







知识点
- 聚类的指标
- 聚类常见算法:kmeans聚类、dbscan聚类、层次聚类
- 三种算法对应的流程
KMeans 聚类
算法原理
KMeans 是一种基于距离的聚类算法,需要预先指定聚类个数,即 `k`。其核心步骤如下:
1. 随机选择 `k` 个样本点作为初始质心(簇中心)。
2. 计算每个样本点到各个质心的距离,将样本点分配到距离最近的质心所在的簇。
3. 更新每个簇的质心为该簇内所有样本点的均值。
4. 重复步骤 2 和 3,直到质心不再变化或达到最大迭代次数为止。
确定簇数的方法:肘部法
- **肘部法(Elbow Method)** 是一种常用的确定 `k` 值的方法。
- 原理:通过计算不同 `k` 值下的簇内平方和(Within-Cluster Sum of Squares, WCSS),绘制 `k` 与 WCSS 的关系图。
- 选择标准:在图中找到“肘部”点,即 WCSS 下降速率明显减缓的 `k` 值,通常认为是最佳簇数。这是因为增加 `k` 值带来的收益(WCSS 减少)在该点后变得不显著。
KMeans 算法的优缺点
优点
- **简单高效**:算法实现简单,计算速度快,适合处理大规模数据集。
- **适用性强**:对球形或紧凑的簇效果较好,适用于特征空间中簇分布较为均匀的数据。
- **易于解释**:聚类结果直观,簇中心具有明确的物理意义。
缺点
- **需预先指定 `k` 值**:对簇数量 `k` 的选择敏感,不合适的 `k` 会导致聚类效果较差。
- **对初始质心敏感**:初始质心的随机选择可能导致结果不稳定或陷入局部最优(可通过 KMeans++ 初始化方法缓解)。
- **对噪声和异常值敏感**:异常值可能会显著影响质心的位置,导致聚类结果失真。
- **不适合非球形簇**:对非线性可分或形状复杂的簇效果较差,无法处理簇密度不均的情况。
聚类的流程
- 标准化数据
- 选择合适的算法,根据评估指标调参( )
KMeans 和层次聚类的参数是K值,选完k指标就确定
DBSCAN 的参数是 eps 和min_samples,选完他们出现k和评估指标
以及层次聚类的 linkage准则等都需要仔细调优。
除了经典的评估指标,还需要关注聚类出来每个簇对应的样本个数,避免太少没有意义。
- 将聚类后的特征添加到原数据中
- 原则t-sne或者pca进行2D或3D可视化
作业: 对心脏病数据集进行聚类。
# 先运行之前预处理好的代码
import pandas as pd
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings("ignore")
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('heart.csv') #读取数据
data.head() #查看数据的前五行
from sklearn.model_selection import train_test_split
X = data.drop(['target'], axis=1) # 特征,axis=1表示按列删除
y = data['target'] # 标签
# # 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns
# 标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_scaledimport numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns
# 评估不同 k 值下的指标
k_range = range(2, 11) # 测试 k 从 2 到 10
inertia_values = []
silhouette_scores = []
ch_scores = []
db_scores = []
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
inertia_values.append(kmeans.inertia_) # 惯性(肘部法则)
