







前言
在如今的开发过程中,单节点的Elasticsearch肯定是支撑不了大数据量的,而且还存在单节点故障的问题,所以Elasticsearch也提供了集群功能,像其他中间件也基本都会考虑到这个问题
准备信息
首先, 由于我机器有限,我只能在本地开启虚拟机来进行支持,我这里本地开了3台,不知道怎么安装虚拟机的可以参考我之前的文章:https://blog.csdn.net/zxc_user/article/details/128652446
其次,你需要在每台服务上搭建单节点的Elasticsearch实例,这个也可以参考我之前写的搭建文章,地址:https://blog.csdn.net/zxc_user/article/details/128666834
准备上面的环境后就可以往下看了
必看
注意,以下搭建只是用于自己测试所用,如果是生产的,你还需要进行安全配置,单一部署等,各种节点都需要单独部署,比如master只是转发,Coordinating Node需要大量内存,Data需要落盘等等,要根据节点不一样的特性进行部署
节点概念下面会讲到,这里只是提示一下这只是个演示,生产需要增加安全配置
Elasticsearch集群
核心概念
集群
就是多个Elasticsearch节点整合在一起对外提供服务的服务,对用户来说是透明的,只有我们程序员才知道这个
节点
也就是集群中一个个Elasticsearch实例,节点类型如下
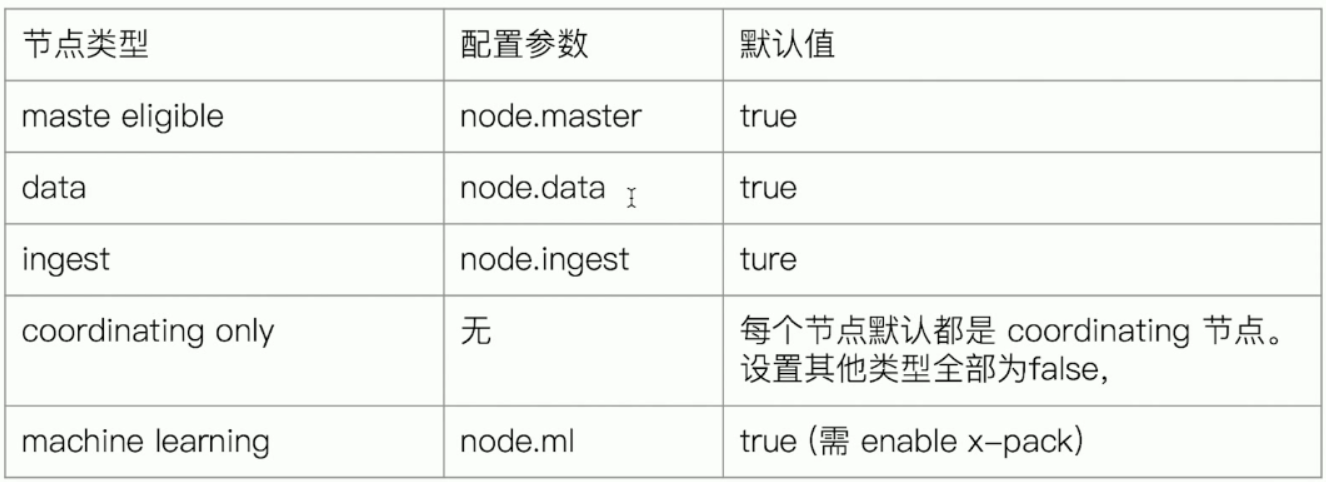
节点类型说明:
Coordinating Node :协同节点,这才是暴漏给客户端调用的
