






import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
from sklearn.linear_model import LinearRegression
import matplotlib
import seaborn as sns
import scipy.stats as sts
from scipy.optimize import leastsq
import numpy as np
#读取csv文件
df = pd.DataFrame(pd.read_csv('爱奇艺电影热播榜.csv'))
df
| Unnamed: 0 | 排名 | 电影名 | 实时热度 | 电影描述 | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 哥斯拉大战金刚2:帝国崛起 | 6534 | NaN |
| 1 | 1 | 2 | 扫黑·决不放弃 | 5803 | “扫黑风暴”继绿藤市之后席卷奎州,偏偏在督导组进驻的节骨眼儿上,李南北和俞青这对窝囊师徒竟意... |
| 2 | 2 | 3 | 末路狂花钱 | 4160 | 人到中年一事无成的贾有为,被诊断出脑部肿瘤,只剩十天寿命,于是他卖掉了传言要拆迁的老屋,找回... |
| 3 | 3 | 4 | 前途海量 | 4152 | 隧道坍塌,5个性格身份迥异的陌生人被困,唯有的食物是一车啤酒,想活命只能喝酒的逃生之旅,惊险... |
| 4 | 4 | 5 | 九龙城寨之围城 | 4078 | 本片根据余儿原著小说《九龙城寨》改编。上世纪八十年代,恶名昭著的“三不管”地带九龙城寨中黑帮... |
| 5 | 5 | 6 | 朝云暮雨 | 3685 | 影片改编自真实故事《穿婚纱的杀人少女》,刑满释放人员老秦服刑27年后出狱,只想娶妻生子,开启... |
| 6 | 6 | 7 | 功夫熊猫4 | 3670 | 神龙大侠阿宝再度归来,要被师父强行进阶修行。系列全新最强反派魅影妖后登场,神秘莫测的她可以幻... |
| 7 | 7 | 8 | 苗岭诡事 | 3611 | 民末年间的偏僻山区,几位村民深夜盗墓,被蛊夺命。陆文良和张持义都发现尸体诡异之处,两人结伴进... |
| 8 | 8 | 9 | 维和防暴队 | 3588 | 影片聚焦中国维和警察鲜为人知的生死时刻!应联合国请求、受国家派遣,余卫东、杨震、丁慧等维和警... |
| 9 | 9 | 10 | 三叉戟 | 3582 | 二十年前叱咤风云的三个警察“老炮”,被警界荣称为“三叉戟”,如今已到了快退休的年纪,却不料误... |
