








马尔科夫链
马尔科夫链,因安德烈.马尔科夫(A.A.Markov,1856-1922)得名,是指数学中具有马尔科夫性质的离散事件随机过程。
每个状态的转移只依赖于之前的n个状态,这个过程被称为1个n阶的模型,其中n是影响转移状态的数目。
最简单的马尔科夫过程就是一阶过程,每一个状态的转移只依赖于其之前的那一个状态。用数学表达式表示就是:
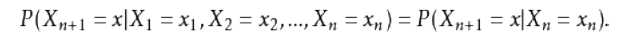
假设天气服从马尔科夫链
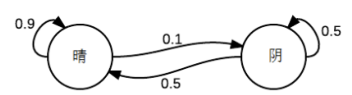
转移矩阵
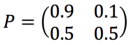
如果已知今天是晴天,那么明天天气的概率是:
(10)∗[0.90.50.10.5]=(0.90.1)
即明天是晴天的概率是0.9,阴天的概率是0.1
从今天(晴或阴)开始,在遥远未来的某天,晴阴的概率分布是什么?
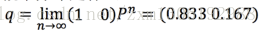
如果n无穷大,由于
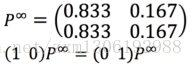
可知,不管今天晴阴,很多天之后的晴阴分布收敛到一个固定分布,这个固定分布叫 稳态分布
在转移状态不变,很久的未来,每一天天气都是q=(0.833 0.167)的一个样本点
至此,我们就为上面的一阶马尔科夫过程定义以下三部分:
- 状态:晴天、阴天
- 初始向量:定义系统在时间为0的时候的状态的概率
- 状态转移矩阵:每种天气转换的概率。
所有的能被这样描述的系统都是一个马尔可夫过程
马尔科夫链的缺陷
很明显,前后关系的缺失,带来了信息的缺失:
比如我们的股市,如果只是观测市场,我们只能知道当天的价格、成交量等信息,但是并不知道当前股市处于什么样的状态(牛市、熊市、震荡、反弹等),在这种情况下我们有两个状态集合,一个可以观察到的状态集合(股市价格成交量状态等)和一个隐藏的状态集合(股市状态)。
希望根据股市价格成交量状况和马尔科夫假设来预测股市的状况。
可以观察到的状态序列和隐藏的状态序列是概率相关的。
我们可以将这种类型的过程建模为有一个隐藏的马尔科夫过程和一个与这个隐藏马尔科夫过程概率相关的并且可以观察到的状态集合,就是隐马尔科夫模型。
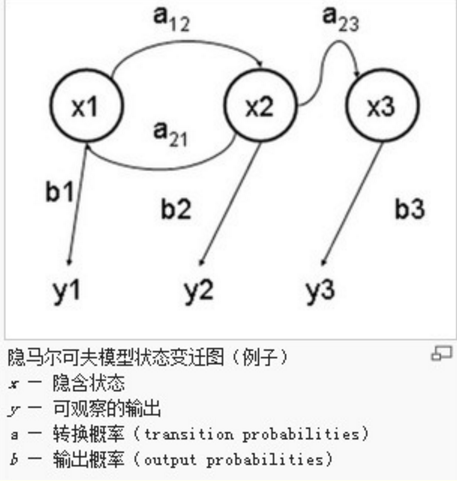
隐马尔可夫链
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。
下面用一个简单的例子来阐述:
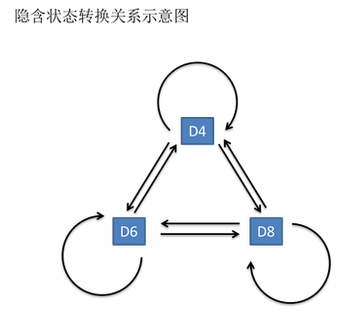
假设我手里有三个不同的骰子。
第一个骰子6个面(称这个骰子为D6),每个面(1,2,3,4,5,6)出现的概率是1/6。
第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。
第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
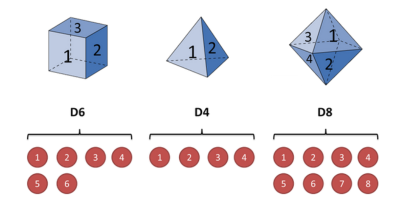
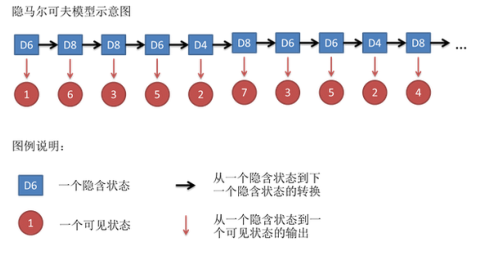
假设我们开始掷骰子,我们先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。然后我们掷骰子,得到一个数字,1,2,3,4,5,6,7,8中的一个。不停的重复上述过程,我们会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。例如我们可能得到这么一串数字(掷骰子10次):1 6 3 5 2 7 3 5 2 4
