






如题,实际上目前的家用宽带,均已经分配了公网 ipv6 地址,出门在外均可以访问家用宽带。并不需要打电话向运营商申请,默认已经有了,但是需要在路由器上设置相关选项
目前光猫 并未设置 桥接模式,而是运营商配好的光猫。下面接入的二级路由。
接入的二级路由是 openwrt
网络环境如下:运营商路由器 =》 openwrt路由器 =》 局域网等手机、电脑设备
局域网下的手机、电脑均连入的 openwrt路由器,而 openwrt 作为子设备接入的运营商路由器
用途
开放ipv6公网访问后,可以使用公网ipv6访问家中的nas,或者搭建好的 alist 等服务
虽然 ipv6 地址可能发生变动,如果再搭配一个自动检测 ipv6 地址变动的程序,再自动的解析绑定最新域名,即可实现随时访问内网文件、服务等。
开放运营商路由器的防火墙
运营商赠送的光猫路由器自带了防火墙,禁用了外网访问,需要开放,如下:
将 Ipv6spi 取消勾选, 然后点击 确定 保存
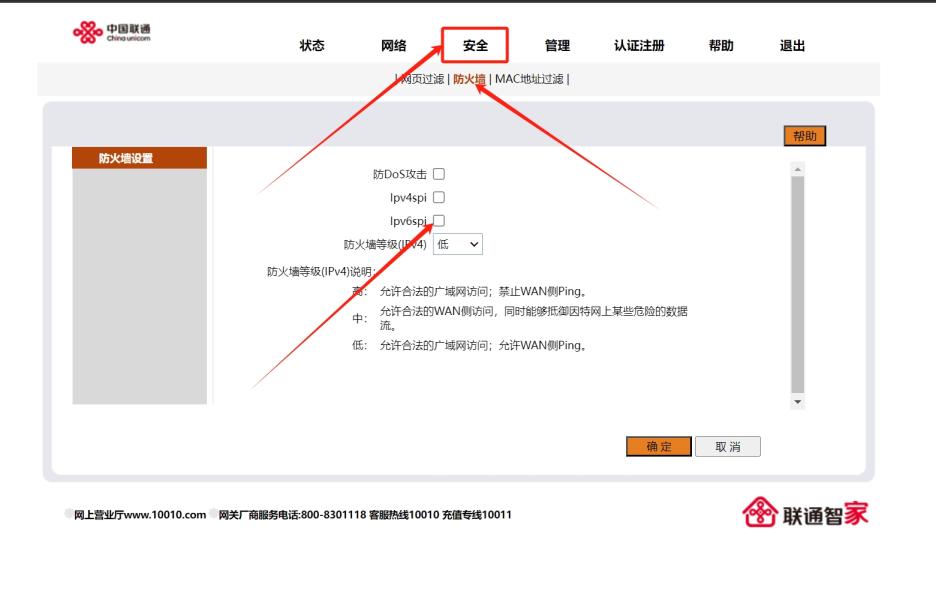
实际上,取消勾选后,接入光猫的局域网设备均可以被外网访问,有一定的安全风险
openwrt 开放路由器下的设备公网访问
光猫路由器开放后,openwrt具备公网访问的条件,但 openwrt 也有一道防火墙,默认情况下,openwrt 路由器下的 转发 选项是拒绝,只要将拒绝改为 接受 ,则路由器下所有设备均可被公网访问
