






HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
HBase 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,用于存储海量的结构化或者半结构化,非结构化的数据。
HBase 架构
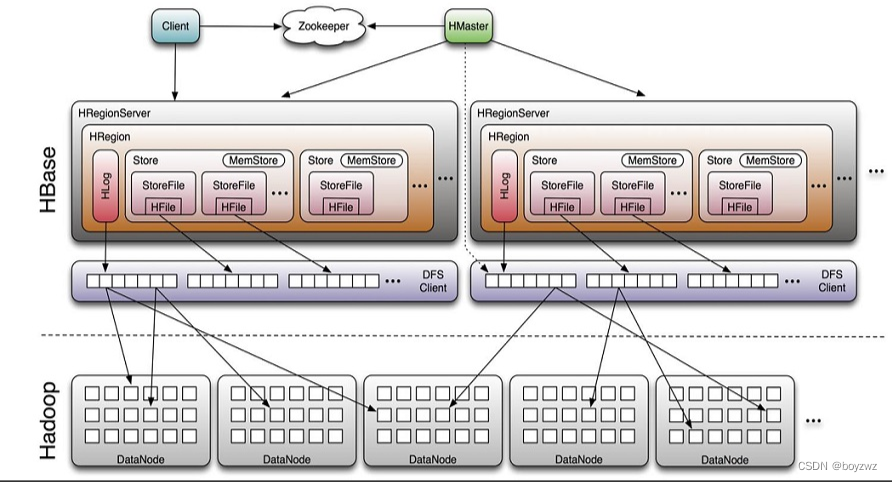
1. Region Server
Region Server 为 Region 的管理者,负责数据的读写服务,用户通过与Region server交互来实现对数据的访问。
对于数据的操作:get, put, delete;
对于Region 的操作:splitRegion、compactRegion。
2. HBase HMaster
Master 是所有 Region Server 的管理者,负责Region的分配及数据库的创建和删除等操作。
对于表的操作:create, delete, alter
对于 RegionServer 的操作:分配 regions 到每个 RegionServer,监控每个 RegionServer 的状态,负载均衡和故障转移。
3. ZooKeeper
负责维护集群的状态;
实时监控Region server的上线和下线信息,并实时通知Master
存储HBase的schema和table元数据
4. HDFS
HDFS 为 HBase 提供最终的底层数据存储服务,同时为 HBase 提供高可用的支持。
数据最后存在HDFS上的,HDFS不支持删改,为什么Hbase就可以呢??
这里有个思想误区,的确,数据是以HFile形式存在HDFS上的,而且HDFS的确是不支持删改的,但是为什么Hbase就支持呢?首先,这里的删除并不是真正意义上的对数据进行删除,而是对数据进行打上标记,我们再去查的时,就不会查到这个打过标记的数据,这个数据Hmaster会每隔1小时清理。修改是put两次,Hbase会取最新的数据,过期数据也是这个方式被清理。
HBase 的读写流程
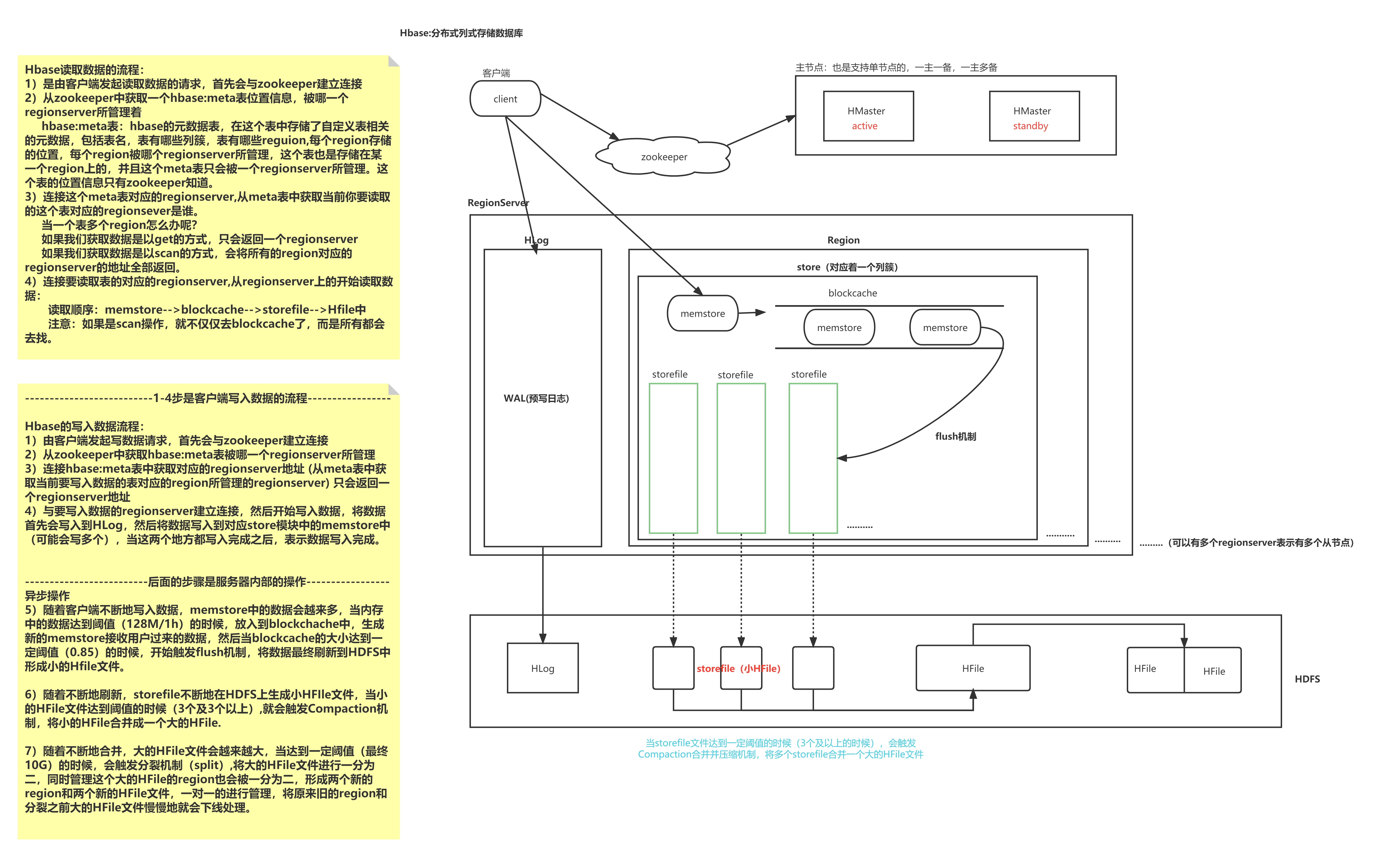 1. Region
1. Region
table在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元;
即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。Region按大小分隔,表中每一行只能属于一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值,时就会分成两个新的region。
2. Store
每一个region有一个或多个store组成,至少是一个store;一个store对应一个列簇。
