







您的点赞、关注、收藏、评论,是对我最大的激励和支持!!!🤩🥰😍
目录
安装
pip install scikit-learn数据
X,y即为所需要进行回归处理的数据。
操作:拆分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3, random_state=12)缺失值处理
# 缺失值处理
from sklearn.impute import SimpleImputer
# 创建SimpleImputer对象,使用均值填充缺失值
imputer = SimpleImputer(strategy='mean')
# 对数据集进行拟合和转换
X_train = imputer.fit_transform(X_train)
X_test = imputer.transform(X_test)数据标准化
# 数据标准化
#fit(), 用来求得训练集X的均值,方差,最大值,最小值,这些训练集x固有的属性。
#transform(),在fit的基础上,进行标准化,降维,归一化等操作。
#fit_transform(),包含上述两个功能。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)对文本数据进行数字编码
# 对某列进行编码
from sklearn.preprocessing import LabelEncoder
# 创建LabelEncoder对象
encoder = LabelEncoder()
# data数据自行提供
data['朝向编码'] = encoder.fit_transform(data['朝向'])处理后效果如下:
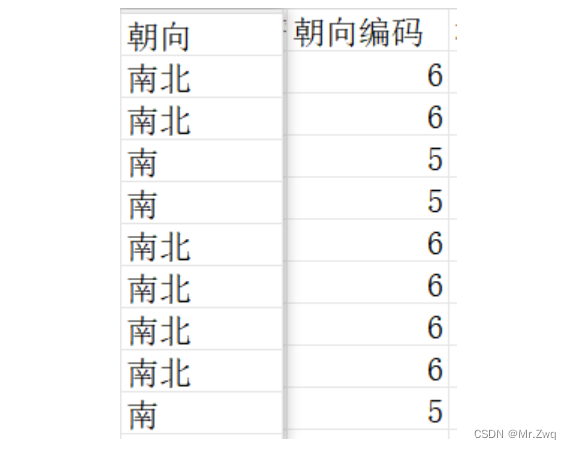
总结
感谢观看,原创不易,如果觉得有帮助,请给文章点个赞吧,让更多的人看到。🌹🌹🌹

👍🏻也欢迎你,关注我。👍🏻
如有疑问,可在评论区留言哦~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











