






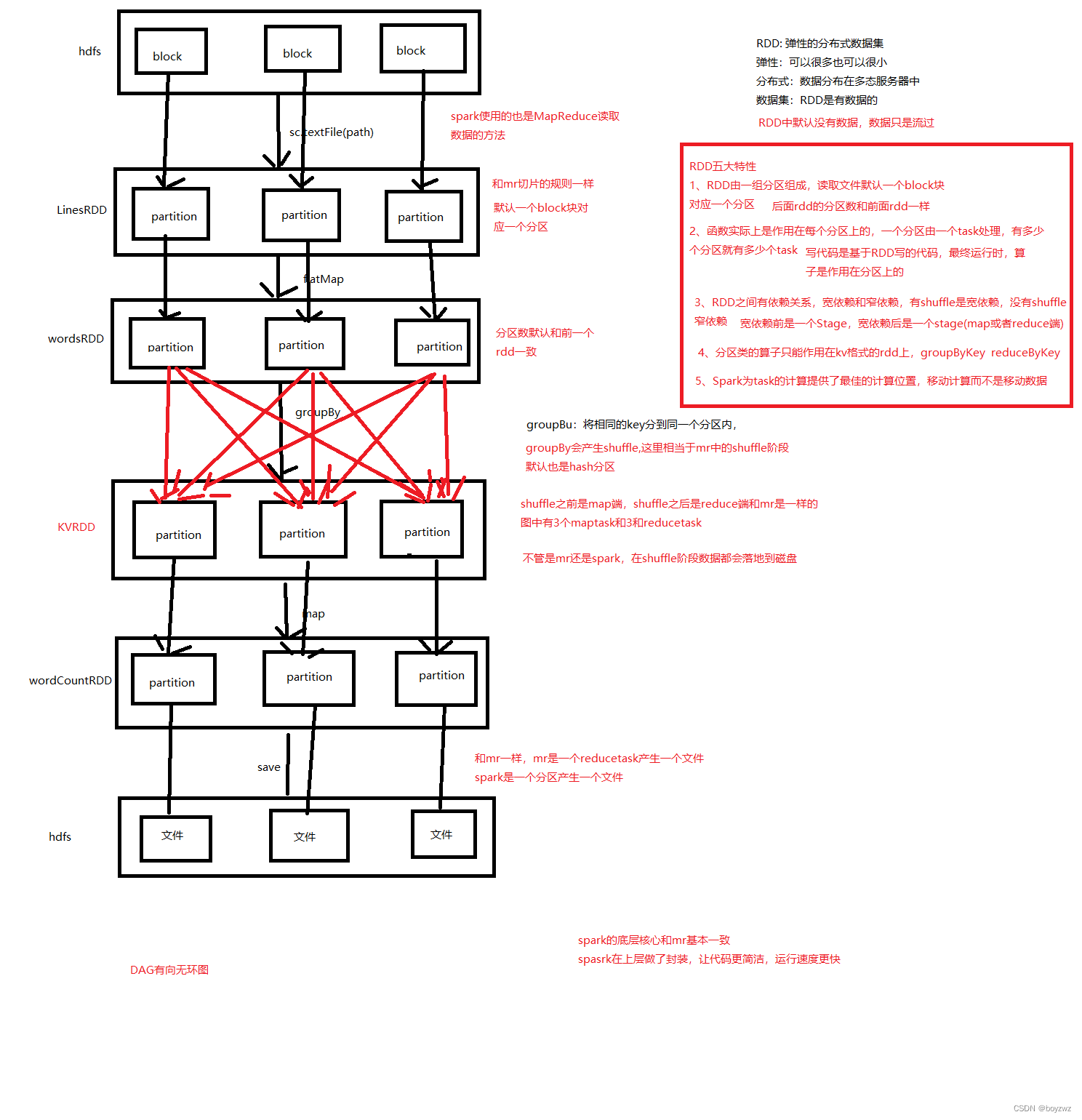
RDD五大特性
转换算子与操作算子
转换算子是懒执行,直到action算子触发才会执行;一个action算子触发一个job
/**
* 转换算子:将一个RDD转换成另一个RDD, 转换算子是懒执行,需要一个action算子来触发执行
* 操作算子:触发任务执行,一个action算子会触发一次任务执行, 同时每一个ation算子都会触发前面的代码执行
*
*/
println("map之前")
val studnetRDD: RDD[(String, String, Int, String, String)] = linesRDD
.map(_.split(","))
.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
println("=======map============")
(id, name, age.toInt, gender, clazz)
}
println("map之后")
studnetRDD.foreach(println)
println("=" * 100)
studnetRDD.foreach(println)
/**
* action算子,action算子的返回值不是一个rdd, 每一个action算子都会触发一个job执行
* foreach:循环RDD
* saveAsTextFile:保持数据
* count:统计行数
* collect:将rdd转换成集合
* take:取top
* reduce:全局聚合
* sum:求和,rdd必须可以求和
*
*/
//保持数据
studnetRDD.saveAsTextFile("data/temp")
//统计RDD行数
val count: Long = studnetRDD.count()
println(count)
/**
* 将rdd转换成数组
*
* 当处理的数据量很大时,会导致内存溢出
*/
val studentArr: Array[(String, String, Int, String, String)] = studnetRDD.collect()
//取top
val top: Array[(String, String, Int, String, String)] = studnetRDD.take(100)数据缓存
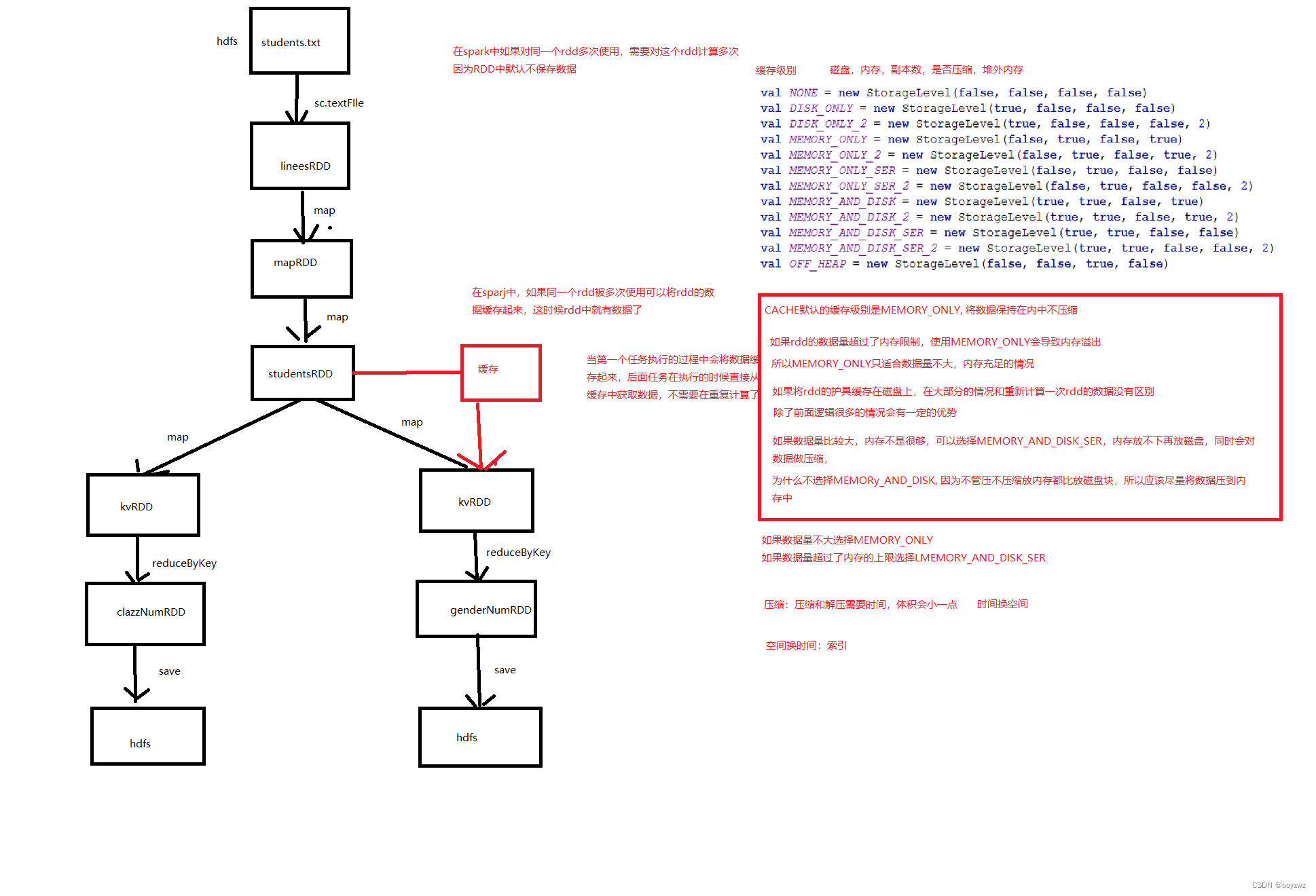
对于一个RDD(studentRDD)进行多次操作,则该RDD每次都会重新读取文件进行计算,因为RDD中默认不保存数据,数据只是从RDD一条一条流过,所以下次再对该RDD操作时,它会重新计算获取数据
RDD若使用多次,可将RDD的数据进行缓存,此时RDD中就有数据,下面对该RDD进行操作时,可直接使用RDD中的数据,该RDD不用再重复计算
//设置checkpoint保存路径
sc.setCheckpointDir("data/checkpoint")
//读取学生表数据
val linesRDD: RDD[String] = sc.textFile("data/students.txt")
//整理取出字段
val mapRDD: RDD[Array[String]] = linesRDD.map(_.split(","))
