







1、Hive SQL的基本实现(Join、Group by、Distinct)
(1)Join实现:Hive不支持关联字查询。例如:
select t1.name,t2.name from t1 join t2 on t1.id=t2.id;(2)Group by实现:
select tab.feature1,tab.feature2,count(*) from tab group by feature1,feature2;(3)Distinct实现:
select tab.fea1id,count(distinct tab.fea2id) num from tab order group by tab.fea1id;注意:多列Distinct实现比较复杂。类似于Cube。
2、Hive 中的数据抽象
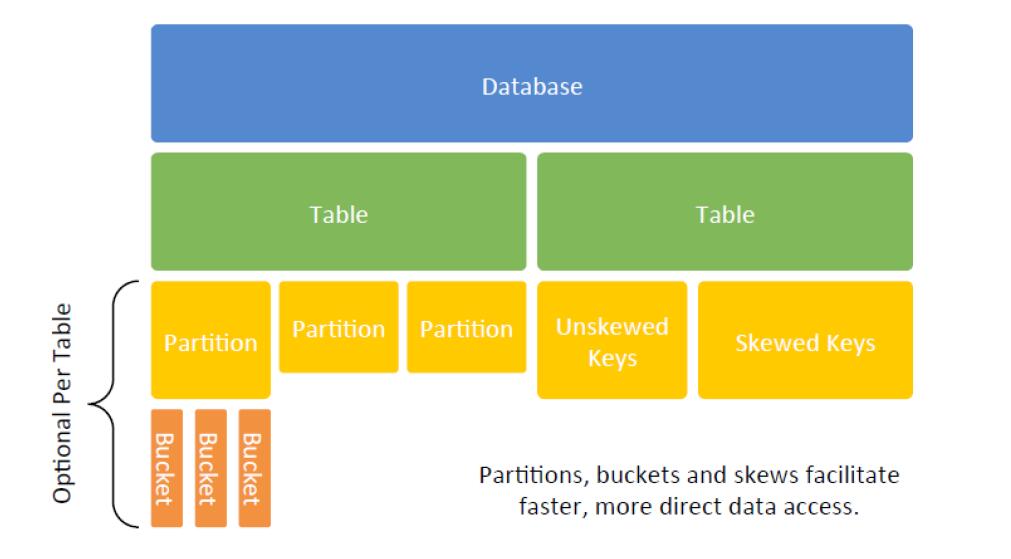
3、JOIN类型
(1)Shuffle Join,join key用MRShuffle;
(2)Broadcast Join,一大一小的table,比如星形数据库表很适合,维度表小到能装到单节点内存中;
(3)Sort-Merge-Bucket join,大表和大表的join,数据仓库中一个难点,即是impala也是受限于内存。
4、优化Hive性能的数据管理方式
(1)Small表(维度较小),数据很热,做各种查询,可以增加备份表;
(2)任何数据,需要查询过滤,可以在经常查询的列上排序;
(3)Large Table,join key,sort and bucket;
(4)分开而数据和冷数据;
(5)Large table,查询,比如时间,可以采用partition。
5、Hive table 存储格式
(1)ORCFile:存储列数较多的表;
(2)RCFile、AVro、Delimited Text、Regular、JSON和XML
6、Hive 调优
(1)使用ORCFile;
(2)Partition data;
(3)最小化data shuff。















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