| 10 | 10 | 11 | 致命通话 | 3482 | 梦佳为躲避丈夫家暴,在新居里意外接通过去住户茹玫打来的电话。起初两人凭藉对时空来电的好奇,加... |
| 11 | 11 | 12 | 热辣滚烫 | 3415 | 大学毕业后仅仅工作短暂的一段时间,杜乐莹便退回家中,宅家长达十年之久。她无所事事,拒绝和外界... |
| 12 | 12 | 13 | 西装暴徒 | 3415 | 多年前,周克一袭西装独身硬闯黑帮窝点,救出兄长巴诺,最终却被捕入狱。一晃多年,出狱后的周克化... |
| 13 | 13 | 14 | 第二十条 | 3320 | 这一年的不容易谁能懂?自打挂职到市检察院,韩明的糟心事就接二连三。儿子韩雨辰打了校领导儿子并... |
| 14 | 14 | 15 | 周处除三害 | 3221 | 通缉犯陈桂林生命将尽,却发现自己在通缉榜上只排名第三,他决心查出前两名通缉犯的下落,并将他们... |
| 15 | 15 | 16 | 除暴安良 | 3206 | 刑警队长常勇在维护社会治安行动的过程中,发现一伙匪徒抢劫了大量现金并藏在了本市,随着对这起抢... |
| 16 | 16 | 17 | 飞驰人生2 | 3203 | 五年,三万六千遍,张驰的蓝牙已再次连上。那个不想输的张驰留下了“巴音布鲁克永远的王”的传说,... |
| 17 | 17 | 18 | 制暴 | 3068 | 【观影提示:十六岁以下观众禁止观看】某集团董事长成杰(包贝尔 饰)蓄意强暴其公司女员工韩梅并... |
| 18 | 18 | 19 | 浴血狙击 | 3059 | 1943年,日军对苏北、鲁中地区的抗日根据地展开扫荡,滨海军分区八路军为掐断日军补给线,决定... |
| 19 | 19 | 20 | 我们一起摇太阳 | 3015 | 韩延导演“生命三部曲”终章,部分取材于纪实报道文章《最功利的婚姻交易,最动情的永恒约定》。故... |
| 20 | 20 | 21 | 彷徨之刃 | 3004 | 本剧改编自东野圭吾同名小说,讲述了与女儿相依为命的父亲长峰重树,在女儿被残忍杀害后为复仇而成... |
| 21 | 21 | 22 | 龙石密码 | 2941 | 二十世纪80年代初,西北山脉边界,有一个名叫小丰村的偏僻村落。陈永在齐依然家药材铺做伙计,闲... |
| 22 | 22 | 23 | 黑社会 | 2826 | 香港最大黑社会帮会“和联胜”举行两年一度的办事人选举,阿乐与大D作为两大地区领导,暗地里展开... |