silhouette = silhouette_score(X_scaled, kmeans_labels) # 轮廓系数
silhouette_scores.append(silhouette)
ch = calinski_harabasz_score(X_scaled, kmeans_labels) # CH 指数
ch_scores.append(ch)
db = davies_bouldin_score(X_scaled, kmeans_labels) # DB 指数
db_scores.append(db)
print(f"k={k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")
# 绘制评估指标图
plt.figure(figsize=(15, 10))
# 肘部法则图(Inertia)
plt.subplot(2, 2, 1)
plt.plot(k_range, inertia_values, marker='o')
plt.title('肘部法则确定最优聚类数 k(惯性,越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('惯性')
plt.grid(True)
# 轮廓系数图
plt.subplot(2, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o', color='orange')
plt.title('轮廓系数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('轮廓系数')
plt.grid(True)
# CH 指数图
plt.subplot(2, 2, 3)
plt.plot(k_range, ch_scores, marker='o', color='green')
plt.title('Calinski-Harabasz 指数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('CH 指数')
plt.grid(True)
# DB 指数图
plt.subplot(2, 2, 4)
plt.plot(k_range, db_scores, marker='o', color='red')
plt.title('Davies-Bouldin 指数确定最优聚类数 k(越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('DB 指数')
plt.grid(True)
plt.tight_layout()
plt.show()k=2, 惯性: 3331.64, 轮廓系数: 0.166, CH 指数: 54.87, DB 指数: 2.209
k=3, 惯性: 3087.69, 轮廓系数: 0.112, CH 指数: 41.36, DB 指数: 2.544
k=4, 惯性: 2892.52, 轮廓系数: 0.118, CH 指数: 36.06, DB 指数: 2.175
k=5, 惯性: 2814.65, 轮廓系数: 0.094, CH 指数: 29.76, DB 指数: 2.386
k=6, 惯性: 2673.22, 轮廓系数: 0.095, CH 指数: 28.13, DB 指数: 2.377
k=7, 惯性: 2596.68, 轮廓系数: 0.088, CH 指数: 25.50, DB 指数: 2.290
k=8, 惯性: 2464.39, 轮廓系数: 0.115, CH 指数: 25.22, DB 指数: 2.136
k=9, 惯性: 2415.63, 轮廓系数: 0.105, CH 指数: 23.18, DB 指数: 2.133
k=10, 惯性: 2337.41, 轮廓系数: 0.111, CH 指数: 22.31, DB 指数: 2.056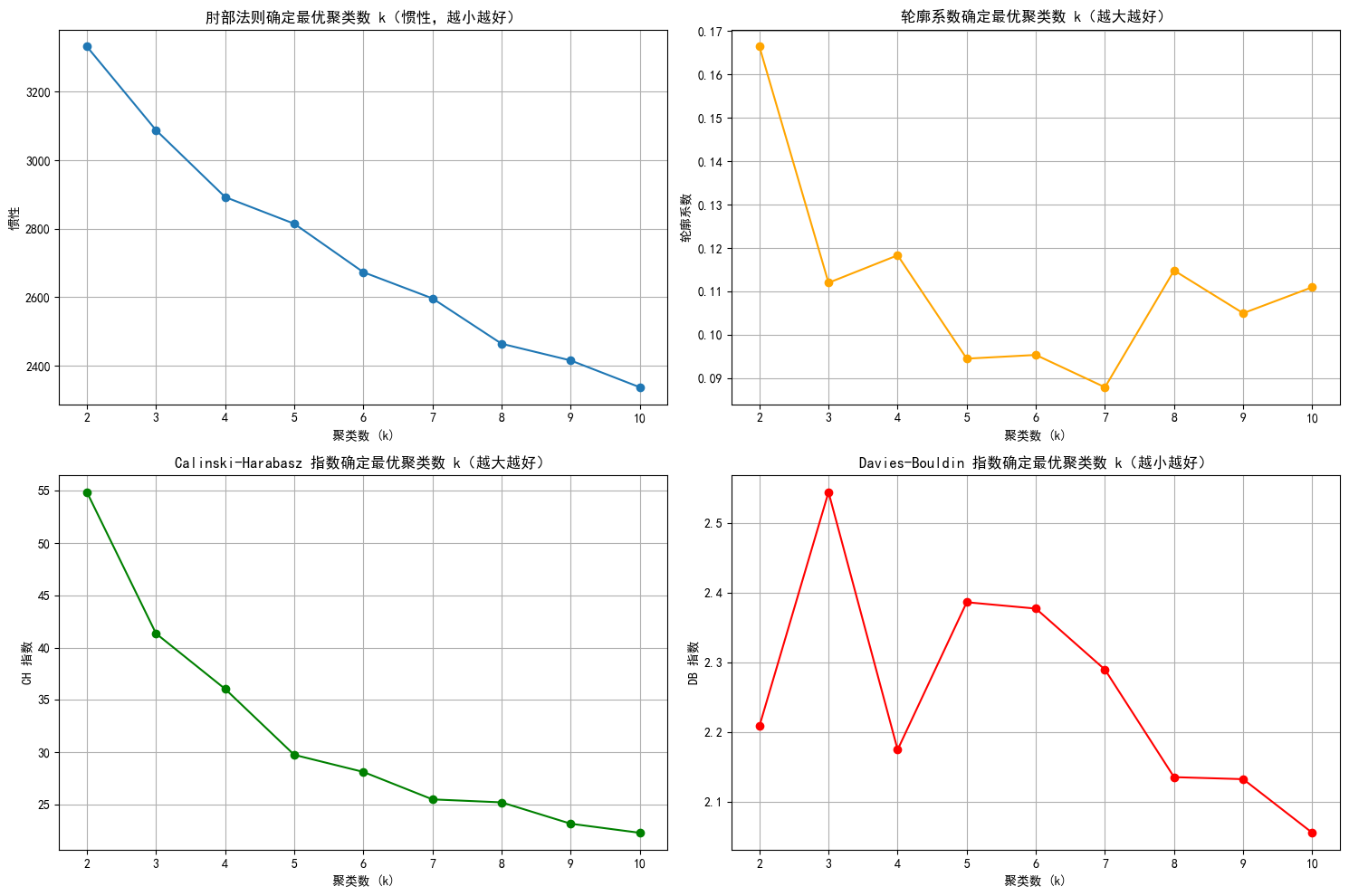
# 提示用户选择 k 值
selected_k = 4 # 这里可以根据评估结果选择合适的 k 值
# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels
# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()
# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())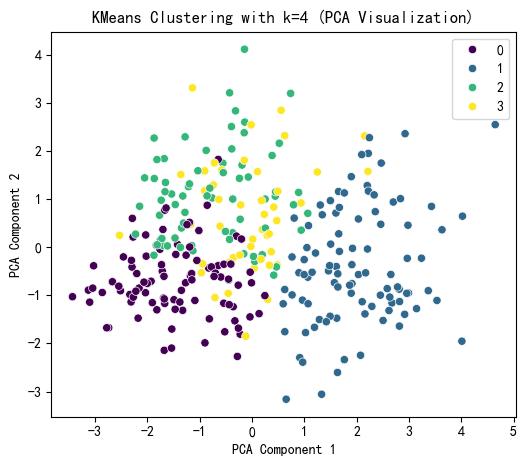
KMeans Cluster labels (k=4) added to X:
KMeans_Cluster
1 95
0 94
2 69
3 45
Name: count, dtype: int64DBSCAN聚类
import numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns
# 评估不同 eps 和 min_samples 下的指标
# eps这个参数表示邻域的半径,min_samples表示一个点被认为是核心点所需的最小样本数。
# min_samples这个参数表示一个核心点所需的最小样本数。
eps_range = np.arange(0.3, 0.8, 0.1) # 测试 eps 从 0.3 到 0.7
min_samples_range = range(2, 11) # 测试 min_samples 从 3 到 7
results = []
for eps in eps_range:
for min_samples in min_samples_range:
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
dbscan_labels = dbscan.fit_predict(X_scaled)
# 计算簇的数量(排除噪声点 -1)
n_clusters = len(np.unique(dbscan_labels)) - (1 if -1 in dbscan_labels else 0)
# 计算噪声点数量
n_noise = list(dbscan_labels).count(-1)
# 只有当簇数量大于 1 且有有效簇时才计算评估指标
if n_clusters > 1:
# 排除噪声点后计算评估指标
mask = dbscan_labels != -1
if mask.sum() > 0: # 确保有非噪声点
silhouette = silhouette_score(X_scaled[mask], dbscan_labels[mask])
ch = calinski_harabasz_score(X_scaled[mask], dbscan_labels[mask])
db = davies_bouldin_score(X_scaled[mask], dbscan_labels[mask])
results.append({
'eps': eps,
'min_samples': min_samples,
'n_clusters': n_clusters,
'n_noise': n_noise,
'silhouette': silhouette,
'ch_score': ch,
'db_score': db
})
print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, "
f"轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")
else:
print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, 无法计算评估指标")
# 将结果转为 DataFrame 以便可视化和选择参数
results_df = pd.DataFrame(results)eps=0.3, min_samples=2, 簇数: 2, 噪声点: 299, 轮廓系数: 0.980, CH 指数: 2499.86, DB 指数: 0.020