这串数字叫做可见状态链。但是在隐马尔可夫模型中,我们不仅仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列。比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率(transition probability)。转换概率可能不同。
可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率(emission probability)。就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。
和HMM模型相关的算法主要分为三类,分别解决三种问题:
- 知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道每次掷出来的都是哪种骰子(隐含状态链)。 在语音识别领域呢,叫做解码问题。
- 还是知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道掷出这个结果的概率。 -反欺诈。
- 知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),我想反推出每种骰子是什么(转换概率)。
对应
- Recognition:Given the observation sequence O=O1O2...OT and a model λ=(A,B,π) ,how do we choose a corresponding state sequence Q=q1q2...qT which is optimal in some sense, i.e.,best explains the observations
- Evaluation:Given the observation sequence O=O1O2...OT and a mode λ=(A,B,π) , how do we efficiently compute P(O|λ) , i.e.,the probability of the observation sequence given the model
- Training:Given the observation sequence O=O1O2...OT , how do we adjust the model parameters λ=(A,B,π) to maximize P(O|λ)
隐马尔科夫例子:
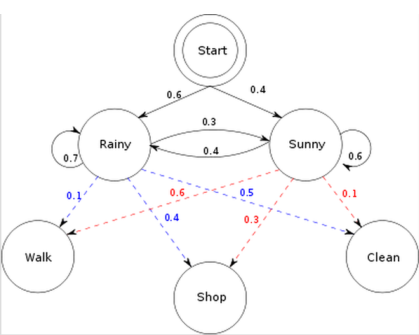
一个东京的朋友每天根据天气{下雨,天晴}决定当天的活动{公园散步,购物,清理房间}中的一种,我每天只能在twitter上看到她发的推“啊,我前天公园散步、昨天购物、今天清理房间了!”,那么我可以根据她发的推特推断东京这三天的天气。在这个例子里,显状态是活动,隐状态是天气。
对应上面的三个问题:
- 已知整个模型,我观测到连续三天做的事情是:散步,购物,收拾,我想猜,这三天的天气是怎么样的。
- 已知整个模型,我观测到连续三天做的事情是:散步,购物,收拾。那么根据模型,计算产生这些行为的概率是多少。
- 最复杂的,我只知道这三天做了这三件事儿,而其他什么信息都没有。我得建立一个模型,晴雨转换概率,第一天天气情况的概率分布,根据天气情况选择做某事的概率分布。
隐马尔科夫链的解法:
- 问题一:Viterbi Algo,维特比算法。
- 问题二:Forword Algorithm,向前算法,或者 Backward Algorithm,向后算法。
- 问题三:Baum-Welch Algo,鲍姆-韦尔奇算法
问题1 的解法:维特比算法
- 找到概率最大的隐含序列,意味着计算 argmaxQP(Q|O,λ) ,相当于计算 argmaxQP(Q,O|λ)
- Viterbi 算法(动态规划)定义 δj(t) ,保存在时间t时,观测值和状态 Sj 的最大可能性
- 归纳:
- 使用回溯(backtracking)(保持最大参数对于每个t和j)来发现最优解
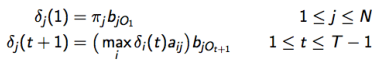
问题2 的解法1:遍历算法
三天的天气共有6种可能,遍历所有的可能,计算产生此种观测值的概率。
具体步骤:
- 需要计算 P(O|λ) ,给出模型 λ 的条件下,可见序列为 O=O1O2...OT 的可能性。
- 我们能够枚举所有可能的隐含状态序列 Q=q1q2...qT
- 对于其中一个隐含状态序列
Q
- 对于这个隐含状态序列
Q 的可能性是: - 因此联合可能性为:
- 考虑所有可能隐含状态序列
- 存在问题:需要 2TNT 的计算量
- NT 的可能的隐含状态序列
- 每个序列需约 2T的计算量
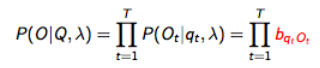
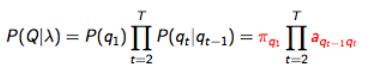
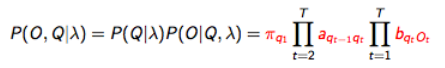
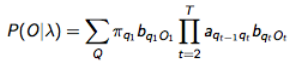
问题2 的解法2:向前算法
- 定义前向变量
αj(t)
作为 直到时间t ,和隐藏状态
Sj
下,部分可见序列的可能性:
- 可用归纳计算:
- 通过
N2T
复杂度的计算:
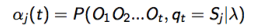
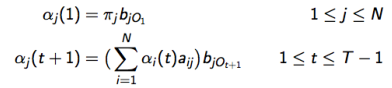
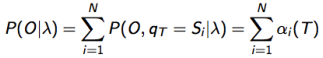
问题2 的解法3:后向算法
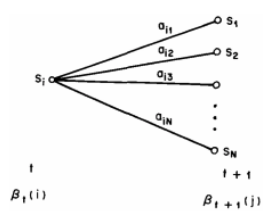
- 定义后向变量
βi(t)
作为时间t 之后,给定 t 时刻的隐藏状态
Si
下,部分观测序列的可能性:
- 归纳计算:
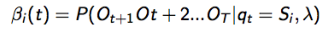
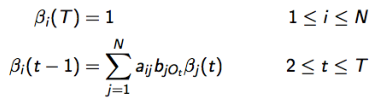
问题3 的解法:Baum-Welch 算法



隐马尔可夫链应用:词性标注
马尔科夫模型本质上是一个有转换概率的有限状态机
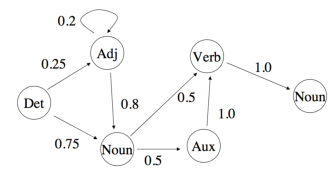
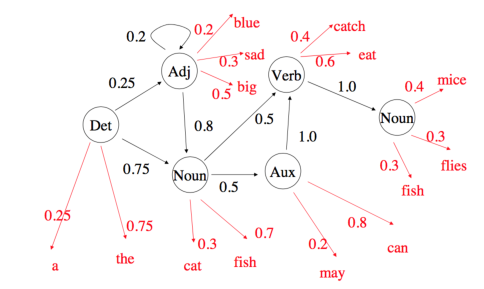
一个隐马尔可夫模型,在一个特定状态下会以一定概率发射出标记。
我们想要计算
P(t1,...,tn|w1,...,wn)
,根据贝叶斯理论:
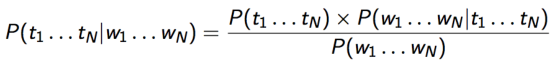
我们要计算使上述概率最大的 序列 t . 分母都一样主要看分子。
链式法则;
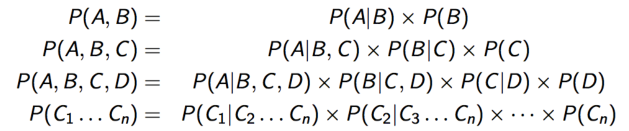
标注转移分布:
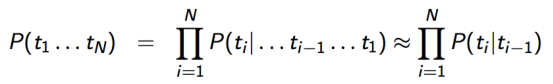
词发射分布:
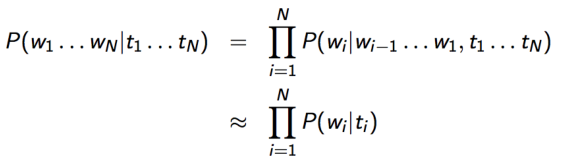
例子:词性标注
- t1...tN 标签对应隐含状态 (zn)
- w1...wN 词对应观察值 (xn)
- 通过数 单词 和标签 我们能计算模型的参数
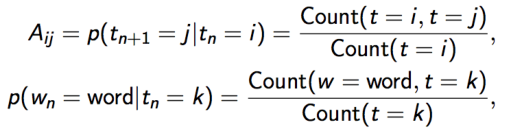
可以用合适的语料库来计算,如 Penn Treebank(UPenn) 和 British National Corpus(Oxford Text Archive)
得到如下表:
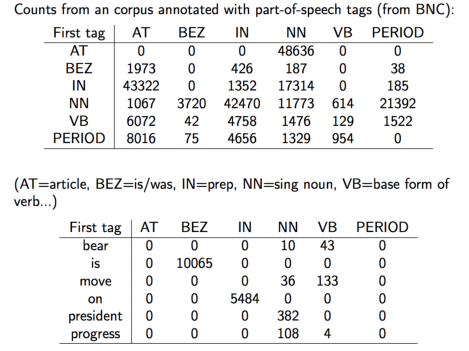
上述能解决问题2
如果给你一句话,求合适的tags ,即为问题1:
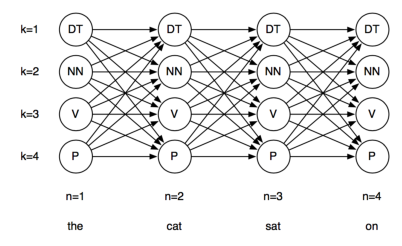
如何计算最可能的有效隐藏状态序列呢?