Store包括位于内存中的MemStore和位于磁盘的StoreFile;
一个Store由一个memStore和0或多个StoreFile组成。
3. MemStore
写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的HFile。
4. StoreFile
保存实际数据的物理文件,StoreFile 以 HFile 的形式存储在 HDFS 上。每个 Store 会有一个或多个StoreFile(HFile),数据在每个 StoreFile 中都是有序的。
HBase 的读流程:
1、 客户端发起读取数据的请求,先与zookeeper建立连接,获取 hbase:meta 表位于哪个 Region Server
2、根据Region Server上的hbase:meta 表,查询出想要获取的数据位于哪一个Region Server。
如果我们获取数据是以get的方式,只会返回一个regionserver;
若一个表拥有多个Region,我们获取数据是以scan的方式,会将所有的region对应的regionserver的地址全部返回。
3、当Client知道要访问的表在哪个Regionserver之后,Client就对那个Regionserver 发起读请求。从regionserver上的开始读取数据:
读取顺序:memstore-->blockcache-->storefile-->Hfile中
注意:如果是scan操作,就不仅仅去blockcache了,而是所有都会去找。
hbase:meta表:hbase的元数据表,在这个表中存储了自定义表相关的元数据,包括表名,表有哪些列簇,表有哪些reguion,每个region存储的位置,每个region被哪个regionserver所管理,这个表也是存储在某一个region上的,并且这个meta表只会被一个regionserver所管理。这个表的位置信息只有zookeeper知道。
为什么Client只需要知道Zookeeper地址就可以了呢?
当HBase启动时,Region server 会向HMaster汇报数据信息,最后HMaster整理出了一张Meta表,会把Meta信息表加载到zookeeper。所以读写数据,只需要跟Zookeeper对应的Regionserver进行交互就可以了。HMaster只需要存储Region和表的元数据信息,协调各个Regionserver,所以他的负载就小了很多。
如果Regionserver失效了,会发生什么?
如果某一个Regionserver挂了,HMaster会把该Regionserver删除,之后将Regionserver存储的数据,分配给其他的Regionserver,将更新之后meta表,交给Zookeeper
所以当某一个Regionserver失效了,并不会对系统稳定性产生任何影响。
当HMaster失效后会发生什么?