Master: 主节点,用来接收来自Coordinating Node的请求然后获取数据的
Master eligible nodes:声明可以参与选主的节点,为了高可用的
Data Node:数据节点,这个是最好理解的,就是用来存具体的文档数据的
其他节点就暂时不说了
注:节点可以有多个类型,默认有些是开启的,请看表格
分片与副本
在Elasticsearch中一个分片是一个Lucene实例,用于分开存储数据的,单节点也可以进行分片,但是没有太大意义,后面我们讲集群部署的时候会说到这个问题
副本说白了就是对分片的冗余备份,也就是每个分片可以分配一定的分片进行备份数据,如果实在不好理解,你就把分片理解为Mysql主节点,副本就是从节点
以下是集群的模式
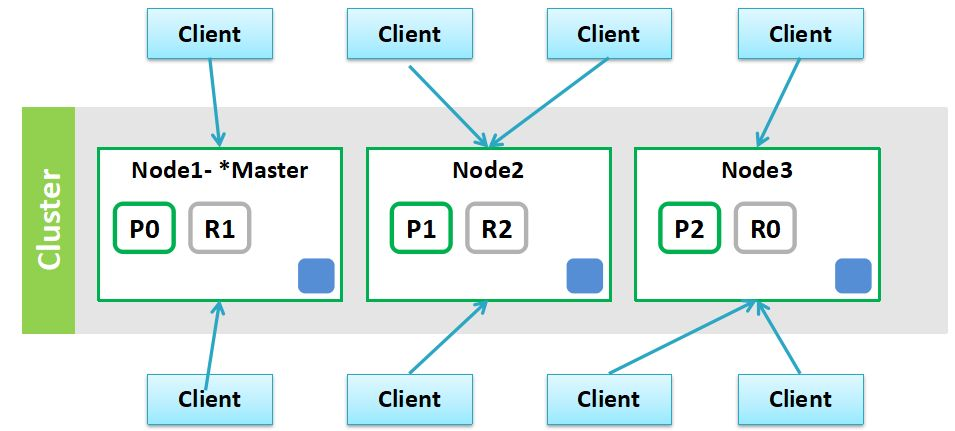
集群部署
我这里准备了三台机器进行部署,分别为:192.168.0.90、192.168.0.91、192.168.0.92
首先,为了方便,我配置了一些域名映射,如下
vim /etc/hosts
192.168.0.90 es-node1
192.168.0.91 es-node2
192.168.0.92 es-node3修改elasticsearch.yml
# 指定集群名称3个节点必须一致 cluster.name: es-cluster #指定节点名称,每个节点名字唯一 node.name: node-1 #是否有资格为master节点,默认为true node.master: true #是否为data节点,默认为true node.data: true # 绑定ip,开启远程访问,可以配置0.0.0.0,这里也可以配ip地址 network.host: 