eps=0.3, min_samples=3, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.3, min_samples=4, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.3, min_samples=5, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.3, min_samples=6, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.3, min_samples=7, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.3, min_samples=8, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.3, min_samples=9, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.3, min_samples=10, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.4, min_samples=2, 簇数: 2, 噪声点: 299, 轮廓系数: 0.980, CH 指数: 2499.86, DB 指数: 0.020
eps=0.4, min_samples=3, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.4, min_samples=4, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.4, min_samples=5, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.4, min_samples=6, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.4, min_samples=7, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.4, min_samples=8, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.4, min_samples=9, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.4, min_samples=10, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.5, min_samples=2, 簇数: 3, 噪声点: 297, 轮廓系数: 0.940, CH 指数: 622.53, DB 指数: 0.075
eps=0.5, min_samples=3, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.5, min_samples=4, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.5, min_samples=5, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.5, min_samples=6, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.5, min_samples=7, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.5, min_samples=8, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.5, min_samples=9, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.5, min_samples=10, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.6, min_samples=2, 簇数: 3, 噪声点: 297, 轮廓系数: 0.940, CH 指数: 622.53, DB 指数: 0.075
eps=0.6, min_samples=3, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.6, min_samples=4, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.6, min_samples=5, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.6, min_samples=6, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.6, min_samples=7, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.6, min_samples=8, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.6, min_samples=9, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.6, min_samples=10, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.7, min_samples=2, 簇数: 3, 噪声点: 297, 轮廓系数: 0.940, CH 指数: 622.53, DB 指数: 0.075
eps=0.7, min_samples=3, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.7, min_samples=4, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.7, min_samples=5, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.7, min_samples=6, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.7, min_samples=7, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.7, min_samples=8, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.7, min_samples=9, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=0.7, min_samples=10, 簇数: 0, 噪声点: 303, 无法计算评估指标print(results_df)# 绘制评估指标图,增加点论文中的工作量
plt.figure(figsize=(15, 10))
# 轮廓系数图
plt.subplot(2, 2, 1)
for min_samples in min_samples_range:
subset = results_df[results_df['min_samples'] == min_samples] #
plt.plot(subset['eps'], subset['silhouette'], marker='o', label=f'min_samples={min_samples}')
plt.title('轮廓系数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('轮廓系数')
plt.legend()
plt.grid(True)
# CH 指数图
plt.subplot(2, 2, 2)
for min_samples in min_samples_range:
subset = results_df[results_df['min_samples'] == min_samples]
