







1、Hadoop Ecosystem
(1)结构化、非结构化数据统一存储平台:结构化数据是通常所说的行数据(如数字、符号等信息),存储在关系数据库中,可用二维表来表示。半结构化数据通常指的是一个实例的字段(特征/属性)数目是不固定。比如HTML文档,比如树、图数据。非结构数据是指其字段长度可变,并且每个字段的记录又可以由可重复或不可重复的子字段构成的数据(全文文本、图象、声音、影视、超媒体等信息)。
(2)批处理、实时、流式统计计算平台。
2、SQL on Hadoop Architecture
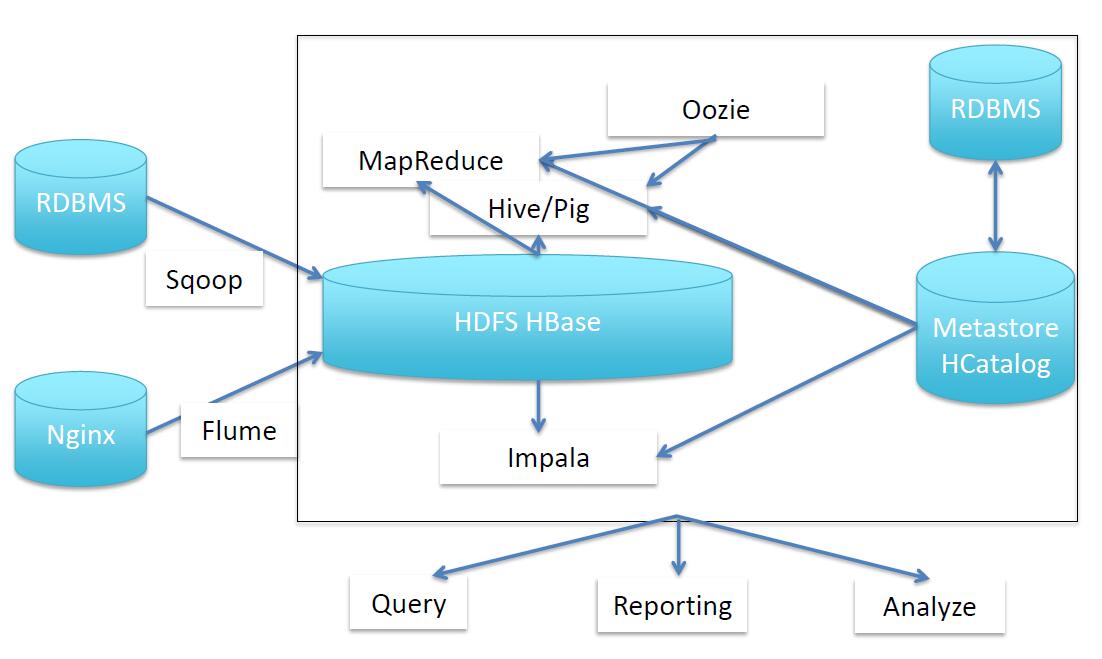
(1)RDBMS(关系数据库管理系统):少量的关系数据存储在这个部分,通过Sqoop导入到HDFS中。最基本的存储格式。
(2)Nginx:大数据中的数据大部分是指机器产生的日志数据,使Flume收集到HDFS上。
(3)Hive/Pig:构建各种维度的查询视图。完成一个SQL查询HDFS数据的引擎。
(4)MapReduce:分布式并行运算框架。
(5)Impala:对于分析人员,基于底层原始数据的聚合,完成数据量不是很大的实时查询。
(6)Metastore:元数据管理平台,主要是HDFS是文档,是非结构化数据。
以上几部分就完成了大数据的收集,存储,再到分析挖掘的完成过程。
3、Hadoop与实时计算(开源的)
(1)Tez/Stinger(Hortonworks):基于Hive的改进,提供计算效率。
(2)Impala(Cloudera):降低在MR的投入。
(3)Presto(Facebook):Facebook自己的。
(4)Shark(Databricks):伯克利大学的人开发并推广。
(5)Phoenix(Salesforce)。
(6)Hawq(EMC/Pivatol)。
4、Tez
Tez解决传统的MR,在于复杂逻辑下的效率低下问题,比如在K-means,需要不停地迭代。这个时候可以使用改进的MRR,多个Reduce过程。
5、Impala Architecture
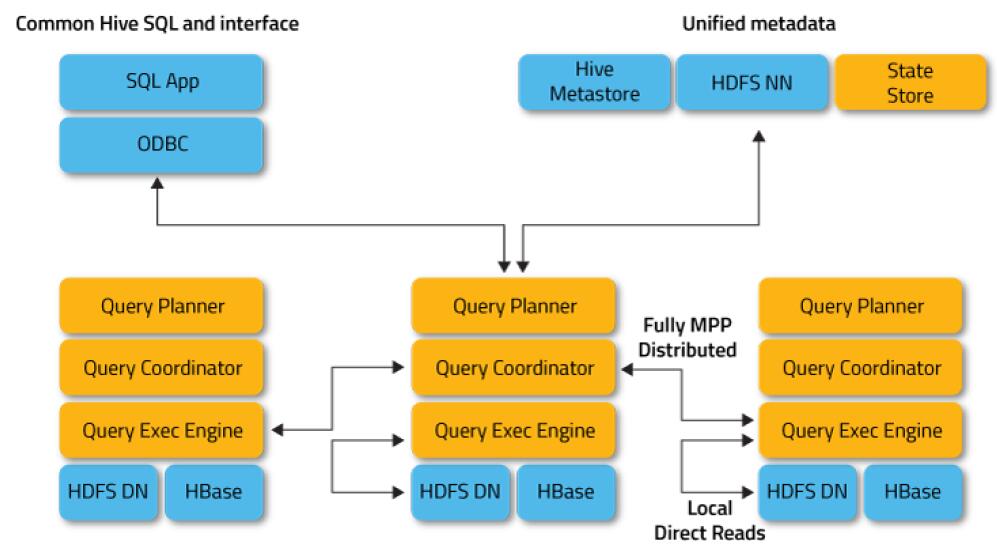
1、专门为SQL做一个执行引擎,类似传统的并行数据仓库FTP。
2、一个简单的Impala查询的例子。
select
jobinfo.dt, user,
max(taskinfo.finish_time-taskinfo.start_time),
max(jobinfo.finish_time-jobinfo.submit_time)
form
taskinfo
join
jobinfo
on
jobinfo.jobid = taskinfo.jobid
where
jobinfo.job_status='SUCCESS' and taskinfo.task_status='SUCCESS'
group by
jobinfo.dt, user3、执行逻辑:ScanNode->HashJoinNode->Aggregation。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









