







前两章讨论支持向量机时,假设了数据最终是能完全被分开,即数据在原始特征空间或映射到高维特征空间之后能够完全正确分类。但是,这样绝对的分类存在一个明显的问题,如果模型中存在异常点,即使高维映射之后,能够完全正确分类,也可能导致模型复杂度过高,模型过拟合。虽然训练出来的模型能够在训练集上表现很好,但其泛化能力会很差。
如下图所示,明显蓝色框标记的两个白色点和两个红色点都是异常点,如果通过硬间隔SVM我们会得到右上角的分类效果,而采用高斯核则会得到左下角的结果。这两种分类器都能够将训练样本完全正确分类,但是这与我们人眼所观测到的分类器明显存在差异,如果应用这两个分类器在测试集上进行测试,有可能出现很大的误差。我们认为最恰当的应该还是类似于右下角的软间隔分类器。
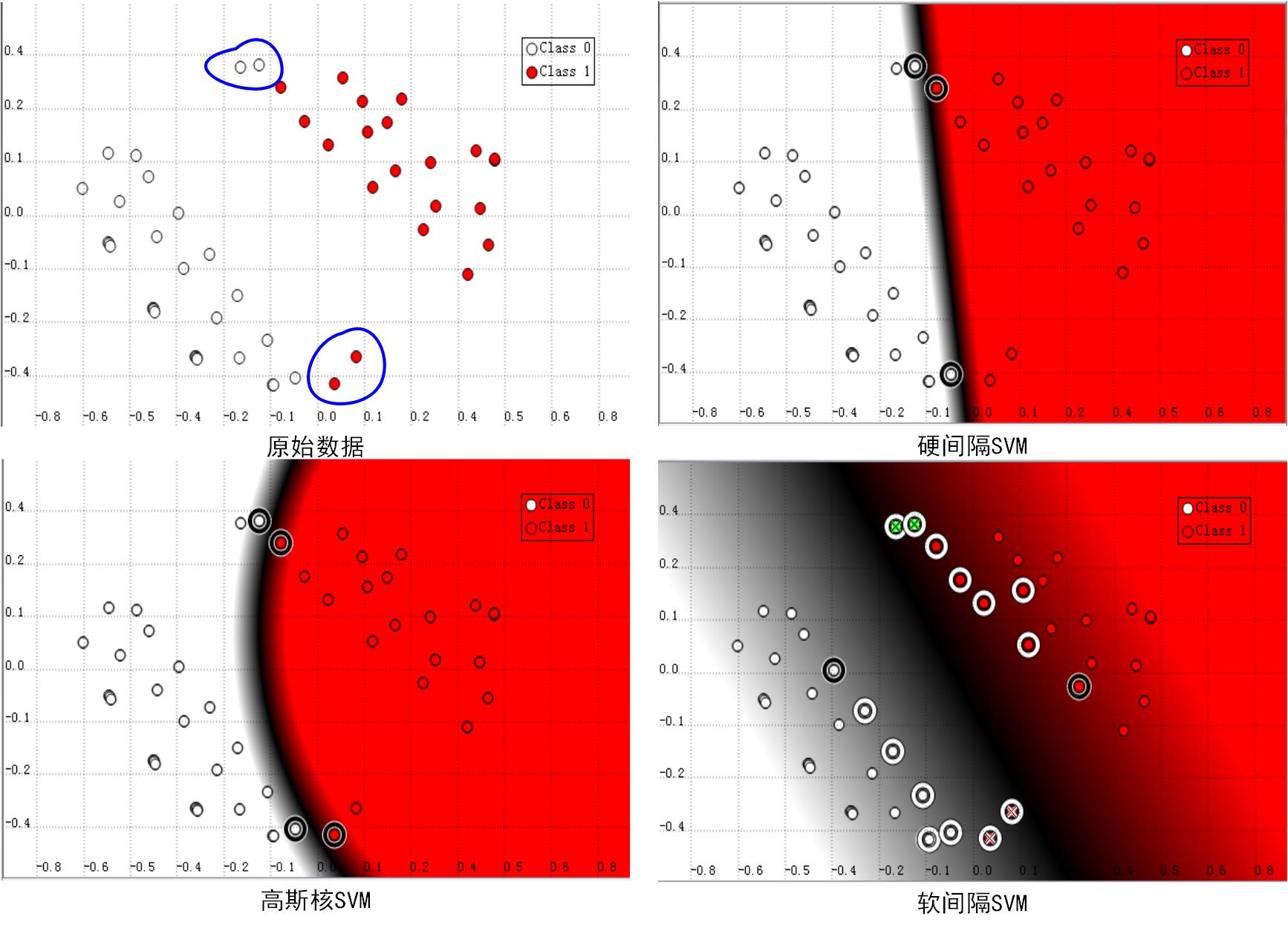
也就是说,在某种情况下,训练集数据存在一定的异常点,如果将这些异常点取出后,我们能够得到更好的模型。那么,如何将这些异常点去的影响去除呢?在SVM中我们通过引入松弛变量来解决这个问题。为了更好地理解松弛变量的含义,我们在此类比逻辑回归的损失函数。