plt.plot(subset['eps'], subset['ch_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Calinski-Harabasz 指数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('CH 指数')
plt.legend()
plt.grid(True)
# DB 指数图
plt.subplot(2, 2, 3)
for min_samples in min_samples_range:
subset = results_df[results_df['min_samples'] == min_samples]
plt.plot(subset['eps'], subset['db_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Davies-Bouldin 指数确定最优参数(越小越好)')
plt.xlabel('eps')
plt.ylabel('DB 指数')
plt.legend()
plt.grid(True)
# 簇数量图
plt.subplot(2, 2, 4)
for min_samples in min_samples_range:
subset = results_df[results_df['min_samples'] == min_samples]
plt.plot(subset['eps'], subset['n_clusters'], marker='o', label=f'min_samples={min_samples}')
plt.title('簇数量变化')
plt.xlabel('eps')
plt.ylabel('簇数量')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()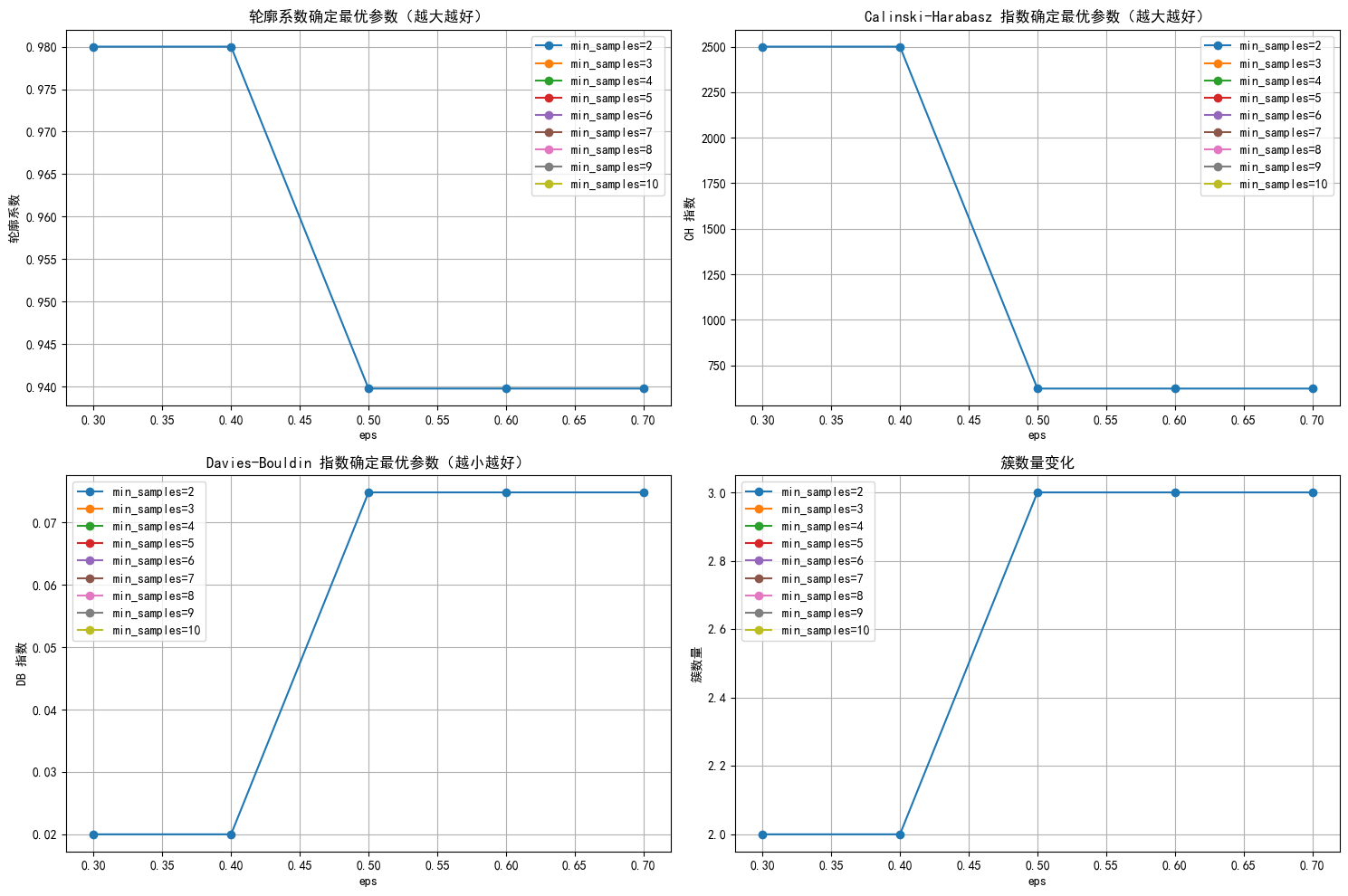
# 选择 eps 和 min_samples 值(根据图表选择最佳参数)
selected_eps = 0.4 # 根据图表调整
selected_min_samples = 2 # 根据图表调整
# 使用选择的参数进行 DBSCAN 聚类
dbscan = DBSCAN(eps=selected_eps, min_samples=selected_min_samples)
dbscan_labels = dbscan.fit_predict(X_scaled)
X['DBSCAN_Cluster'] = dbscan_labels
# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# DBSCAN 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=dbscan_labels, palette='viridis')
plt.title(f'DBSCAN Clustering with eps={selected_eps}, min_samples={selected_min_samples} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()
# 打印 DBSCAN 聚类标签的分布
print(f"DBSCAN Cluster labels (eps={selected_eps}, min_samples={selected_min_samples}) added to X:")
print(X[['DBSCAN_Cluster']].value_counts())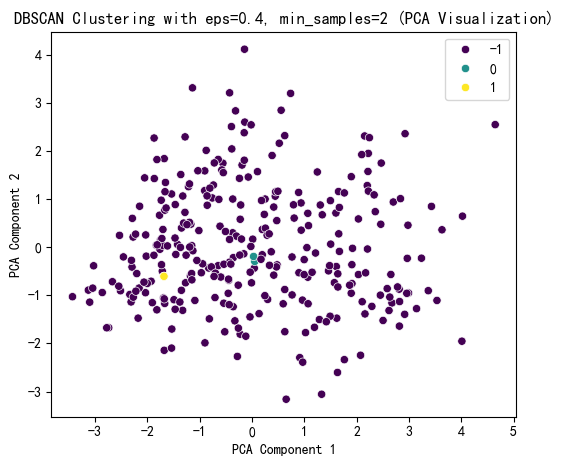
DBSCAN Cluster labels (eps=0.4, min_samples=2) added to X:
DBSCAN_Cluster
-1 299
0 2
1 2
Name: count, dtype: int64
层次聚类