对于一个N个单词的句子,平均每个单词有M个词性,就有
MN
可能的序列。维特比算法是一种动态规划算法,能够计算最佳序列(路径)。
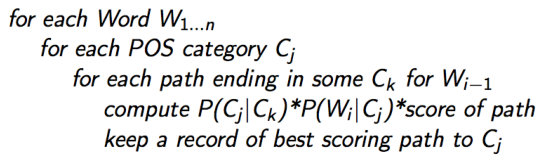
更复杂一点的伪代码:
对于一个句子:
w1...wN
有N个单词,假设词性集合
t1...tK
有K个直接的词性标签,创建一个 K*N 维的分数矩阵,和一个 K*N 维的反向指针矩阵:

使用HMM进行词性标注
假设我们的单词集: words = w1 … wN
Tag集: tags =
t1...tN
并且上课我们讲了,
P(tags | words) 正比于
P(ti|ti−1)∗P(wi|ti)
为了找一个句子的tag,
我们其实就是找的最好的一套tags,让他最能够符合给定的单词(words)。
首先,
导入库
import nltk
import sys
from nltk.corpus import brown预处理词库
给词们加上开始和结束符号。
Brown 里面的句子都是自己标注好了的,长这个样子:(I,NOUN),(LOVE,VERB),(YOU,NOUN)
那么,我们的开始符号也得跟他的格式符合,我们用 (START,START)(END,END) 来代表
brown_tags_words = [ ]
for sent in brown.tagged_sents():
# 先加开头
brown_tags_words.append( ("START", "START") )
# 为了省事儿,我们把tag都省略成前两个字母
brown_tags_words.extend([ (tag[:2], word) for (word, tag) in sent ])
# 加个结尾
brown_tags_words.append( ("END", "END") )词统计
将我们所有的词库中拥有的单词与tag之间的关系,做一个简单粗暴的统计。
P(wi|ti)=count(wi,ti)count(ti)
可以循环所有的corpus进行统计,也可以用NLTK做统计。
# conditional frequency distribution
cfd_tagwords = nltk.ConditionalFreqDist(brown_tags_words)
# conditional probability distribution
cpd_tagwords = nltk.ConditionalProbDist(cfd_tagwords, nltk.MLEProbDist)看看平面统计下来的结果:
print("The probability of an adjective (JJ) being 'new' is", cpd_tagwords["JJ"].prob("new"))
print("The probability of a verb (VB) being 'duck' is", cpd_tagwords["VB"].prob("duck"))The probability of an adjective (JJ) being ‘new’ is 0.01472344917632025
The probability of a verb (VB) being ‘duck’ is 6.042713350943527e-05
还有第二个公式需要计算:
P(ti|ti−1)=count(ti−1,ti)count(ti−1)
他跟words没有关系,它属于隐层的马科夫链。
我们先取出所有的tag来。
brown_tags = [tag for (tag, word) in brown_tags_words ]# count(t{i-1} ti)
# bigram的意思是 前后两个一组,联在一起
cfd_tags= nltk.ConditionalFreqDist(nltk.bigrams(brown_tags))
# P(ti | t{i-1})
cpd_tags = nltk.ConditionalProbDist(cfd_tags, nltk.MLEProbDist)好的,可以看看效果了:
print("If we have just seen 'DT', the probability of 'NN' is", cpd_tags["DT"].prob("NN"))
print( "If we have just seen 'VB', the probability of 'JJ' is", cpd_tags["VB"].prob("DT"))
print( "If we have just seen 'VB', the probability of 'NN' is", cpd_tags["VB"].prob("NN"))If we have just seen ‘DT’, the probability of ‘NN’ is 0.5057722522030194
If we have just seen ‘VB’, the probability of ‘JJ’ is 0.016885067592065053
If we have just seen ‘VB’, the probability of ‘NN’ is 0.10970977711020183
一些有趣的结果:
比如, 一句话,”I want to race”, 一套tag,”PP VB TO VB”
他们之间的匹配度有多高呢?