逻辑回归
之所以在这里又引出logistic回归,一方面是为了后面比较两者的应用环境,更重要的则是通过损失函数对比,感性认识支持向量中目标函数的意义,方便更好的调试SVM模型中的各项参数。
首先我们回顾一下logistic回归中损失函数的定义:
J(θ)=1m∑i=1m[−yiloghθ(x(i))−(1−yi)log(1−hθ(x(i)))]+λ2m∑j=1Nθ2j
其中,原始的error项 −yiloghθ(x(i))−(1−yi)log(1−hθ(x(i))) 如下图所示,对于正样本而言, θTx 越大,预测函数 hθ(x) 越接近1, 即与正样本的差越小;同理,我们也可以这么理解负样本预测值的代价。
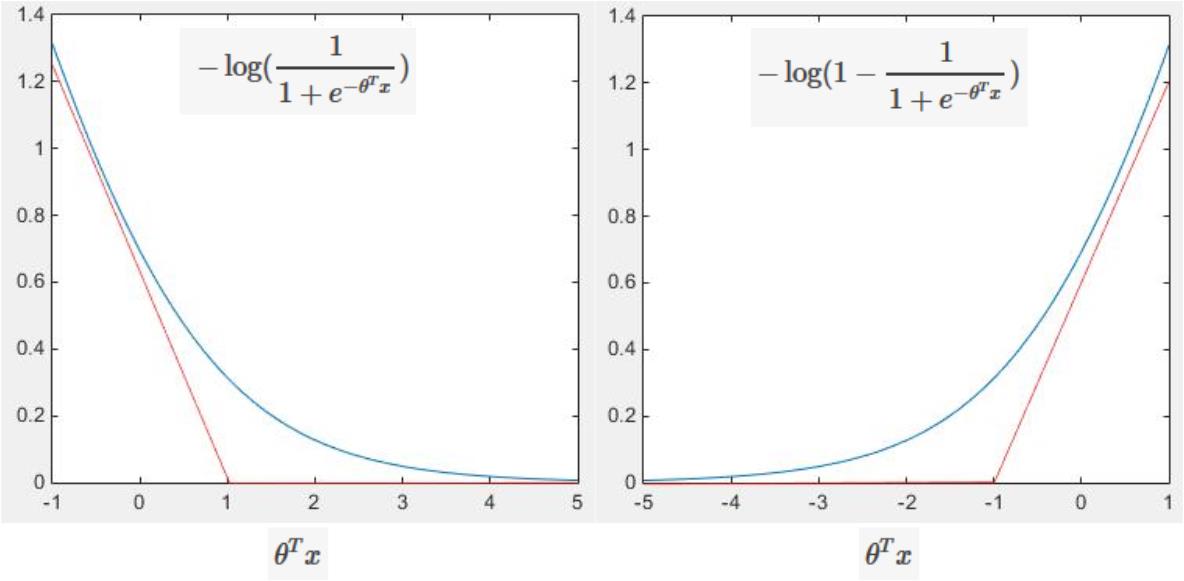
通过上面的分析,我们可以重新定义原始的损失函数为:
Eϵ(f(x)−y)={
0,|f(x)−y|−ϵ,|f(x)−y|<ϵotherwise
因此,带正则化的损失函数可以定义为:
J(θ)=C
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