对于HA高可用集群,当Active状态的HMaster失效,会有处于Backup 的HMaster可以顶上去,集群可以继续正常运行。
如果没有配置HA,那么对于客户端的新建表,修改表结构等需求,因为新建表,修改表结构,需要HMaster来执行,会涉及meta表更新。那么 会抛出一个HMaster 不可用的异常,但是不会影响客户端正常的读写数据请求。
HBase 的写流程
1、 客户端发起读取数据的请求,先与zookeeper建立连接,获取 hbase:meta 表位于哪个 Region Server
2、根据 hbase:meta表获取表对应的Region Server地址(从meta表中获取当前要写入数据的表对应的region所管理的regionserver) 只会返回一个regionserver地址
3、与要写入数据的regionserver建立连接,然后开始写入数据,将数据首先会写入到HLog,然后将数据写入到对应store模块中的memstore中(可能会写多个),当这两个地方都写入完成之后,表示数据写入完成。
服务器内部操作
异步操作
4、首先数据会写入memStore,当memStore到达阈值时(128M/1h),触发flush机制,将数据刷写到磁盘,生成StoreFile文件。Storefile是HFile的一层封装,HFile存储在HDFS上,所以存储到HBase中的数据最终会存储到HDFS。
5、当storeFile的文件达到一定阈值后(3个及以上), 就会触发compact的合并机制, 将多个storeFile合并为一个大的HFile文件
6、随着不断地合并,大的HFile文件会越来越大,当达到一定阈值(最终10G)的时候,会触发分裂机制(split),将大的HFile文件进行一分为二,同时管理这个大的HFile的region也会被一分为二,形成两个新的region和两个新的HFile文件,一对一的进行管理,将原来旧的region和分裂之前大的HFile文件慢慢地就会下线处理。
Memstore 总结
Memstore 中的数据是排序的,当MemStore累计到一定阈值时就会创建一个新的MemStore,并且将老的MemStore 添加到flush队列由单独的线程flush到磁盘上,称为一个StoreFile。
Memstore Flush触发条件
HBase会在如下几种情况下触发flush操作,需要注意的是MemStore的最小flush单元是HRegion而不是单个MemStore。可想而知,如果一个HRegion中Memstore过多,每次flush的开销必然会很大,因此我们也建议在进行表设计的时候尽量减少ColumnFamily的个数
1、Memstore级别限制:当Region中任意一个MemStore的大小达到了上限(hbase.hregion.memstore.flush.size,默认128MB),会触发Memstore刷新
2、Region级别限制:当Region中所有Memstore的大小总和达到了上限(hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size,默认 2* 128M = 256M),会触发memstore刷新
3、Region Server级别限制:当一个Region Server中所有Memstore的大小总和达到了上限(hbase.regionserver.global.memstore.upperLimit * hbase_heapsize,默认 40%的JVM内存使用量),会触发部分Memstore刷新。Flush顺序是按照Memstore由大到小执行,先Flush Memstore最大的Region,再执行次大的,直至总体Memstore内存使用量低于阈值(hbase.regionserver.global.memstore.lowerLimit * hbase_heapsize,默认 38%的JVM内存使用量)
4、当一个Region Server中HLog数量达到上限(可通过参数hbase.regionserver.maxlogs配置)时,系统会选取最早的一个 HLog对应的一个或多个Region进行flush
5、HBase定期刷新Memstore:默认周期为1小时,确保Memstore不会长时间没有持久化。为避免所有的MemStore在同一时间都进行flush导致的问题,定期的flush操作有20000左右的随机延时
6、手动执行flush:用户可以通过shell命令 flush ‘tablename’或者flush ‘region name’分别对一个表或者一个Region进行flush
compact合并机制
指的memStore中不断进行flush刷新操作, 就会产生多个storeFile的文件, 当storeFile的文件达到一定阈值后, 就会触发compact的合并机制, 将多个storeFile合并为一个大的HFile文件
阈值: 达到3个及以上
整个合并过程分为两大阶段:
--minor :
作用: 将多个小的storeFile合并为一个较大的Hfile操作
阈值: 达到3个及以上
注意: 此合并过程, 仅仅将多个合并为一个, 对数据进行排序操作, 如果此时数据有过期, 或者有标记为删除数据, 此时不做任何的处理 (类似于 内存合并中基础型),所以说, 此合并操作, 效率比较高
--major:
作用: 将较大的HFile 和 之前的大的Hfile进行合并形成一个更大的Hfile文件 (全局合并)
阈值: 默认 7天
注意: 此合并过程, 会将那些过期的数据, 或者已经标记删除的数据, 在这次合并中, 全部都清除掉
由于这是一种全局合并操作, 对性能影响比较大, 在实际生产中, 建议 关闭掉自动合并,采用手动触发的方案















 3079
3079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









