element(By.XPATH, event_xpath).click()
else:
event_xpath = '//*[@id="_view_1545184311000"]/div[' + str(i+3) + ']/div[5]/div/a[2]'
if test_exceptions(event_xpath) == True:
driver.find_element(By.XPATH, event_xpath).click()
# 下一页按钮,不能用Xpath定位,因为“下一页”按钮位置不固定
# driver.find_element(By.LINK_TEXT, '下一页').click()
time.sleep(5)
driver.find_element(By.LINK_TEXT, '下一页').click()
# 必须加上表单退出,否者就是死元素无法定位
driver.switch_to.default_content()
page += 1
# 关闭整个浏览器窗口并终止与浏览器的会话
driver.quit()
运行时
代码也配置无误后,运行代码会自动弹出一个chrome浏览器窗口界面
弹出界面显示下图输入验证码时需要用户手动输入并点击确定:
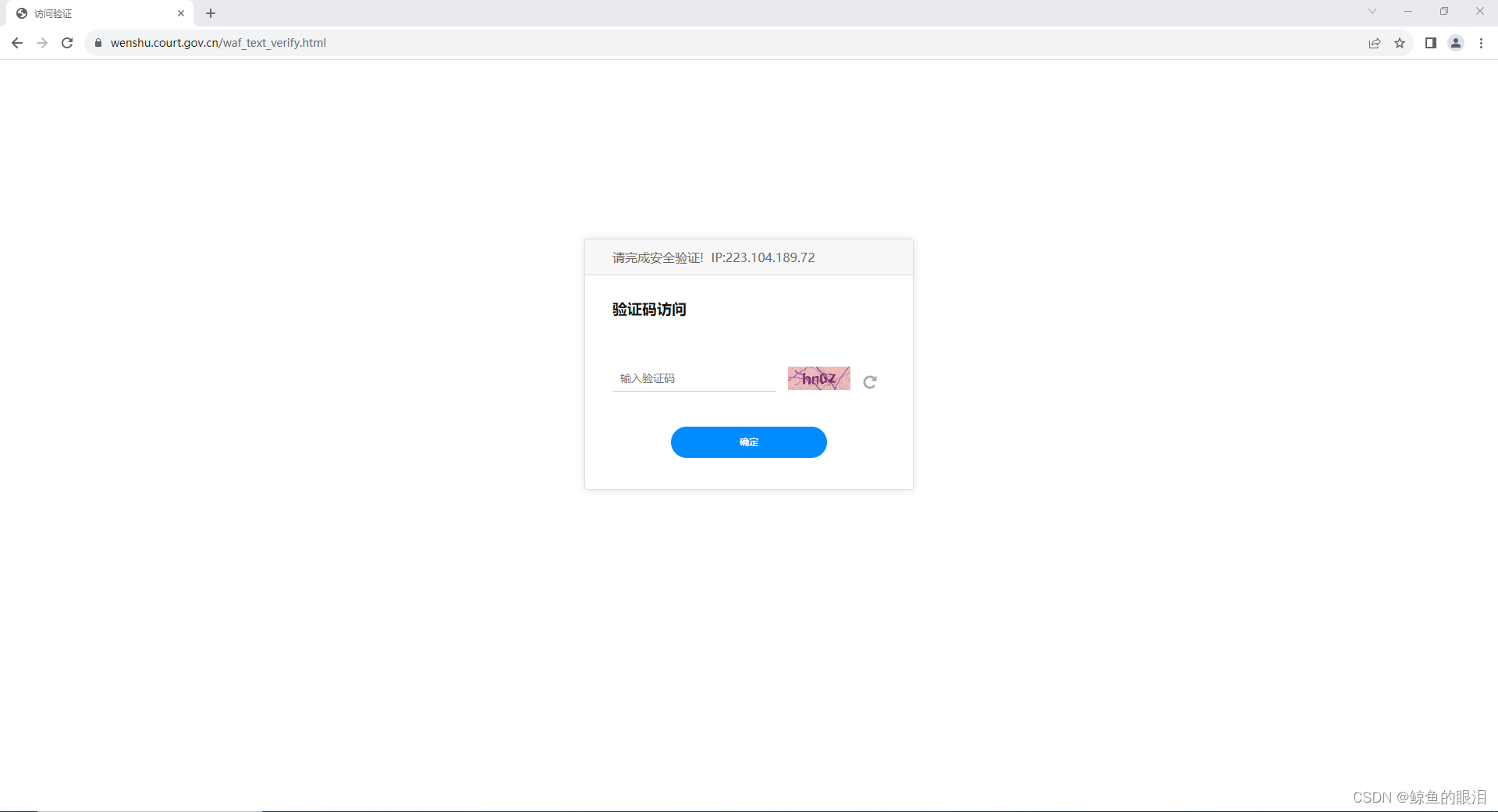
正常情况下不需要用户进行任何操作。输入账号、密码,点击登录按钮登录这些都是会自动执行的!!!