Agglomerative Clustering 是一种自底向上的层次聚类方法,初始时每个样本是一个簇,然后逐步合并最相似的簇,直到达到指定的簇数量或满足停止条件。由于它需要指定簇数量(类似于 KMeans),我将通过测试不同的簇数量 n_clusters 来评估聚类效果,并使用轮廓系数(Silhouette Score)、CH 指数(Calinski-Harabasz Index)和 DB 指数(Davies-Bouldin Index)作为评估指标。
import numpy as np
import pandas as pd
from sklearn.cluster import AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns
# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 评估不同 n_clusters 下的指标
n_clusters_range = range(2, 11) # 测试簇数量从 2 到 10
silhouette_scores = []
ch_scores = []
db_scores = []
for n_clusters in n_clusters_range:
agglo = AgglomerativeClustering(n_clusters=n_clusters, linkage='ward') # 使用 Ward 准则合并簇
agglo_labels = agglo.fit_predict(X_scaled)
# 计算评估指标
silhouette = silhouette_score(X_scaled, agglo_labels)
ch = calinski_harabasz_score(X_scaled, agglo_labels)
db = davies_bouldin_score(X_scaled, agglo_labels)
silhouette_scores.append(silhouette)
ch_scores.append(ch)
db_scores.append(db)
print(f"n_clusters={n_clusters}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")
# 绘制评估指标图
plt.figure(figsize=(15, 5))
# 轮廓系数图
plt.subplot(1, 3, 1)
plt.plot(n_clusters_range, silhouette_scores, marker='o')
plt.title('轮廓系数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('轮廓系数')
plt.grid(True)
# CH 指数图
plt.subplot(1, 3, 2)
plt.plot(n_clusters_range, ch_scores, marker='o')
plt.title('Calinski-Harabasz 指数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('CH 指数')
plt.grid(True)
# DB 指数图
plt.subplot(1, 3, 3)
plt.plot(n_clusters_range, db_scores, marker='o')
plt.title('Davies-Bouldin 指数确定最优簇数(越小越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('DB 指数')
plt.grid(True)
plt.tight_layout()
plt.show()
n_clusters=2, 轮廓系数: 0.336, CH 指数: 685.66, DB 指数: 2.659
n_clusters=3, 轮廓系数: 0.242, CH 指数: 659.40, DB 指数: 2.327
n_clusters=4, 轮廓系数: 0.254, CH 指数: 565.74, DB 指数: 2.160
n_clusters=5, 轮廓系数: 0.276, CH 指数: 519.91, DB 指数: 2.110