val studnetRDD: RDD[(String, String, Int, String, String)] = mapRDD.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
println("=======map============")
(id, name, age.toInt, gender, clazz)
}
/**
* 对多次使用的RDD进行缓存
*
*/
//缓存再内存中
//studnetRDD.cache()
//内存放不下放磁盘,对数据做压缩
// studnetRDD.persist(StorageLevel.MEMORY_AND_DISK_SER)
//studnetRDD.persist(StorageLevel.MEMORY_AND_DISK)
/**
* checkpoint:将rdd的数据缓存到hdfs中,任务失败了数据也不会丢失
* cache是将数据缓存再spark执行的服务器的内存或者磁盘上,如果任务执行失败数据就没了
* persist是将数据缓存在内存或磁盘中,临时存储
* checkpoint: 主要是再spark streaming中使用,用来保证任务的高可用
* checkpoint:为了数据安全,会单独新开一个进程再执行一遍RDD缓存数据
* 为了提高效率,可以结合cache 和checkpoint一起使用,则checkpoint就不会再执行一遍RDD
*/
studnetRDD.checkpoint()
//1、统计班级人数
studnetRDD
.map {
case (_, _, _, _, clazz: String) =>
(clazz, 1)
}
.reduceByKey(_ + _)
.saveAsTextFile("data/clazz_num")
println("=" * 100)
//统计性别的人数
studnetRDD
.map {
case (_, _, _, gender: String, _) =>
(gender, 1)
}
.reduceByKey(_ + _)
.saveAsTextFile("data/gender_num")
//统计年龄的人数
studnetRDD
.map {
case (_, _, age: Int, _, _) =>
(age, 1)
}
.reduceByKey(_ + _)
.saveAsTextFile("data/age_num")cache:数据缓存在内存中
checkpoint:缓存在hdfs上,需设置hdfs路径;多用于spark streaming
存在多个缓存级别;SER:压缩
累加器
//再算子内对算子外的一个普通变量进行累加,再算子外读不到累加结果
//因为算子内的代码运行再Executor,算子外的代码运行再Driver
//算子内的变量只是一个变量副本
/**
* 累加器
*
*/
//1、定义累加器
val accumulator: LongAccumulator = sc.longAccumulator
val mapRDD: RDD[String] = studentsRDD.map(stu => {
//2、对累累加器进行累加
accumulator.add(1)
stu
})
mapRDD.foreach(println)
//3、再Driver端读取累加结果
println(s"accumulator:${accumulator.value}")广播变量
/**
* 广播变量
* 当在算子内使用算子外的一个比较大的变量时,可以将这个变量广播出去,可以减少变量的副本数