但是家用环境下,智能电视、扫地机器人等等设备,系统老旧,存在被入侵风险,所以不建议修改 转发 选项,继续保持默认,然后开放指定的端口即可
如果图简单省事,将 转发改为 接受即可
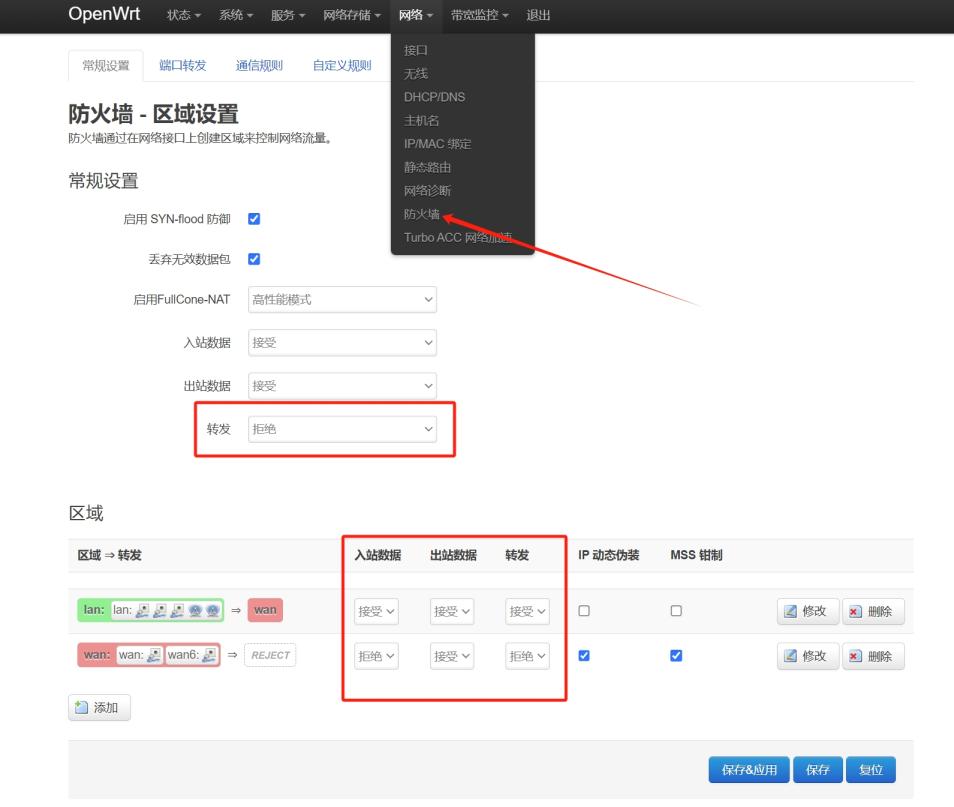
开放 openwrt 路由器下指定局域网端口访问
如果为了提高网络安全性,不允许所有局域网设备公网访问,仅开放指定端口或设备,可以在通信规则中添加规则,在规则中设置 目标端口,如下,开放局域网内设备的 8084 端口
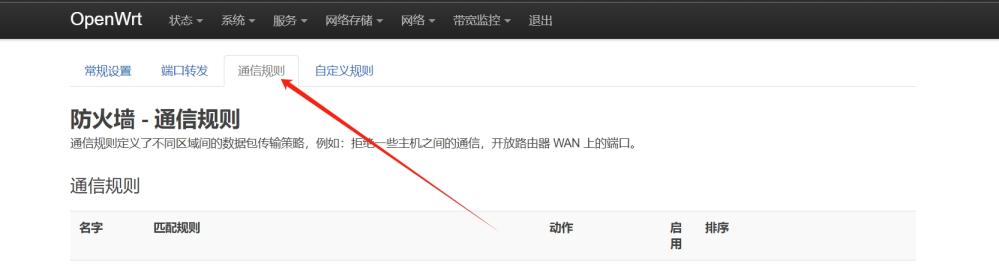
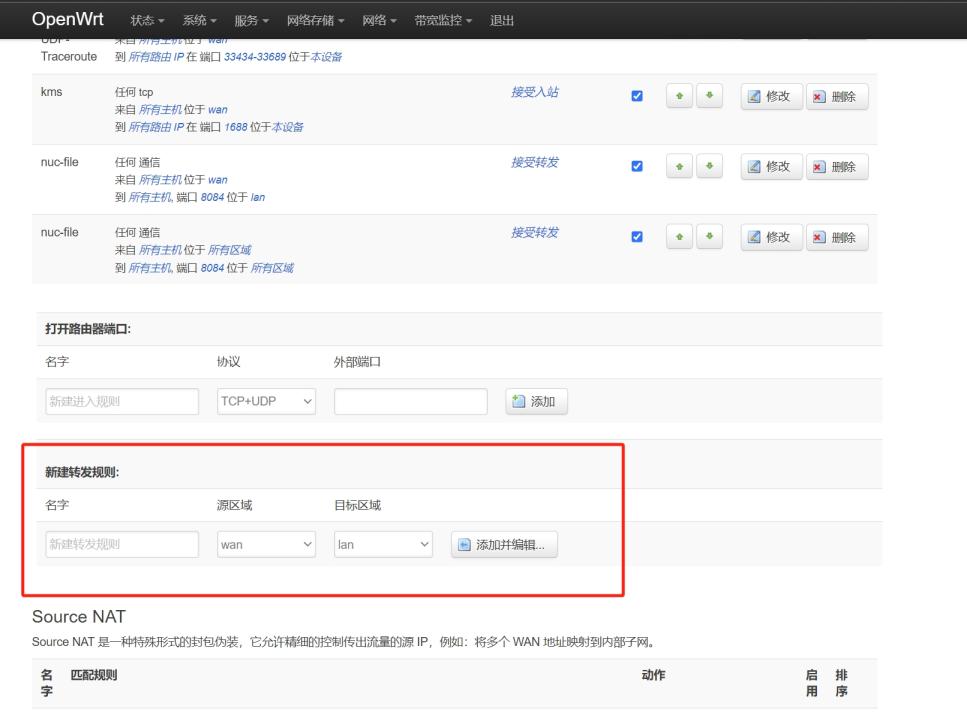
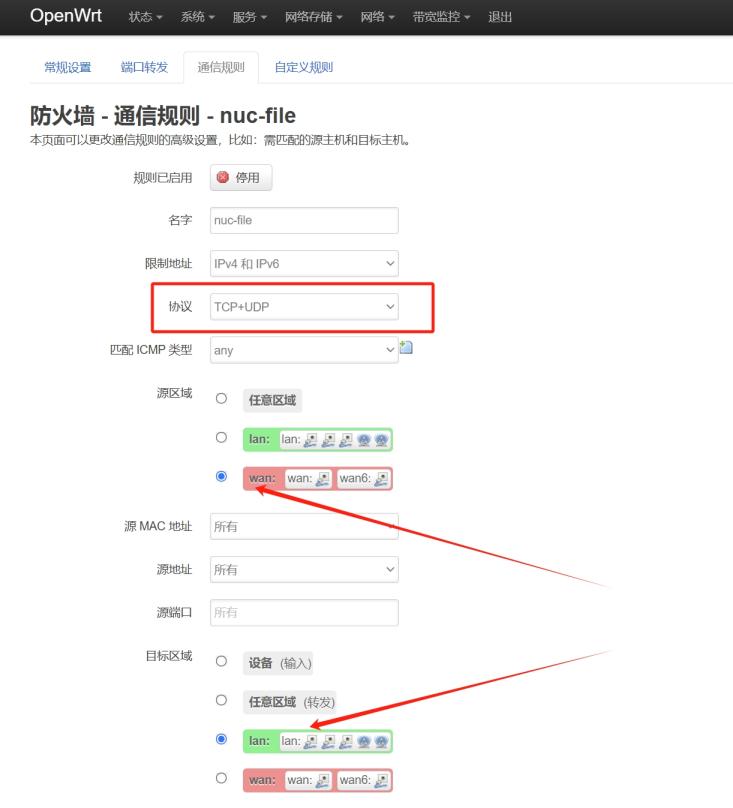