n_clusters=6, 轮廓系数: 0.284, CH 指数: 494.24, DB 指数: 1.860
n_clusters=7, 轮廓系数: 0.295, CH 指数: 482.64, DB 指数: 1.680
n_clusters=8, 轮廓系数: 0.297, CH 指数: 479.17, DB 指数: 1.435
n_clusters=9, 轮廓系数: 0.301, CH 指数: 481.85, DB 指数: 1.283
n_clusters=10, 轮廓系数: 0.309, CH 指数: 489.27, DB 指数: 1.269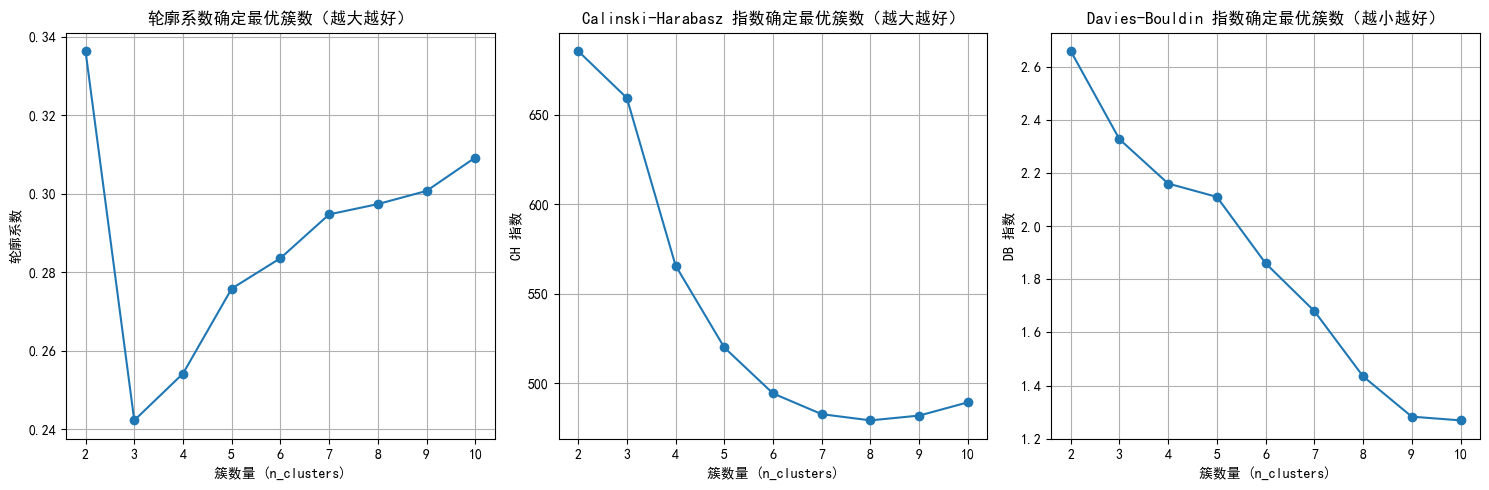
# 提示用户选择 n_clusters 值(这里可以根据图表选择最佳簇数)
selected_n_clusters = 10 # 示例值,根据图表调整
# 使用选择的簇数进行 Agglomerative Clustering 聚类
agglo = AgglomerativeClustering(n_clusters=selected_n_clusters, linkage='ward')
agglo_labels = agglo.fit_predict(X_scaled)
X['Agglo_Cluster'] = agglo_labels
# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# Agglomerative Clustering 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=agglo_labels, palette='viridis')
plt.title(f'Agglomerative Clustering with n_clusters={selected_n_clusters} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()
# 打印 Agglomerative Clustering 聚类标签的分布
print(f"Agglomerative Cluster labels (n_clusters={selected_n_clusters}) added to X:")
print(X[['Agglo_Cluster']].value_counts()) 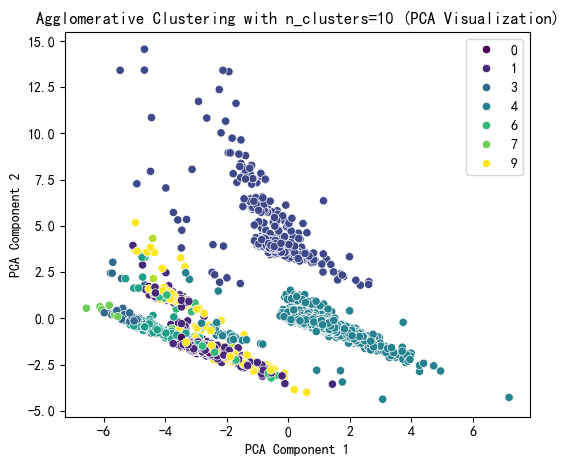
Agglomerative Cluster labels (n_clusters=10) added to X:
Agglo_Cluster
4 5230
1 778
2 771
9 409
5 127
6 96
0 37
3 34
7 10
8 8
dtype: int64
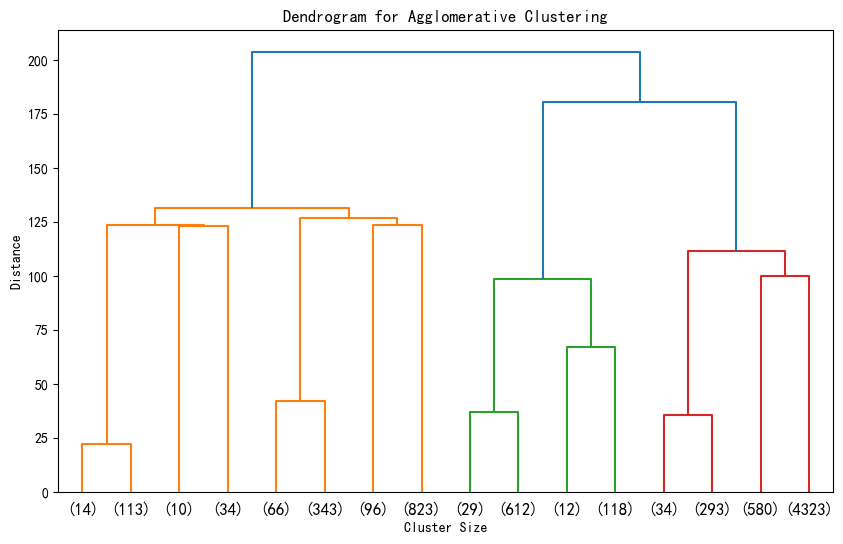
# 层次聚类的树状图可视化
from scipy.cluster import hierarchy
import matplotlib.pyplot as plt
# 假设 X_scaled 是标准化后的数据
# 计算层次聚类的链接矩阵
Z = hierarchy.linkage(X_scaled, method='ward') # 'ward' 是常用的合并准则
# 绘制树状图
plt.figure(figsize=(10, 6))
hierarchy.dendrogram(Z, truncate_mode='level', p=3) # p 控制显示的层次深度
# hierarchy.dendrogram(Z, truncate_mode='level') # 不用p这个参数,可以显示全部的深度
plt.title('Dendrogram for Agglomerative Clustering')
plt.xlabel('Cluster Size')
plt.ylabel('Distance')
plt.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