0.0.0.0 #指定web端口 #http.port: 9200 #指定tcp端口 #transport.tcp.port: 9300 #用于节点发现,如果你不配域名映射,直接用ip也是可以的 discovery.seed_hosts: ["es-node1", "es-node2", "es-node3"] #7.0新引入的配置项,初始仲裁,仅在整个集群首次启动时才需要初始仲裁。 #该选项配置为node.name的值,指定可以初始化集群节点的名称,每个节点的名称 cluster.initial_master_nodes: ["node-1","node-2","node-3"] #解决跨域问题 http.cors.enabled: true http.cors.allow-origin: "*"
主要关注的几个信息,如下:
cluster.name: es-cluster #集群名字,三个节点要保持一致
node.name: node-1 #集群下每个节点的名字,保持唯一即可
node.master: true #默认值,如果为true可以不配置
node.data: true #默认值,如果为true可以不配置
discovery.seed_hosts: ["es-node1", "es-node2", "es-node3"] # 发现的节点配置,也可以用ip
cluster.initial_master_nodes: ["node-1","node-2","node-3"] #初始化集群,每个节点的node.name值我三个节点配置信息如下
#192.168.0.90的配置
cluster.name: zxc-es-cluster
node.name: node-1
node.master: true
node.data: true
network.host: 0.0.0.0
path.data: /opt/elasticsearch-7.17.3/data
path.logs: /opt/elasticsearch-7.17.3/logs
discovery.seed_hosts: ["zxc1", "zxc2", "zxc3"]
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
http.cors.enabled: true
http.cors.allow-origin: "*"
#192.168.0.91的配置
cluster.name: zxc-es-cluster
node.name: node-2
node.master: true
node.data: true
network.host: 0.0.0.0
discovery.seed_hosts: ["zxc1", "zxc2", "zxc3"]
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
http.cors.enabled: true
http.cors.allow-origin: "*"
#192.168.0.92的配置
cluster.name: zxc-es-cluster
node.name: node-3
node.master: true
node.data: true
network.host: 0.0.0.0
discovery.seed_hosts: ["zxc1", "zxc2", "zxc3"]
