







知识点回顾:
- PyTorch和cuda的安装
- 查看显卡信息的命令行命令(cmd中使用)
- cuda的检查
- 简单神经网络的流程
- 数据预处理(归一化、转换成张量)
- 模型的定义
- 继承nn.Module类
- 定义每一个层
- 定义前向传播流程
- 定义损失函数和优化器
- 定义训练流程
- 可视化loss过程
数据的准备
# 仍然用4特征,3分类的鸢尾花数据集作为我们今天的数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 打印下尺寸
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)# 归一化数据,神经网络对于输入数据的尺寸敏感,归一化是最常见的处理方式
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) #确保训练集和测试集是相同的缩放
# 将数据转换为 PyTorch 张量,因为 PyTorch 使用张量进行训练
# y_train和y_test是整数,所以需要转化为long类型,如果是float32,会输出1.0 0.0
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)模型架构定义
定义一个简单的全连接神经网络模型,包含一个输入层、一个隐藏层和一个输出层。
定义层数+定义前向传播顺序
import torch
import torch.nn as nn
import torch.optim as optimclass MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Module
def __init__(self): # 初始化函数
super(MLP, self).__init__() # 调用父类的初始化函数
# 前三行是八股文,后面的是自定义的
self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层
self.relu = nn.ReLU()
self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
# 实例化模型
model = MLP()模型训练(CPU版本)
定义损失函数和优化器
# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)
# # 使用自适应学习率的化器
# optimizer = optim.Adam(model.parameters(), lr=0.001)开始循环训练
实际上在训练的时候,可以同时观察每个epoch训练完后测试集的表现:测试集的loss和准确度
# 训练模型
num_epochs = 20000 # 训练的轮数
# 用于存储每个 epoch 的损失值
losses = []
for epoch in range(num_epochs): # range是从0开始,所以epoch是从0开始
# 前向传播
outputs = model.forward(X_train) # 显式调用forward函数
# outputs = model(X_train) # 常见写法隐式调用forward函数,其实是用了model类的__call__方法
loss = criterion(outputs, y_train) # output是模型预测值,y_train是真实标签
# 反向传播和优化
optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsize
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
# 记录损失值
losses.append(loss.item())
# 打印训练信息
if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')Epoch [100/20000], Loss: 1.0474
Epoch [200/20000], Loss: 0.9989
Epoch [300/20000], Loss: 0.9426
Epoch [400/20000], Loss: 0.8749
Epoch [500/20000], Loss: 0.8102
Epoch [600/20000], Loss: 0.7478
Epoch [700/20000], Loss: 0.6896
Epoch [800/20000], Loss: 0.6376
Epoch [900/20000], Loss: 0.5927
Epoch [1000/20000], Loss: 0.5545
Epoch [1100/20000], Loss: 0.5224
Epoch [1200/20000], Loss: 0.4950
Epoch [1300/20000], Loss: 0.4714
Epoch [1400/20000], Loss: 0.4508
Epoch [1500/20000], Loss: 0.4325
Epoch [1600/20000], Loss: 0.4158
Epoch [1700/20000], Loss: 0.4006
Epoch [1800/20000], Loss: 0.3865
Epoch [1900/20000], Loss: 0.3733
Epoch [2000/20000], Loss: 0.3608
Epoch [2100/20000], Loss: 0.3490
Epoch [2200/20000], Loss: 0.3378
Epoch [2300/20000], Loss: 0.3271
Epoch [2400/20000], Loss: 0.3168
Epoch [2500/20000], Loss: 0.3069
Epoch [2600/20000], Loss: 0.2975
Epoch [2700/20000], Loss: 0.2884
Epoch [2800/20000], Loss: 0.2797
Epoch [2900/20000], Loss: 0.2714
Epoch [3000/20000], Loss: 0.2634
Epoch [3100/20000], Loss: 0.2557
Epoch [3200/20000], Loss: 0.2484
Epoch [3300/20000], Loss: 0.2414
Epoch [3400/20000], Loss: 0.2347
Epoch [3500/20000], Loss: 0.2283