代码中很多操作都设置有延迟几秒的操作,所以代码运行过程中只要没有中断,网页突然自动关闭,就没问题。大家不要着急,只需耐心等待即可。
注意:代码运行后除非上述输入验证码,其他时间耐心等待,不要离开当前运行的脚本窗口,不要点击任何地方
下载自定义
- 修改代码中第17行设置自己想要的下载路径:
'download.default_directory': 'D:\xxx\xxx',
分隔符注意用单个的反斜线'\';可以是不存在的路径,会自动创建该路径
- 代码37行和42行修改为真实的已注册的手机号密码
line 37: username.send_keys('XXX') XXX改为自行注册的手机号
line 42: username.send_keys('XXX') XXX改为注册时设置的密码
-
自定义选择下载内容
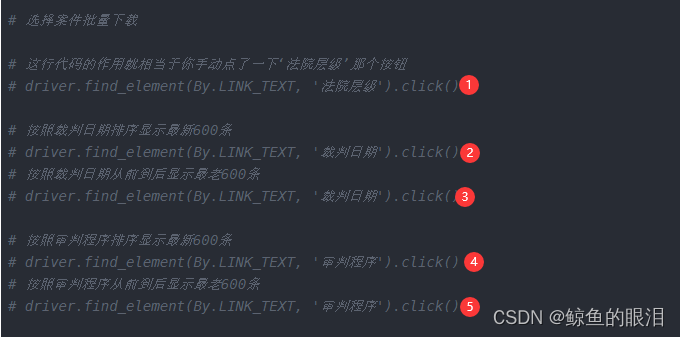
1,2,3,4,5这五行代码:
- 全部注释---------------------------------按照法院层级从高到低排序
- 保留1,注释其他----------------------按照法院层级从低到高排序
- 保留2,注释其他----------------------按照裁判日期由近到远排序
- 保留2和3,注释其他-----------------按照裁判日期由远到近排序
- 保留4,注释其他----------------------按照审判程序由近到远排序
- 保留4和5,注释其他-----------------按照裁判日期由远到近排序
高级检索
下面代码片段在完整代码部分已经给出
(1)按照法院层级、地域及法院进行检索
driver.find_element(By.LINK_TEXT, '高级法院(146202)').click()
time.sleep(3)
driver.find_element(By.LINK_TEXT, '上海市(1188)').click()
注意:关键词后面的数字肯定会随着时间的改变而变化,根据当时页面显示的数字自行修改数字大小
(2)通过在搜索框输入关键词进行高级检索
# 定位到搜索框
keyword = driver.find_element(By.XPATH, '//*[@id="_view_1545034775000"]/div/div[1]/div[2]/input')
time.sleep(3)
# 输入高级检索关键词,例如 工程纠纷
keyword.send_keys('工程纠纷')
time.sleep(3)
# 点击搜索按钮
driver.find_element(By.XPATH, '//*[@id="_view_1545034775000"]/div/div[1]/div[3]').click()
爬虫该网站次数过多可能会有封号的风险,请大家谨慎使用



















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