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
http.cors.enabled: true
http.cors.allow-origin: "*"配置完以后,分别启动三台机器即可,然后访问 http://192.168.0.91:9200/_cat/nodes?pretty
随意一台机器即可,出现如下就说明访问成功了

部署失败问题
Cluster health status changed from [RED] to [YELLOW] (reason: [shards started [[.ds-.logs-deprecation.elasticsearch-default-2023.01.13-000001][0]]]).
百度说是要删除一些没用的索引:
curl -XPUT “ http://localhost:9200/_settings” -d’ { “number_of_replicas” : 0 } ’ #删除那些指定不明确的副本分片
但是我试了也不行
然后我想到zxc1的es之前做过单节点,有没有可能是因为数据不一致问题引起的,于是把zxc1的data目录数据全删了,然后重启,突然就可以,至于是不是这个问题,还得去排查,,,
第二个问题如下
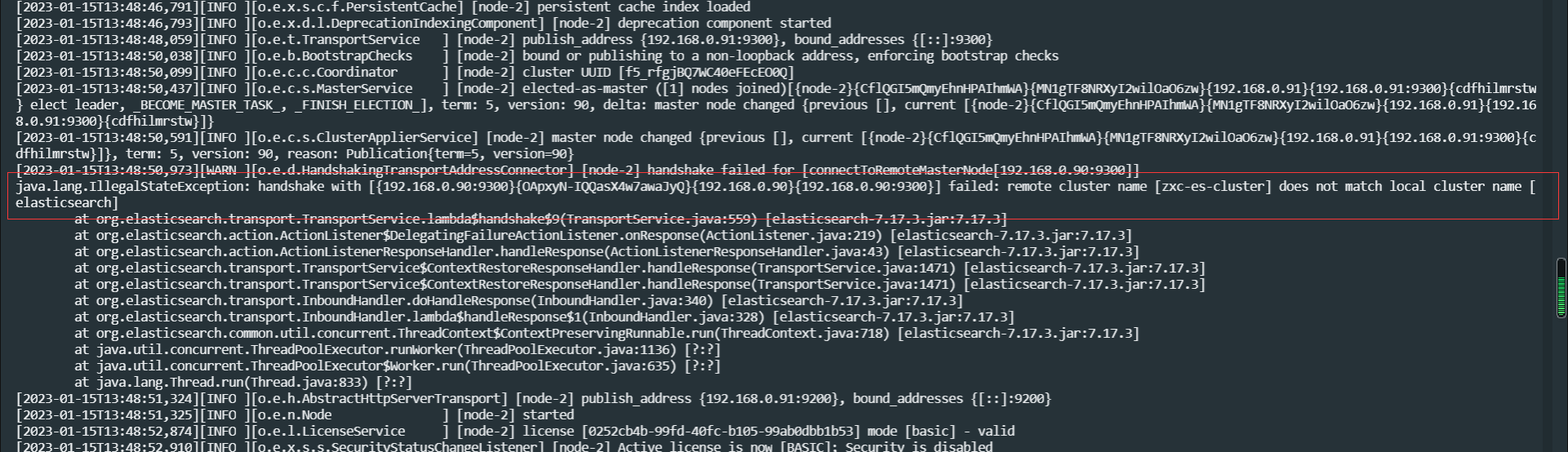
这个错误比较好解决,就是因为192.168.0.91这台机器我忘记配置cluster.name属性了,最终配置改完如下即可,加上这个配置即可
cluster.name: zxc-es-cluster