| 23 | 23 | 24 | 黑暗森林 | 2755 | 联合国禁毒组织与中缅警方联合打击,以萨卡集团为首的贩毒组织,企图通过中国把毒品贩卖到全世界的... |
| 24 | 24 | 25 | 硬汉狙击 | 2747 | 影片中张小龙和王泰等人,曾是共过患难的队友,情同手足。后来张小龙与王泰产生分歧,王泰心中生恨... |
df.drop('电影名', axis=1, inplace = True)
df.drop('电影描述', axis=1, inplace = True)
df.head()
| Unnamed: 0 | 排名 | 实时热度 | |
|---|---|---|---|
| 0 | 0 | 1 | 6534 |
| 1 | 1 | 2 | 5803 |
| 2 | 2 | 3 | 4160 |
| 3 | 3 | 4 | 4152 |
| 4 | 4 | 5 | 4078 |
#检查是否有重复值
df.duplicated()
0 False
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 False
10 False
11 False
12 False
13 False
14 False
15 False
16 False
17 False
18 False
19 False
20 False
21 False
22 False
23 False
24 False
dtype: bool
#缺失值处理
df[df.isnull().values==True]#返回无缺失值
| Unnamed: 0 | 排名 | 实时热度 |
|---|
#用describe()命令显示描述性统计指标
df.describe()
| Unnamed: 0 | 排名 | 实时热度 | |
|---|---|---|---|
| count | 25.000000 | 25.000000 | 25.000000 |
| mean | 12.000000 | 13.000000 | 3581.600000 |
| std | 7.359801 | 7.359801 | 882.184788 |
| min | 0.000000 | 1.000000 | 2747.000000 |
| 25% | 6.000000 | 7.000000 | 3059.000000 |
| 50% | 12.000000 | 13.000000 | 3415.000000 |
| 75% | 18.000000 | 19.000000 | 3670.000000 |