其实就是:
P(START) * P(PP|START) * P(I | PP) * P(VB | PP) * P(want | VB) * P(TO | VB) * P(to | TO) * P(VB | TO) * P(race | VB) * P(END | VB)
prob_tagsequence = cpd_tags["START"].prob("PP") * cpd_tagwords["PP"].prob("I") * \
cpd_tags["PP"].prob("VB") * cpd_tagwords["VB"].prob("want") * \
cpd_tags["VB"].prob("TO") * cpd_tagwords["TO"].prob("to") * \
cpd_tags["TO"].prob("VB") * cpd_tagwords["VB"].prob("race") * \
cpd_tags["VB"].prob("END")
print( "The probability of the tag sequence 'START PP VB TO VB END' for 'I want to race' is:", prob_tagsequence)The probability of the tag sequence ‘START PP VB TO VB END’ for ‘I want to race’ is: 1.0817766461150474e-14
Viterbi 的实现
如果我们手上有一句话,怎么知道最符合的tag是哪组呢?
首先,我们拿出所有独特的tags(也就是tags的全集)
distinct_tags = set(brown_tags)然后 随手找句话
sentence = ["I", "want", "to", "race" ]
sentlen = len(sentence)下来,开始维特比:
从1循环到句子的总长N,记为i
每次都找出以tag X为最终节点,长度为i的tag链
viterbi = [ ]同时,还需要一个回溯器:
从1循环到句子的总长N,记为i
把所有tag X 前一个Tag记下来。
backpointer = [ ]first_viterbi = { }
first_backpointer = { }
for tag in distinct_tags:
# don't record anything for the START tag
if tag == "START": continue
first_viterbi[ tag ] = cpd_tags["START"].prob(tag) * cpd_tagwords[tag].prob( sentence[0] )
first_backpointer[ tag ] = "START"
print(first_viterbi)
print(first_backpointer){‘(-‘: 0.0, ‘UH’: 0.0, ‘EX’: 0.0, ‘–’: 0.0, ‘AP’: 0.0, ‘NI’: 3.3324520848931064e-07, “””: 0.0, ‘MD’: 0.0, ‘`’: 0.0, ‘IN’: 0.0, ‘)’: 0.0, ‘CC’: 0.0, ‘WQ’: 0.0, ‘DT’: 0.0, ‘RB’: 0.0, ‘DO’: 0.0, ‘NP’: 1.7319067623793952e-06, ‘RP’: 0.0, ‘-‘: 0.0, ‘CS’: 0.0, ‘CD’: 0.0, ‘BE’: 0.0, ‘‘: 0.0, ‘FW’: 0.0, ‘END’: 0.0, ‘RN’: 0.0, ‘AT’: 0.0, ‘WD’: 0.0, ‘PN’: 0.0, ‘,-‘: 0.0, ‘,’: 0.0, ‘NR’: 0.0, “’”: 0.0, ‘:’: 0.0, ‘HV’: 0.0, ‘:-‘: 0.0, ‘TO’: 0.0, ‘)-‘: 0.0, ‘WR’: 0.0, ‘NN’: 1.0580313619573935e-06, ‘.’: 0.0, ‘OD’: 0.0, ‘WP’: 0.0, ‘(‘: 0.0, ‘PP’: 0.014930900689060006, ‘QL’: 0.0, ‘AB’: 0.0, ‘JJ’: 0.0, ‘.-‘: 0.0, ‘VB’: 0.0}
{‘(-‘: ‘START’, ‘UH’: ‘START’, ‘EX’: ‘START’, ‘–’: ‘START’, ‘AP’: ‘START’, ‘NI’: ‘START’, “””: ‘START’, ‘MD’: ‘START’, ‘“’: ‘START’, ‘IN’: ‘START’, ‘)’: ‘START’, ‘CC’: ‘START’, ‘WQ’: ‘START’, ‘DT’: ‘START’, ‘RB’: ‘START’, ‘DO’: ‘START’, ‘NP’: ‘START’, ‘RP’: ‘START’, ‘-‘: ‘START’, ‘CS’: ‘START’, ‘CD’: ‘START’, ‘BE’: ‘START’, ‘‘: ‘START’, ‘FW’: ‘START’, ‘END’: ‘START’, ‘RN’: ‘START’, ‘AT’: ‘START’, ‘WD’: ‘START’, ‘PN’: ‘START’, ‘,-‘: ‘START’, ‘,’: ‘START’, ‘NR’: ‘START’, “’”: ‘START’, ‘:’: ‘START’, ‘HV’: ‘START’, ‘:-‘: ‘START’, ‘TO’: ‘START’, ‘)-‘: ‘START’, ‘WR’: ‘START’, ‘NN’: ‘START’, ‘.’: ‘START’, ‘OD’: ‘START’, ‘WP’: ‘START’, ‘(‘: ‘START’, ‘PP’: ‘START’, ‘QL’: ‘START’, ‘AB’: ‘START’, ‘JJ’: ‘START’, ‘.-‘: ‘START’, ‘VB’: ‘START’}