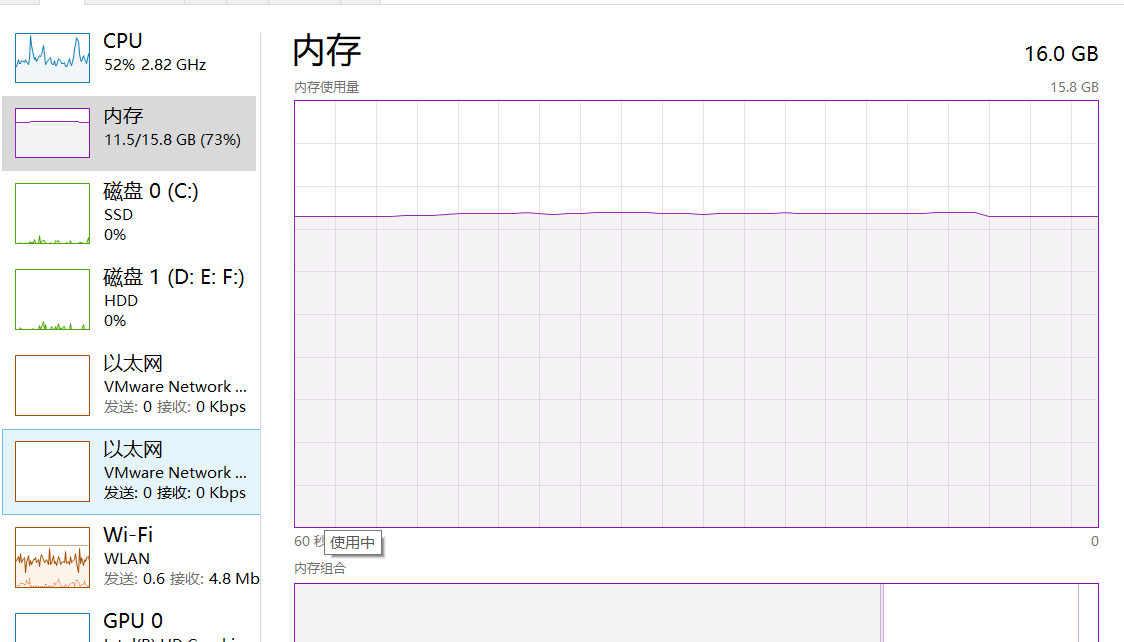
es还是非常占内存的,起了3台es。。内存基本被占完了
这里有一些查看集群信息的命令(随便指定一个节点就可以访问)
GET /_cat/nodes?v #查看节点信息
GET /_cat/health?v #查看集群当前状态:红、黄、绿
GET /_cat/shards?v #查看各shard的详细情况
GET /_cat/shards/{index}?v #查看指定分片的详细情况
GET /_cat/master?v #查看master节点信息
GET /_cat/indices?v #查看集群中所有index的详细信息
GET /_cat/indices/{index}?v #查看集群中指定index的详细信息 但是这样查看非常麻烦,所以这里介绍一个用于查看es集群的工具
Cerebro客户端
一个用于查看es集群的客户端,项目官网:https://github.com/lmenezes/cerebro
安装
下载地址:https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4.zip
运行cerebro
解压命令: unzip cerebro-0.9.4.zip
#启动
cerebro-0.9.4/bin/cerebro
#后台启动
nohup bin/cerebro > cerebro.log &注:这个只需要安装一台即可
如果出现以下的错,说明没有jdk,,,,
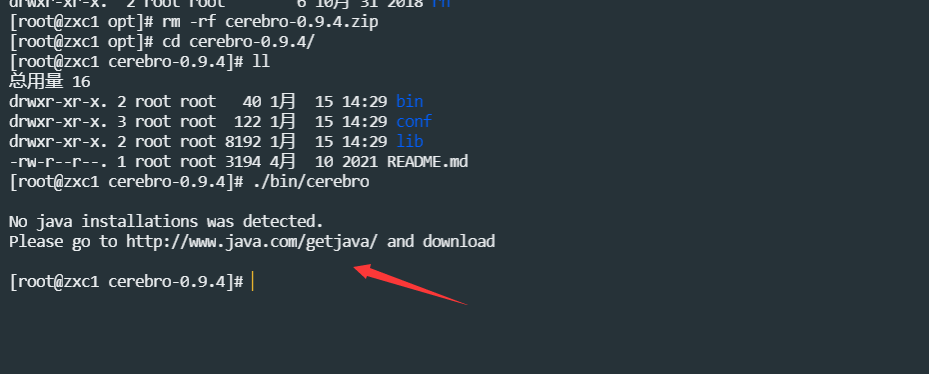
安装jdk,指定位置这里就不说了,,,请自行百度,安装完启动如下