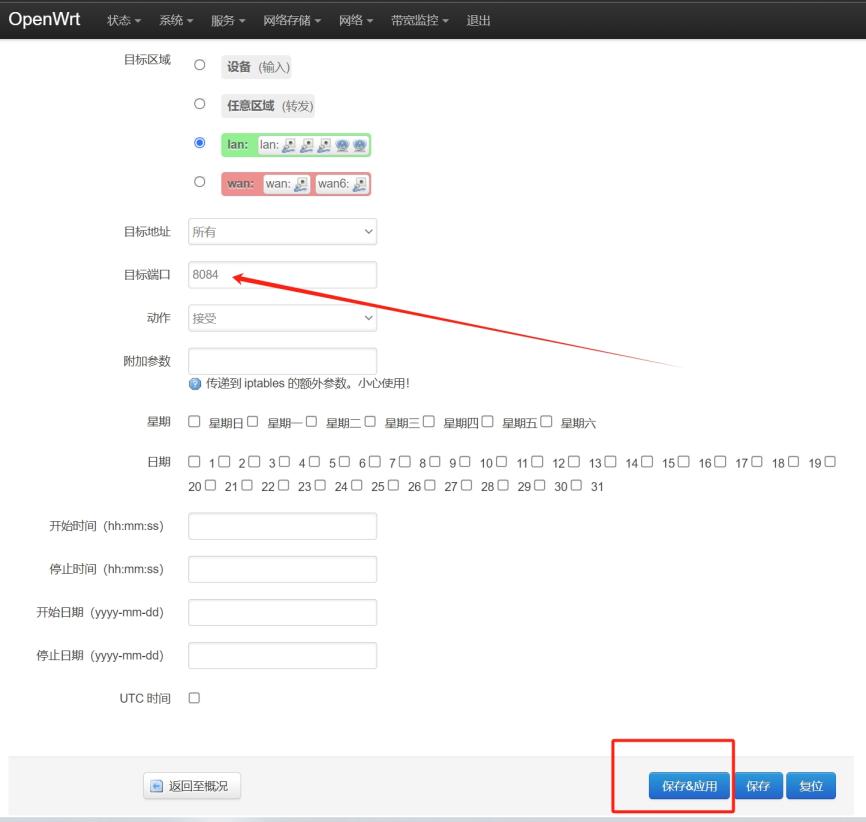
如上即可开放局域网设备的 8084 端口以供公网访问
注意事项
一台局域网设备会被分配多个 ipv6 地址,但有的ipv6地址是局域网地址,无法被公网访问。
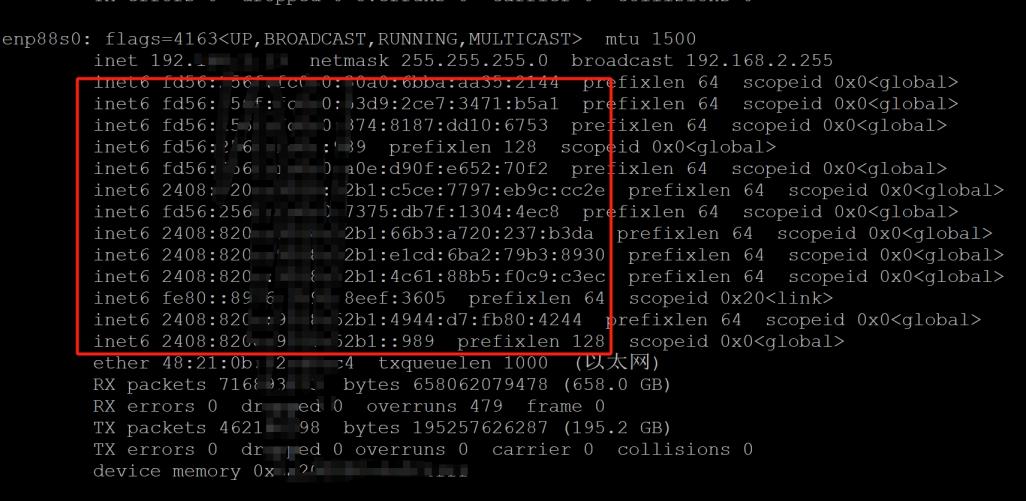
所以配置完成后,需要找到能被公网访问的 ipv6 才能正常使用,另外,对于常用的端口,如 80、443 ,运营商防火墙依旧会阻断
IPv6地址中,240e开头是电信,2408开头是联通,2409开头是移动

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