Epoch [3600/20000], Loss: 0.2222
Epoch [3700/20000], Loss: 0.2163
Epoch [3800/20000], Loss: 0.2107
Epoch [3900/20000], Loss: 0.2054
Epoch [4000/20000], Loss: 0.2002
Epoch [4100/20000], Loss: 0.1953
Epoch [4200/20000], Loss: 0.1907
Epoch [4300/20000], Loss: 0.1862
Epoch [4400/20000], Loss: 0.1819
Epoch [4500/20000], Loss: 0.1778
Epoch [4600/20000], Loss: 0.1739
Epoch [4700/20000], Loss: 0.1701
Epoch [4800/20000], Loss: 0.1665
Epoch [4900/20000], Loss: 0.1631
Epoch [5000/20000], Loss: 0.1598
Epoch [5100/20000], Loss: 0.1566
Epoch [5200/20000], Loss: 0.1536
Epoch [5300/20000], Loss: 0.1507
Epoch [5400/20000], Loss: 0.1479
Epoch [5500/20000], Loss: 0.1452
Epoch [5600/20000], Loss: 0.1427
Epoch [5700/20000], Loss: 0.1402
Epoch [5800/20000], Loss: 0.1378
Epoch [5900/20000], Loss: 0.1355
Epoch [6000/20000], Loss: 0.1334
Epoch [6100/20000], Loss: 0.1312
Epoch [6200/20000], Loss: 0.1292
Epoch [6300/20000], Loss: 0.1273
Epoch [6400/20000], Loss: 0.1254
Epoch [6500/20000], Loss: 0.1236
Epoch [6600/20000], Loss: 0.1218
Epoch [6700/20000], Loss: 0.1202
Epoch [6800/20000], Loss: 0.1185
Epoch [6900/20000], Loss: 0.1170
Epoch [7000/20000], Loss: 0.1155
Epoch [7100/20000], Loss: 0.1140
Epoch [7200/20000], Loss: 0.1126
Epoch [7300/20000], Loss: 0.1113
Epoch [7400/20000], Loss: 0.1099
Epoch [7500/20000], Loss: 0.1087
Epoch [7600/20000], Loss: 0.1074
Epoch [7700/20000], Loss: 0.1063
Epoch [7800/20000], Loss: 0.1051
Epoch [7900/20000], Loss: 0.1040
Epoch [8000/20000], Loss: 0.1029
Epoch [8100/20000], Loss: 0.1019
Epoch [8200/20000], Loss: 0.1009
Epoch [8300/20000], Loss: 0.0999
Epoch [8400/20000], Loss: 0.0989
Epoch [8500/20000], Loss: 0.0980
Epoch [8600/20000], Loss: 0.0971
Epoch [8700/20000], Loss: 0.0962
Epoch [8800/20000], Loss: 0.0954
Epoch [8900/20000], Loss: 0.0946
Epoch [9000/20000], Loss: 0.0938
Epoch [9100/20000], Loss: 0.0930
Epoch [9200/20000], Loss: 0.0923
Epoch [9300/20000], Loss: 0.0915
Epoch [9400/20000], Loss: 0.0908
Epoch [9500/20000], Loss: 0.0901
Epoch [9600/20000], Loss: 0.0895
Epoch [9700/20000], Loss: 0.0888
Epoch [9800/20000], Loss: 0.0882
Epoch [9900/20000], Loss: 0.0875
Epoch [10000/20000], Loss: 0.0869
Epoch [10100/20000], Loss: 0.0864
Epoch [10200/20000], Loss: 0.0858
Epoch [10300/20000], Loss: 0.0852
Epoch [10400/20000], Loss: 0.0847
Epoch [10500/20000], Loss: 0.0841
Epoch [10600/20000], Loss: 0.0836
Epoch [10700/20000], Loss: 0.0831
Epoch [10800/20000], Loss: 0.0826
Epoch [10900/20000], Loss: 0.0821
Epoch [11000/20000], Loss: 0.0817
Epoch [11100/20000], Loss: 0.0812
Epoch [11200/20000], Loss: 0.0808
Epoch [11300/20000], Loss: 0.0803
Epoch [11400/20000], Loss: 0.0799
Epoch [11500/20000], Loss: 0.0795
Epoch [11600/20000], Loss: 0.0790
Epoch [11700/20000], Loss: 0.0786
Epoch [11800/20000], Loss: 0.0783
Epoch [11900/20000], Loss: 0.0779
Epoch [12000/20000], Loss: 0.0775
Epoch [12100/20000], Loss: 0.0771
Epoch [12200/20000], Loss: 0.0768
