







前言
前几篇文章花了大力气完成了ShardingSphere-JDBC5的读写分离和数据库多种分片场景,接下来,开始整合一下读写分离+数据库分片。
前文参考链接:
ShardingSphere-JDBC5.1.1实现数据库分片最完整讲解
ShardingSphere-JDBC5.1.1实现数据库读写分离(权重算法)
基于这两篇文章开始合并。
数据库准备
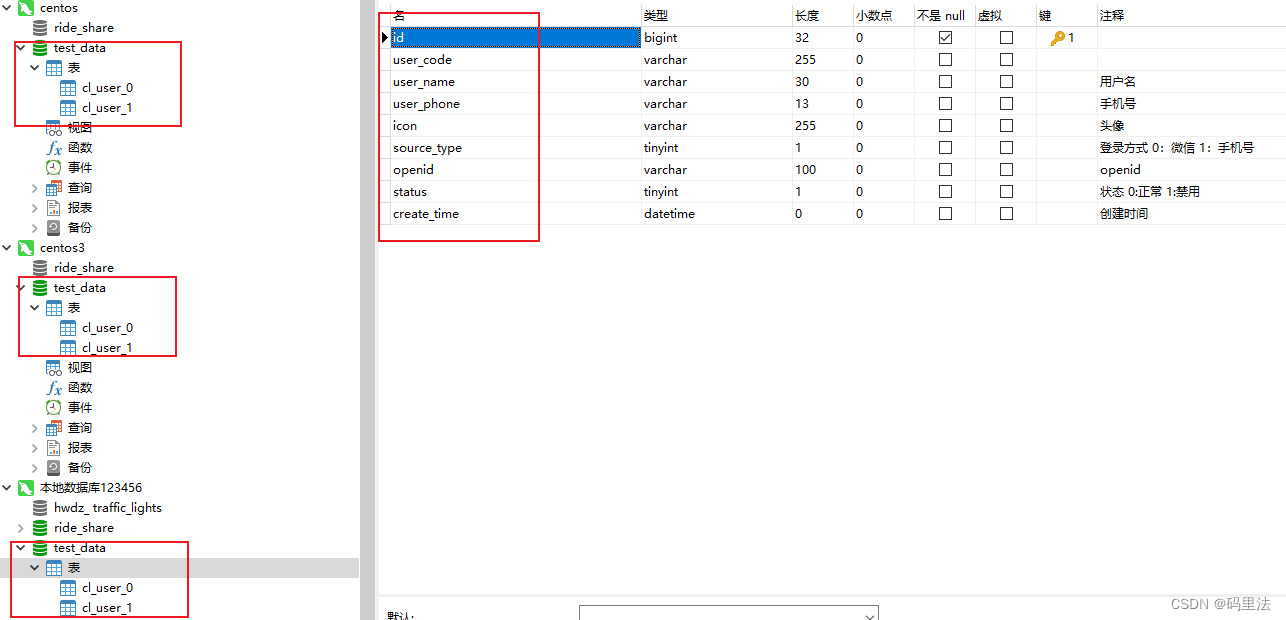
三个库,每个库放两个分表;
配置详解
spring:
autoconfigure:
exclude: com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure
datasource:
druid:
stat-view-servlet:
enabled: true
loginUsername: admin
loginPassword: 123456
allow:
web-stat-filter:
enabled: true
shardingsphere:
props:
# 是否在日志中打印 SQL 更多属性参考->https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/props/
sql-show: true
datasource:
names: slave2,slave1,slave0
slave2:
url: jdbc:mysql://localhost:3306/test_data?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: 123456
slave0:
url: jdbc:mysql://192.168.150.129:3306/test_data?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: root
slave1:
url: jdbc:mysql://192.168.150.132:3306/test_data?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: root
rules:
# 读写分离
readwrite-splitting:
data-sources:
ds:
# 读写分离类型,比如:Static,Dynamic,动态方式需要配合高可用功能,具体参考下方链接
# https://blog.csdn.net/ShardingSphere/article/details/123243843
type: Static
loadBalancerName: round-robin
props:
# 注意,如果接口有事务,读写分离不生效,默认全部使用主库,为了保证数据一致性
write-data-source-name: slave2
read-data-source-names: slave1,slave0
load-balancers:
#名称自定义,跟上边的loadBalancerName配置的值保持一致
round-robin:
type: RANDOM #一共三种一种是 RANDOM(随机),一种是 ROUND_ROBIN(轮询),一种是 WEIGHT(权重)
# 步骤:设置分片节点(一个整表分为了多少个分表)->分片规则(根据主键的分片算法,这样才能知道数据存取位置)->主键生成规则(uuid或者雪花算法SNOWFLAKE)
sharding:
tables:
# 配置cl_user的分表的规则
cl_user:
# 拥有几个分片表0-3,表达式参考 https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/inline-expression/
actual-data-nodes: ds.cl_user_$->{0..1}
table-strategy:
standard:
sharding-column: id
sharding-algorithm-name: table-inline
# 配置分片算法
sharding-algorithms:
# 分库分表算法共用一个
table-inline:
type: HASH_MOD
props:
sharding-count: 2
# database-inline:
# type: HASH_MOD
# props:
# sharding-count: 3
# default-database-strategy:
# standard:
# sharding-column: id
# sharding-algorithm-name: database-inline
需要注意的几个点:
- 这两个地方一定要对应
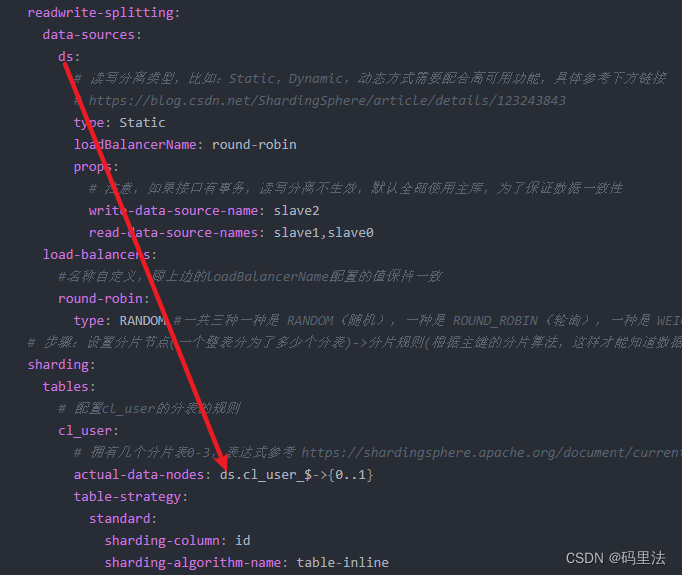
- 如果你只有一个主库负责写入,就一定不要配置数据库算法,不然会报 No database route info的错误,因为根据库算法之后,得到的实际库可能不存在。
- 不管是分库还是分表,算法规则最后一定要对应上实际的物理库和物理表,否则就会报很多乱七八杂的错误,大部分都是找不到库,找不到表,主键和算法不对应的问题。
















 1196
1196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