以上,是所有的第一个viterbi 和第一个回溯点。
接下来,把楼上这些,存到Vitterbi和Backpointer两个变量里去
viterbi.append(first_viterbi)
backpointer.append(first_backpointer)我们可以先看一眼,目前最好的tag是啥:
currbest = max(first_viterbi.keys(), key = lambda tag: first_viterbi[ tag ])
print( "Word", "'" + sentence[0] + "'", "current best two-tag sequence:", first_backpointer[ currbest], currbest)Word ‘I’ current best two-tag sequence: START PP
好的
一切都清晰了
我们开始loop:
for wordindex in range(1, len(sentence)):
this_viterbi = { }
this_backpointer = { }
prev_viterbi = viterbi[-1]
for tag in distinct_tags:
# START没有卵用的,我们要忽略
if tag == "START": continue
# 如果现在这个tag是X,现在的单词是w,
# 我们想找前一个tag Y,并且让最好的tag sequence以Y X结尾。
# 也就是说
# Y要能最大化:
# prev_viterbi[ Y ] * P(X | Y) * P( w | X)
best_previous = max(prev_viterbi.keys(),
key = lambda prevtag: \
prev_viterbi[ prevtag ] * cpd_tags[prevtag].prob(tag) * cpd_tagwords[tag].prob(sentence[wordindex]))
this_viterbi[ tag ] = prev_viterbi[ best_previous] * \
cpd_tags[ best_previous ].prob(tag) * cpd_tagwords[ tag].prob(sentence[wordindex])
this_backpointer[ tag ] = best_previous
# 每次找完Y 我们把目前最好的 存一下
currbest = max(this_viterbi.keys(), key = lambda tag: this_viterbi[ tag ])
print( "Word", "'" + sentence[ wordindex] + "'", "current best two-tag sequence:", this_backpointer[ currbest], currbest)
# 完结
# 全部存下来
viterbi.append(this_viterbi)
backpointer.append(this_backpointer)Word ‘want’ current best two-tag sequence: PP VB
Word ‘to’ current best two-tag sequence: VB TO
Word ‘race’ current best two-tag sequence: IN NN
找END,结束:
# 找所有以END结尾的tag sequence
prev_viterbi = viterbi[-1]
best_previous = max(prev_viterbi.keys(),
key = lambda prevtag: prev_viterbi[ prevtag ] * cpd_tags[prevtag].prob("END"))
prob_tagsequence = prev_viterbi[ best_previous ] * cpd_tags[ best_previous].prob("END")
# 我们这会儿是倒着存的。。。。因为。。好的在后面
best_tagsequence = [ "END", best_previous ]
# 同理 这里也有倒过来
backpointer.reverse()最终:
回溯所有的回溯点
此时,最好的 tag 就是 backpointer 里面的 current best
current_best_tag = best_previous
for bp in backpointer:
best_tagsequence.append(bp[current_best_tag])
current_best_tag = bp[current_best_tag]显示结果:
best_tagsequence.reverse()
print( "The sentence was:", end = " ")
for w in sentence: print( w, end = " ")
print("\n")
print( "The best tag sequence is:", end = " ")
for t in best_tagsequence: print (t, end = " ")
print("\n")
print( "The probability of the best tag sequence is:", prob_tagsequence)The sentence was: I want to race
The best tag sequence is: START PP VB IN NN END
The probability of the best tag sequence is: 5.71772824864617e-14
结果不是很好,说明要加更多的语料















 4824
4824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