*
*/
//读取学生表,以学号作为key构建一个map集合
val studentMap: Map[String, String] = Source
.fromFile("data/students.txt")
.getLines()
.toList
.map(stu => {
val ud: String = stu.split(",")(0)
(ud, stu)
})
.toMap
val scoresRDD: RDD[String] = sc.textFile("data/score.txt", 10)
println(s"scoresRDD:${scoresRDD.getNumPartitions}")
/**
* 关联学生表和分数表
* 循环分数表,使用学号到学生表的mao集合中查询学生的信息
*
*/
/**
* 将Driver端的一个普通变量广播到Executor端
*
*/
val broadCastMap: Broadcast[Map[String, String]] = sc.broadcast(studentMap)
val joinRDD: RDD[(String, String)] = scoresRDD.map(sco => {
val id: String = sco.split(",")(0)
//使用学号到学生表中获取学生的信息
/**
* 在算子内使用广播变量
* 1、当第一个task在执行过程中如果使用了广播变量,会向Executor获取广播变量
* 2、如果Executor中没有这个广播变量,Executor会去Driver端获取
* 3、如果下一个task再使用到这个广播变量就可以直接用了
*
*/
//在算子内获取广播变量
val map: Map[String, String] = broadCastMap.value
val studentInfo: String = map.getOrElse(id, "默认值")
(sco, studentInfo)
})
joinRDD.foreach(println)spark的运行模式
1、 local 本地模式
该模式主要用作测试用,一般编写的 spark 程序,将 master 设置为 local 或者 local[n],以本地模式运行,所有的代码都在一个 Jvm 里面。
2、 Mesos 模式
和 yarn 一样,Mesos 中,Spark 的资源管理从 Standalone 的 Master 转移到 Mesos Manager 中。
3、 Standalone 模式
该模式由 Spark 自带的集群管理模式,不依赖外部的资源管理器,由 Master 负责资源的分配管理,Worker 负责运行 Executor ,具体的运行过程可参考之前介绍 Spark 运行模式的篇章。
4、 yarn 模式
该模式由 yarn 负责管理整个集群资源,不再有 Master 和 Worker,根据 yarn-client 和 yarn-cluster 的不同。
yarn-client 中 driver运行在本地客户端,负责调度application,会与yarn集群产生大量的网络通信,但本地可以看见日志。
yarn-cluster 中 driver运行在yarn集群中,看不见日志。















 1430
1430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