Epoch [12300/20000], Loss: 0.0764
Epoch [12400/20000], Loss: 0.0761
Epoch [12500/20000], Loss: 0.0757
Epoch [12600/20000], Loss: 0.0754
Epoch [12700/20000], Loss: 0.0751
Epoch [12800/20000], Loss: 0.0748
Epoch [12900/20000], Loss: 0.0744
Epoch [13000/20000], Loss: 0.0741
Epoch [13100/20000], Loss: 0.0738
Epoch [13200/20000], Loss: 0.0735
Epoch [13300/20000], Loss: 0.0733
Epoch [13400/20000], Loss: 0.0730
Epoch [13500/20000], Loss: 0.0727
Epoch [13600/20000], Loss: 0.0724
Epoch [13700/20000], Loss: 0.0722
Epoch [13800/20000], Loss: 0.0719
Epoch [13900/20000], Loss: 0.0716
Epoch [14000/20000], Loss: 0.0714
Epoch [14100/20000], Loss: 0.0711
Epoch [14200/20000], Loss: 0.0709
Epoch [14300/20000], Loss: 0.0706
Epoch [14400/20000], Loss: 0.0704
Epoch [14500/20000], Loss: 0.0702
Epoch [14600/20000], Loss: 0.0699
Epoch [14700/20000], Loss: 0.0697
Epoch [14800/20000], Loss: 0.0695
Epoch [14900/20000], Loss: 0.0693
Epoch [15000/20000], Loss: 0.0691
Epoch [15100/20000], Loss: 0.0689
Epoch [15200/20000], Loss: 0.0687
Epoch [15300/20000], Loss: 0.0685
Epoch [15400/20000], Loss: 0.0683
Epoch [15500/20000], Loss: 0.0681
Epoch [15600/20000], Loss: 0.0679
Epoch [15700/20000], Loss: 0.0677
Epoch [15800/20000], Loss: 0.0675
Epoch [15900/20000], Loss: 0.0673
Epoch [16000/20000], Loss: 0.0671
Epoch [16100/20000], Loss: 0.0669
Epoch [16200/20000], Loss: 0.0668
Epoch [16300/20000], Loss: 0.0666
Epoch [16400/20000], Loss: 0.0664
Epoch [16500/20000], Loss: 0.0663
Epoch [16600/20000], Loss: 0.0661
Epoch [16700/20000], Loss: 0.0659
Epoch [16800/20000], Loss: 0.0658
Epoch [16900/20000], Loss: 0.0656
Epoch [17000/20000], Loss: 0.0655
Epoch [17100/20000], Loss: 0.0653
Epoch [17200/20000], Loss: 0.0651
Epoch [17300/20000], Loss: 0.0650
Epoch [17400/20000], Loss: 0.0649
Epoch [17500/20000], Loss: 0.0647
Epoch [17600/20000], Loss: 0.0646
Epoch [17700/20000], Loss: 0.0644
Epoch [17800/20000], Loss: 0.0643
Epoch [17900/20000], Loss: 0.0641
Epoch [18000/20000], Loss: 0.0640
Epoch [18100/20000], Loss: 0.0639
Epoch [18200/20000], Loss: 0.0637
Epoch [18300/20000], Loss: 0.0636
Epoch [18400/20000], Loss: 0.0635
Epoch [18500/20000], Loss: 0.0634
Epoch [18600/20000], Loss: 0.0632
Epoch [18700/20000], Loss: 0.0631
Epoch [18800/20000], Loss: 0.0630
Epoch [18900/20000], Loss: 0.0629
Epoch [19000/20000], Loss: 0.0627
Epoch [19100/20000], Loss: 0.0626
Epoch [19200/20000], Loss: 0.0625
Epoch [19300/20000], Loss: 0.0624
Epoch [19400/20000], Loss: 0.0623
Epoch [19500/20000], Loss: 0.0622
Epoch [19600/20000], Loss: 0.0621
Epoch [19700/20000], Loss: 0.0619
Epoch [19800/20000], Loss: 0.0618
Epoch [19900/20000], Loss: 0.0617
Epoch [20000/20000], Loss: 0.0616可视化结果
import matplotlib.pyplot as plt
# 可视化损失曲线
plt.plot(range(num_epochs), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()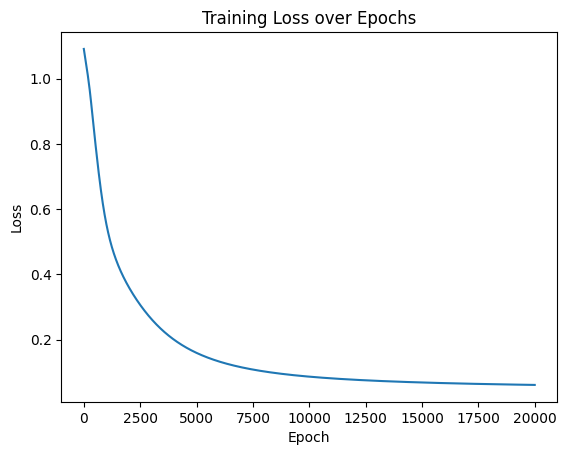

















 5428
5428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









