






这些肯定不全是自己的,但是参考别人的文章加上自己的独立思考,一定能有新的收获
这里主打讲一下写入流程的源码,以及给出自己的参考资料~ 然后谈一下自己rowkey设计的想法好了,其实我没设计过多少rowkey,每次都是业务自己设计的哈哈哈(然后一堆热点问题mmd)
所以规范业务的行为也是十分重要的,包括重要的列族设计,以及rowkey设计,如果业务不规范使用出问题了那就不是咱的问题
写流程概览图
(客户端连接zookeeper --> 寻找meta --> 找到对应的RS --> RS写入请求)
连接zookeeper就不再赘述了,那么meta怎么就知道你的region在哪里呢?
因为hbase:meta中的信息是这样的,一个region对应的RS以及regionInfo都会存在于meta中,所以zookeeper中找到meta表之后对meta进行一次扫描就知道region在哪里啦,当然meta信息是会被缓存的,不然每次都scan一次小心把meta扫坏了(不会的不会的!)

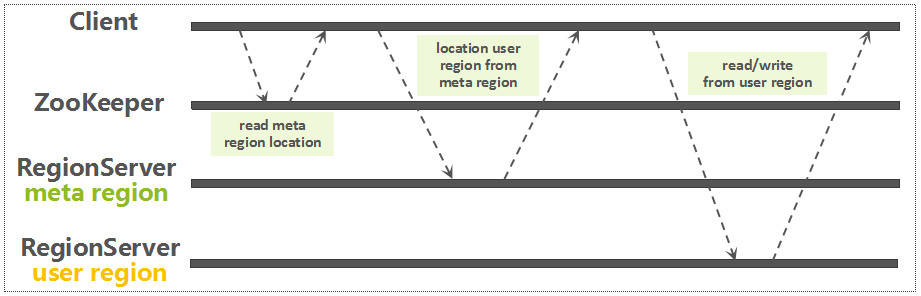
这里就不赘述其中的主体过程了:看getTableRegionsAndLocations方法即可,可以看出扫描scan的过程,然后将其缓存
batch Put写入
单条put写入即直接找到对应的region,发送到该regionServer即可
batch Put写入需要先找到对应的所有region,然后通过region对其中的RS进行分组,发往不同的RS进行相关的处理,这个地方每一个RS packet都需要一个RPC调用
所以连续发送300条单条put和批量300的put需要的RPC调用次数是差距很大的,不过客户端是可以进行缓存put的,但是这个缓存如果客户端宕机的话会丢失。但是batch size也不要太大了,因为RS处理每一个regionAction是串行处理的哟
通过RSRpcServices中的multi来处理批量请求,根据请求的类型进行不同的操作
RS传递给自家region进行mutate(其实就是写入啦),但是总感觉比write高级不少的样子
重点方法:processRowsWithLocks,这里就涉及核心的写入方式了
1.拿锁 包括行锁和region锁
acquiredRowLocks 以及 lock region
2.设置所有的写入时间为当前的系统时间(KV时间)
得到系统时间并且设置成即将写入的WAL的值
long now = EnvironmentEdgeManager.currentTime();
3.构建WALEDIT并且写入WAL,但是不需要同步即可进行下一步(高效生产消费者队列),写入WAL的时候,如果是multi那么所有的KV都会被构建为一条WALEDIT,这样回滚也会很方便
processor.preBatchMutate(this, walEdit);
walKey = new HLogKey(this.getRegionInfo().getEncodedNameAsBytes(),
this.htableDescriptor.getTableName(), WALKey.NO_SEQUENCE_ID, now,
processor.getClusterIds(), nonceGroup, nonce, mvcc);
txid = this.wal.append(this.htableDescriptor, this.getRegionInfo(),
walKey, walEdit, true);
4.开始mvcc事务
writeEntry = walKey.getWriteEntry();
mvccNum = walKey.getSequenceId();
5.写入memStore
for (Mutation m : mutations) {
// Handle any tag based cell features
rewriteCellTags(m.getFamilyCellMap(), m);
for (CellScanner cellScanner = m.cellScanner(); cellScanner.advance();) {
Cell cell = cellScanner.current();
CellUtil.setSequenceId(cell, mvccNum);
Store store = getStore(cell);
if (store == null) {
checkFamily(CellUtil.cloneFamily(cell));
// unreachable
}
addedSize += store.add(cell);
}
}
6.释放region锁和行锁
if (locked) {
this.updatesLock.readLock().unlock();
locked = false;
}
// 10. Release row lock(s)
releaseRowLocks(acquiredRowLocks);
7.sync WAL,WAL如果sync失败则直接回滚,包括memStore也需要回滚
syncOrDefer(txid, getEffectiveDurability(processor.useDurability()));
8.mvcc前进,此时数据才是真的可以被查询了
mvcc.completeAndWait(writeEntry);hhh本来准备打算仔细梳理一下流程的,但是发现非常非常繁琐,不如了解一个大概就行,如果哪天出现问题知道怎么排查就好!
之后的流程就是memStore的刷写以及写入HFile,然后是HFile的comapction,compaction会造成写入的二次放大,所以在设计上可以避免的事情就尽量避免~
参考资料:
HBase原理与实践















 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