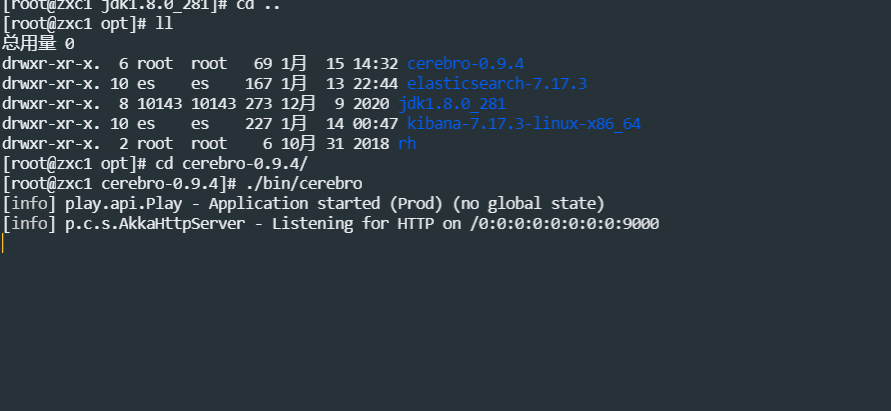
默认是在9000端口,我是装在第一台上,直接访问:http://192.168.0.90:9000/#!/connect
工具使用
随便输入其中集群中一台es节点即可,输入完连接,如下
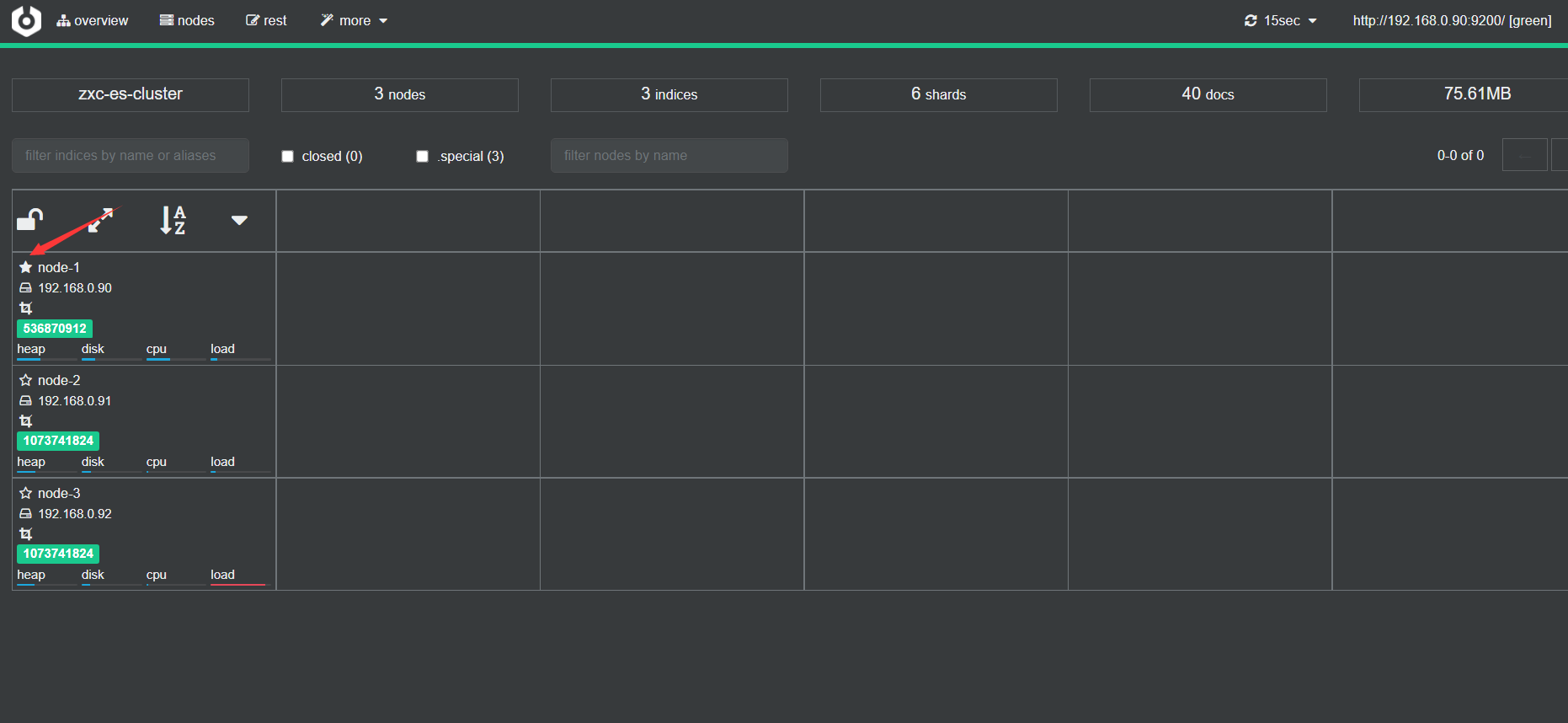
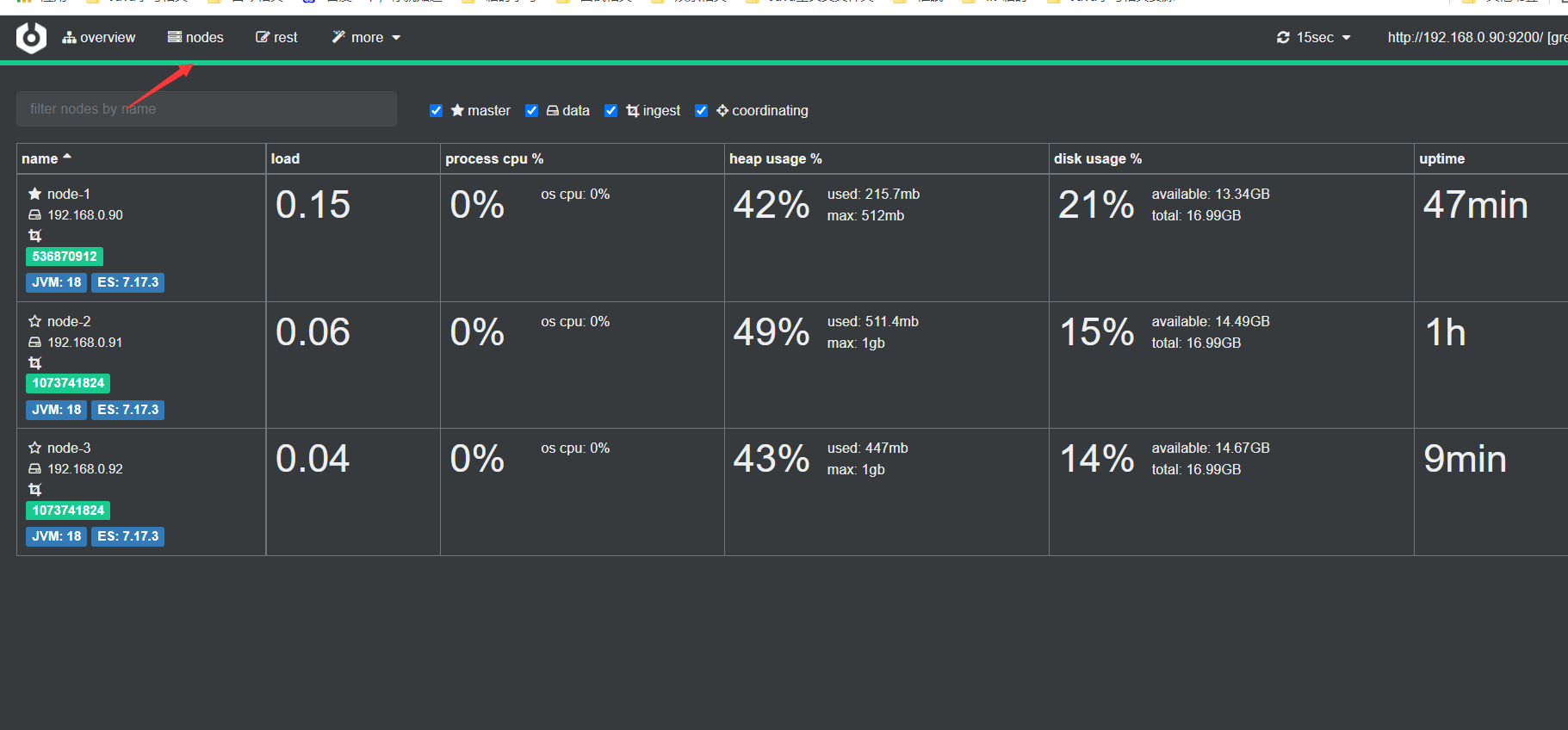
其中,node-1星号是实体的,表示主节点
还可以看节点使用情况
还可以创建索引之类的,如下
其他功能就不说了,有兴趣的可以自己研究
接下来我们用kibana来操作下,不过启动前要配置下kibana,很简单,就是配置如下
打开config/kibana.yml 文件,添加如下配置
elasticsearch.hosts: [" http://192.168.0.90:9200"," http://192.168.0.91:9200"," http://192.168.0.92:9200"]
其实就是把节点数据都配置进去即可,然后进行访问
集群验证
使用kibana创建一个索引,包含三个分片和1个副本,命令如下
PUT /zxc
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
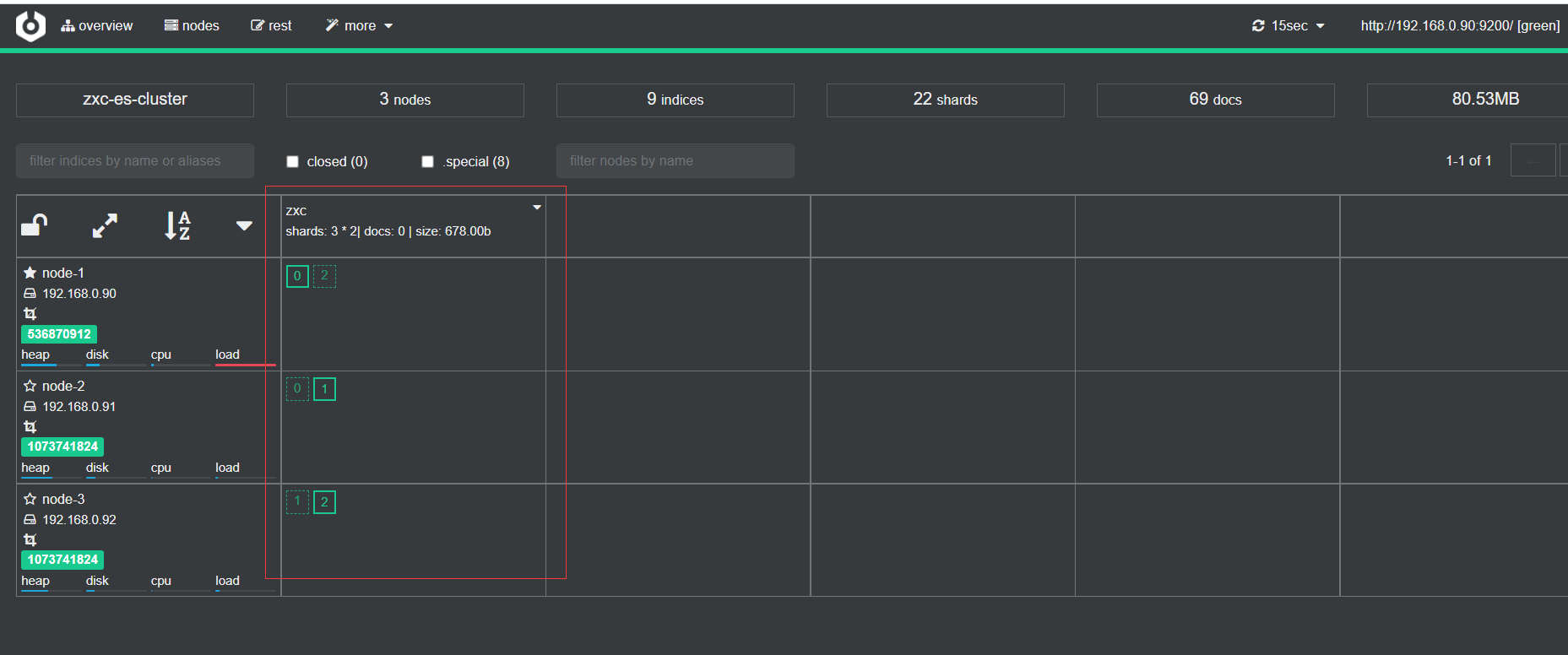
可以看到分片数为0,1,2,其中实线的为主副本,虚线表示副本,也就是说每个主分片都有一个副本,如果这个时候把nodes停掉es会自动分配,如下,我把node3杀掉,它会先展示如下
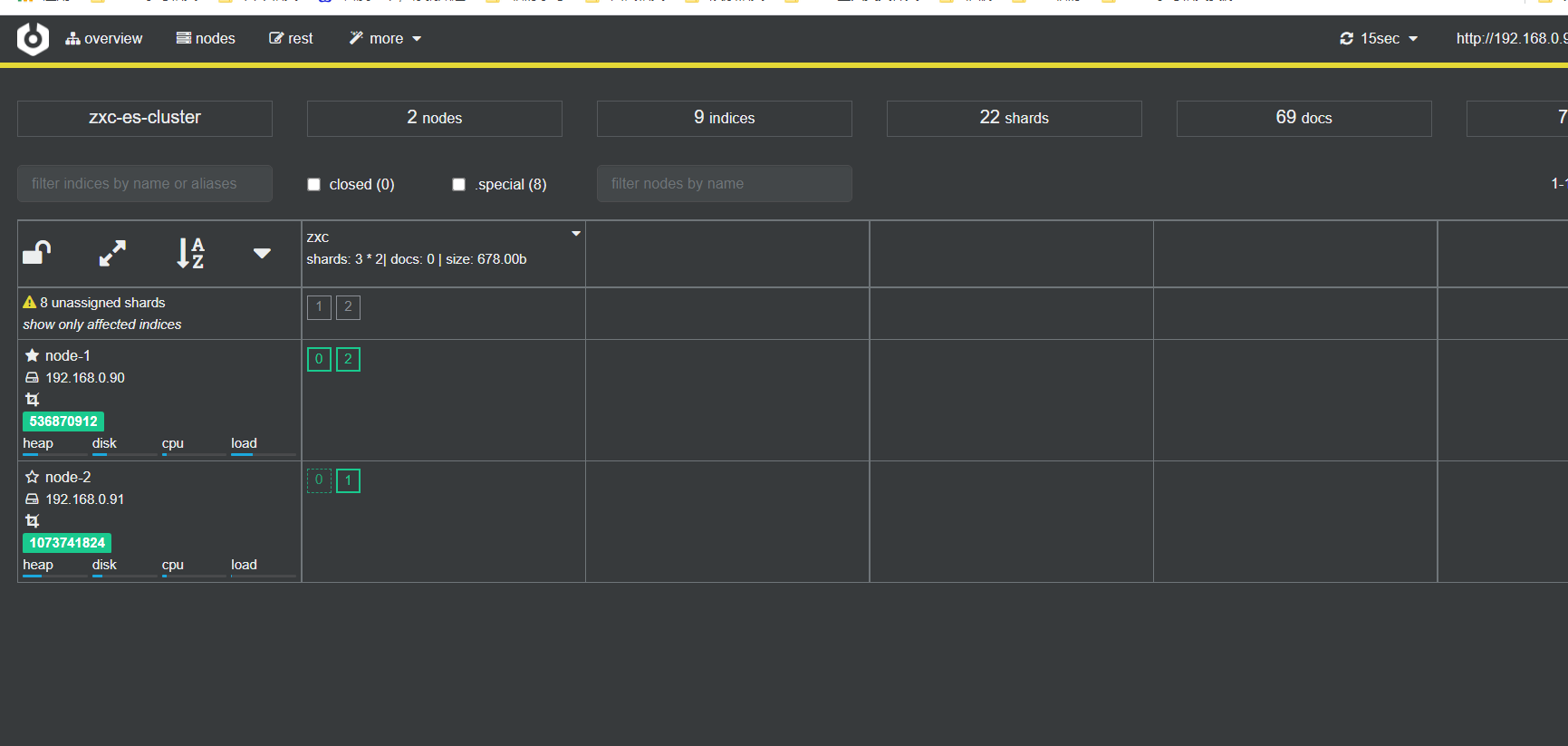