| max | 24.000000 | 25.000000 | 6534.000000 |
#数据分析与可视化
X = df[['排名']]
predict_model = LinearRegression()
predict_model.fit(X,df['实时热度'])
print("回归系数为:",predict_model.coef_)
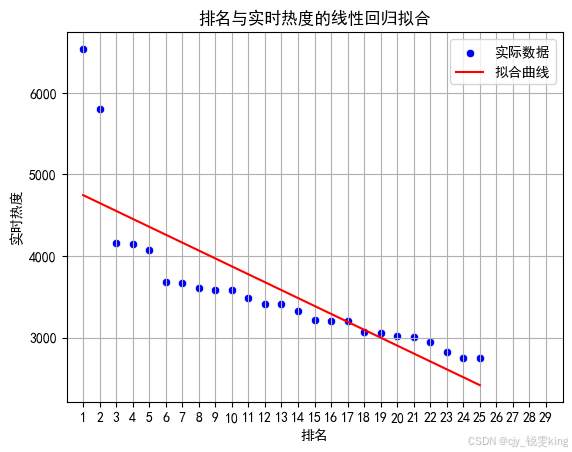
#绘制排名与评分的回归图
sns.scatterplot(x='排名', y='实时热度', data=df, color='b', label='实际数据') # 实际数据的散点图
plt.plot(X, predict_model.predict(X), color='r', label='拟合曲线') # 拟合的曲线
plt.title('排名与实时热度的线性回归拟合')
plt.xlabel('排名')
plt.ylabel('实时热度')
plt.legend()
plt.grid(True)
plt.xlim(0, 30) # 设置横坐标范围从 0 到 30
plt.xticks(range(1, 30)) # 设置刻度为整数 1 到 30
plt.show()
回归系数为: [-97.04538462]
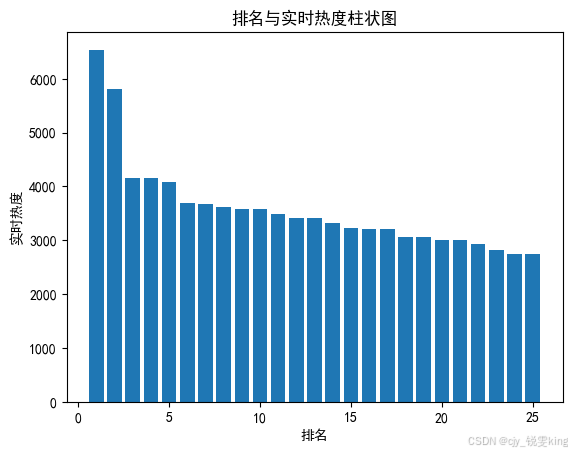
# 绘制柱状图
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.bar(df.排名, df.实时热度, label="排名与实时热度柱状图")
plt.xlabel("排名")
plt.ylabel("实时热度")
plt.title('排名与实时热度柱状图')
plt.show()
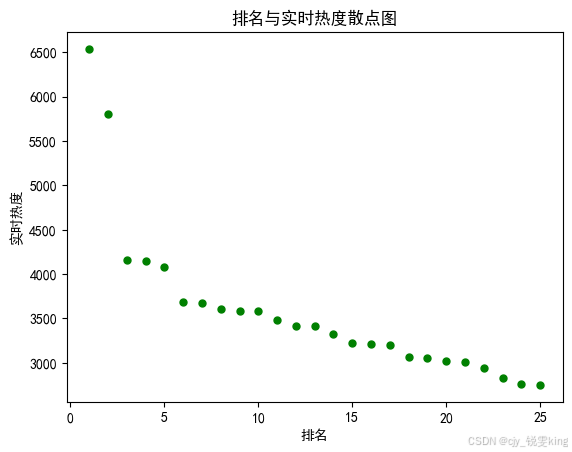
def scatter():
plt.scatter(df.排名, df.实时热度, color='green', s=25, marker="o")
plt.xlabel("排名")
plt.ylabel("实时热度")
plt.title("排名与实时热度散点图")
plt.show()
scatter()
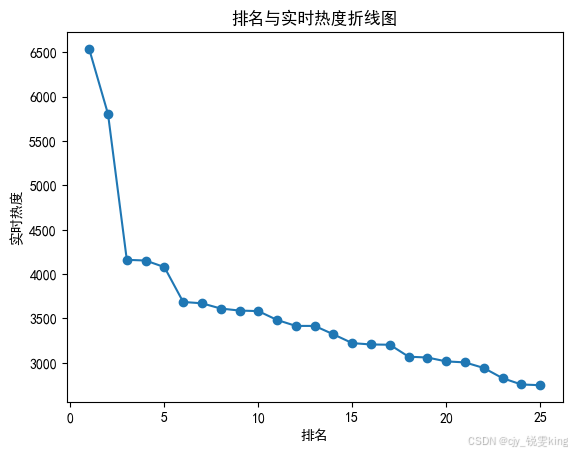
def line_diagram():
x = df['排名']
y = df['实时热度']
plt.xlabel('排名')
plt.ylabel('实时热度')