可以看到上面会有黄色的,然后过一段时间会变成如下:
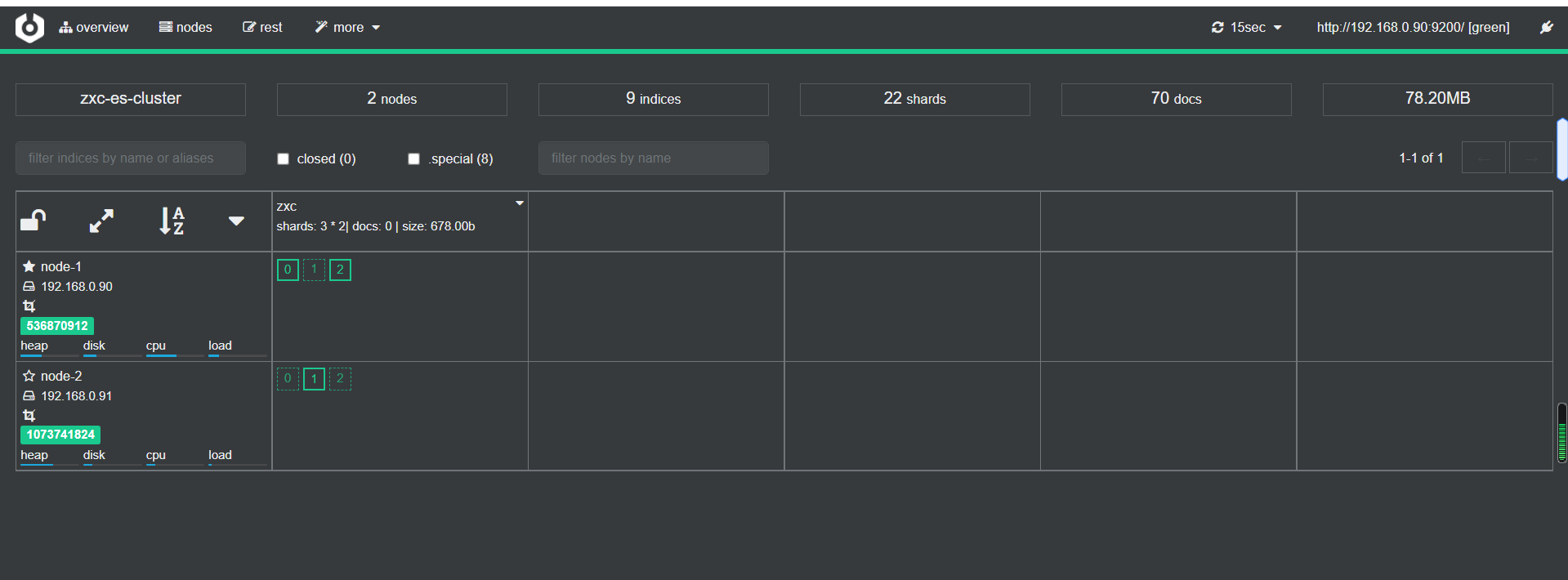
可以看到node-1有两个主分片,node-2有一个,这就是es的故障转移恢复的功能
如何选择分片数和副本数
一般来说,你有多少个服务器就取多少个主分片,因为es起一个分片就是一个lucene实例,我们尽可能跟服务器数量一样即可
那么副本数呢?我们一般只需要配置一个即可,最大不可以大于服务器个数-1,否则会出问题,因为es集群副本数是不能在主分片上的,下面我们来坐下实验
首先把node-3启动回来
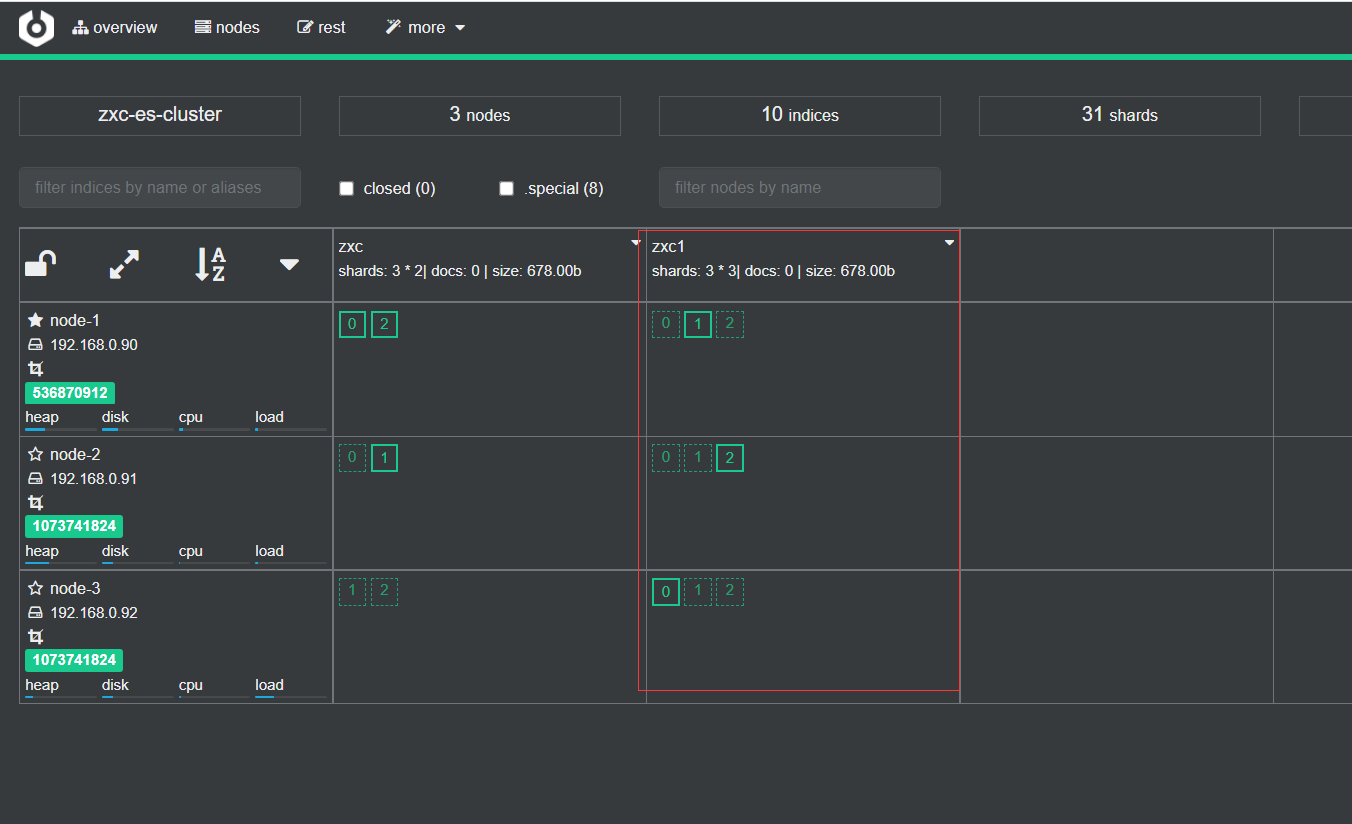
然后创建一个副本数为2的索引,2没有大于等于3,指令如下
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
效果如下,zxc1索引每个分片有2个副本
再让我们试一下创建三个副本,看下会有啥效果,指令
PUT /zxc2
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 3
}
}
效果如下
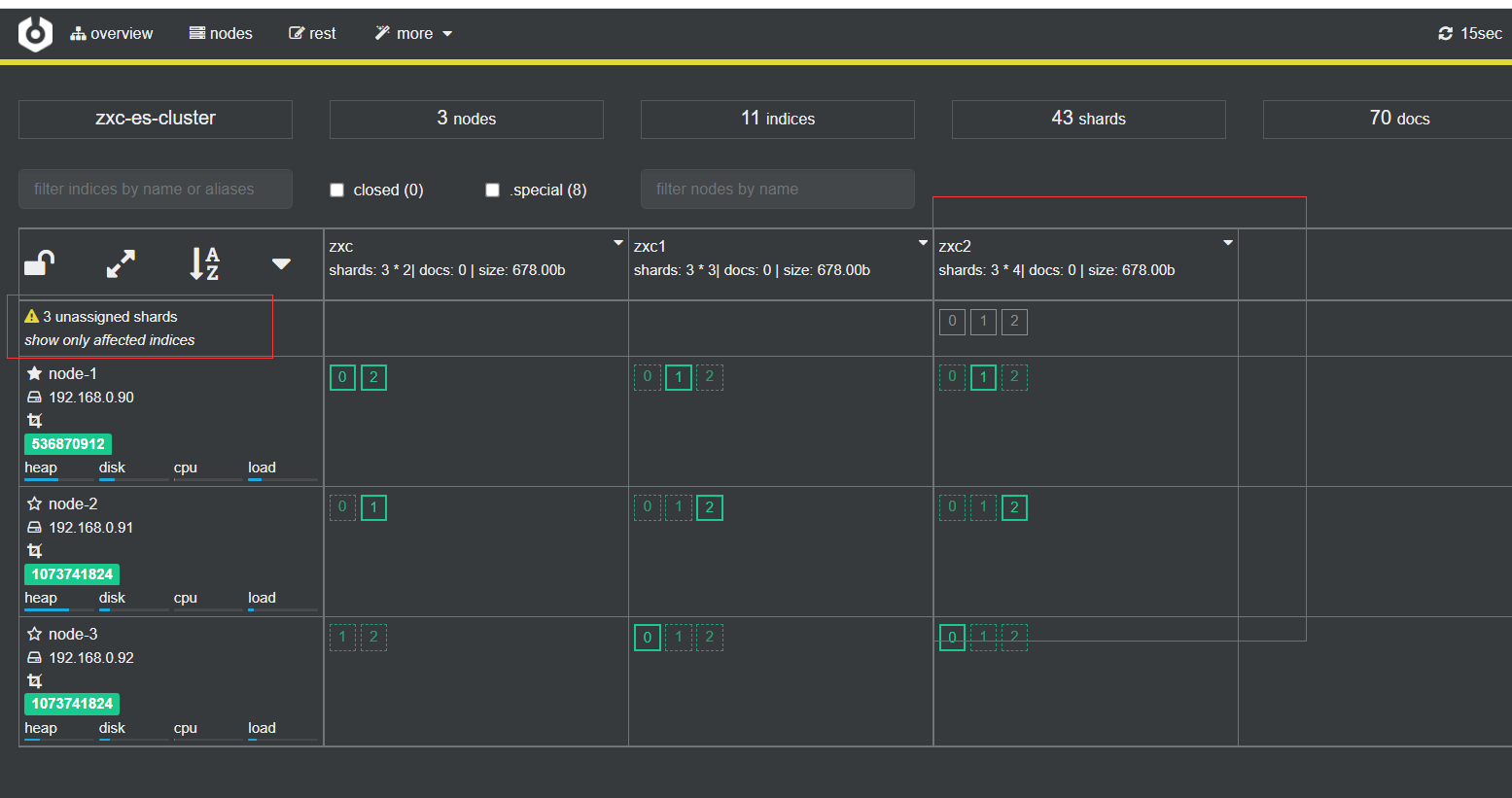
所以我们还是把zxc2删了,不要这么用,一般情况下副本数为1就行了
DELETE /zxc2
到此,简单的集群就配置完成了
总结
这个部署也不是很复杂,主要是理解节点,分片,副本等概念,部署其实是很简单的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