plt.plot(x,y)
plt.scatter(x,y)
plt.title("排名与实时热度折线图")
plt.show()
line_diagram()
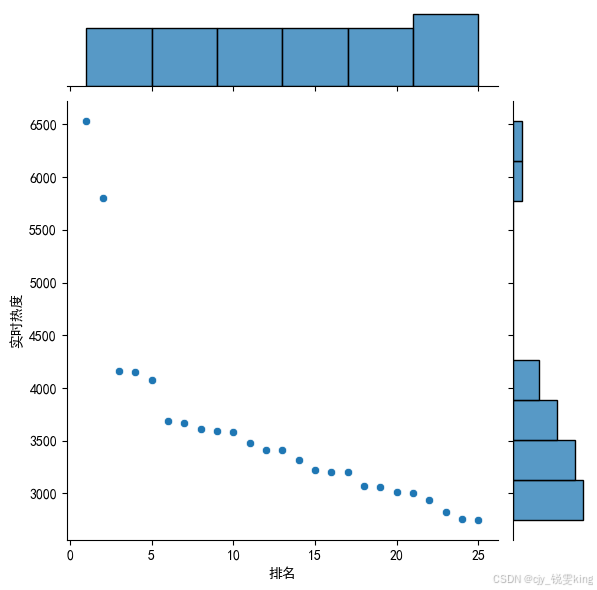
sns.jointplot(x="排名",y='实时热度',data = df)
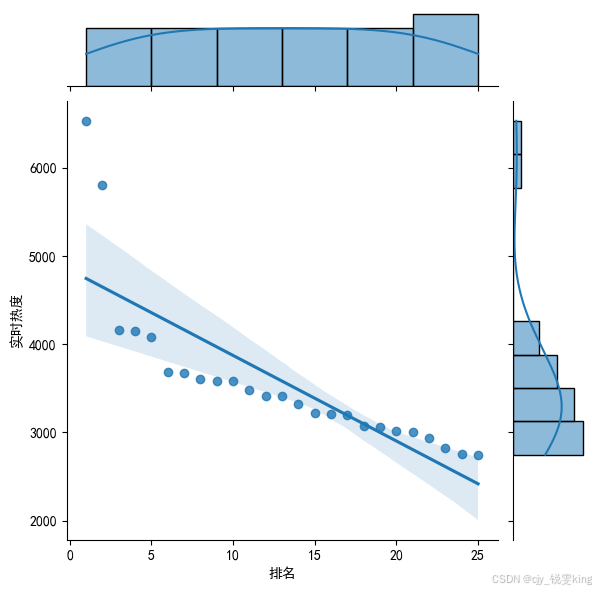
sns.jointplot(x="排名",y='实时热度',data = df, kind='reg')
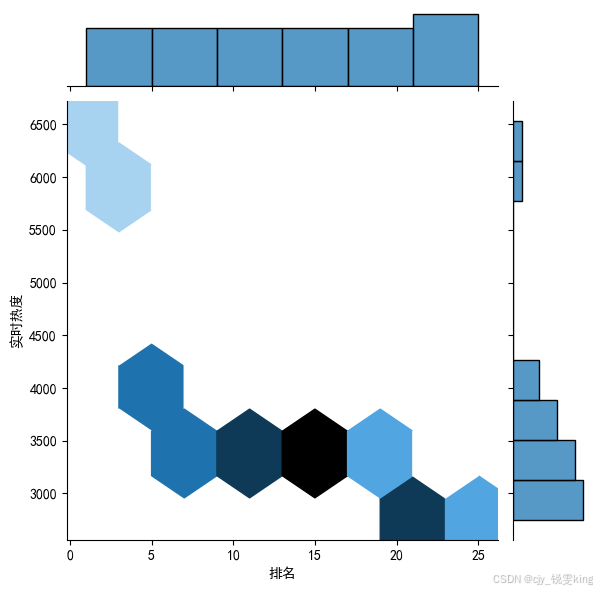
sns.jointplot(x="排名",y='实时热度',data = df, kind='hex')
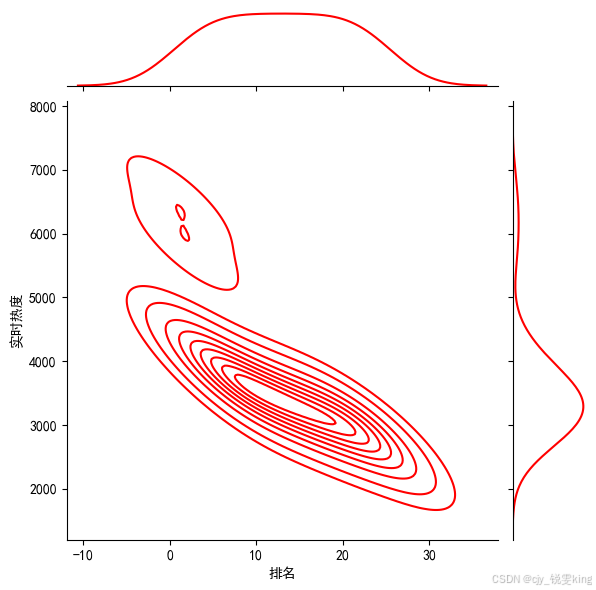
sns.jointplot(x="排名",y='实时热度',data = df, kind='kde', color='r')
plt.show()
def main():
colnames = ["排名", "电影名", "实时热度", "电影描述"]
df = pd.read_csv('爱奇艺电影热播榜.csv',skiprows=1,names=colnames)
X = df.排名
Y = df.实时热度
r=sts.pearsonr(X,Y) #相关性r
print('相关性r',r)
def func(p, x):
k, b = p
return k * x + b
def error_func(p, x, y):
return func(p,x)-y
p0 = [0,0]
#使用leastsq()函数对数据进行拟合
Para = leastsq(error_func, p0, args = (X, Y))
k, b = Para[0]
print("k=",k,"b=",b)
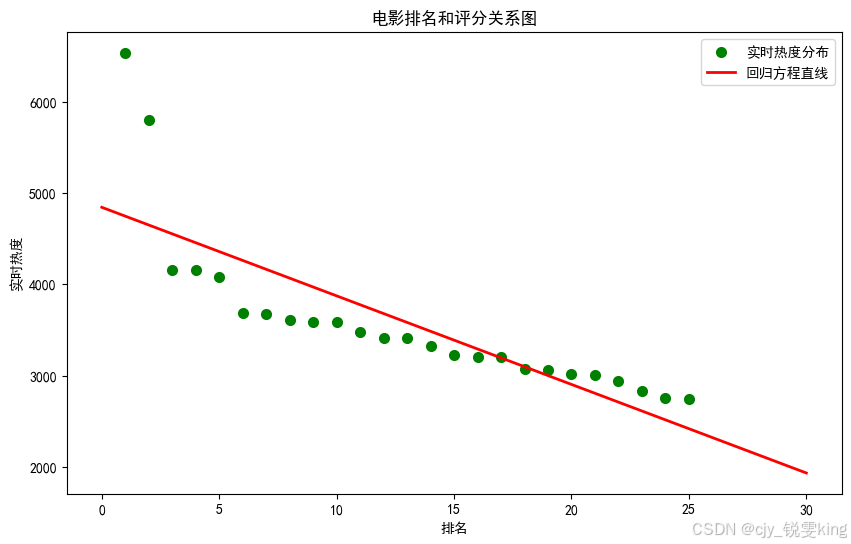
plt.figure(figsize=(10,6))
plt.scatter(X,Y,color="green",label=u"实时热度分布",linewidth=2)
x=np.linspace(0,30,30)
y=k*x+b
plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2)
plt.title("电影排名和评分关系图")
plt.xlabel('排名')
plt.ylabel('实时热度')
plt.legend()
plt.show()
main()
相关性r PearsonRResult(statistic=-0.8096202763305835, pvalue=9.489465268929371e-07)
k= -97.0453842677809 b= 4843.189995481152
#绘制一元二次回归方程
def main2():
colnames = ["排名", "电影名", "实时热度", "电影描述"]
df = pd.read_csv('爱奇艺电影热播榜.csv',skiprows=1,names=colnames)
X = df.排名
Y = df.实时热度
r=sts.pearsonr(X,Y) #相关性r
print('相关性r',r)
def func(p, x):
a, b, c = p
return a * x * x + b * x + c
def error_func(p, x, y):
return func(p,x)-y
p0 = [0,0,0]
#使用leastsq()函数对数据进行拟合
Para = leastsq(error_func, p0, args = (X, Y))
a, b, c = Para[0]
print("a=", a,"b=", b,"c=", c)
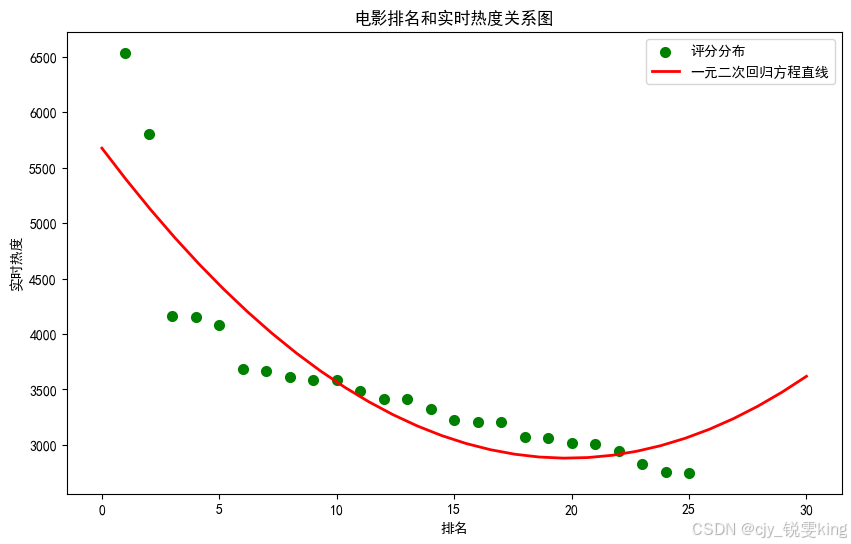
plt.figure(figsize=(10,6))
plt.scatter(X,Y,color="green",label=u"评分分布",linewidth=2)
x = np.linspace(0,30,30)
y = a * x * x + b * x + c
plt.plot(x,y,color="red",label=u"一元二次回归方程直线",linewidth=2)
plt.title("电影排名和实时热度关系图")
plt.xlabel('排名')
plt.ylabel('实时热度')
plt.legend()
plt.show()
main2()
相关性r PearsonRResult(statistic=-0.8096202763305835, pvalue=9.489465268929371e-07)
a= 7.118115681064069 b= -282.11639227668485 c= 5676.009534081745


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









