









MongoDB数据库存储着非结构化数据,给数据读取之后带来很多需要数据预处理的过程,下面我们来一起总结一下:
1.MongoDB数据库连接,数据表相关数据的读取,包含对相关内容的筛选(in)
from pymongo import MongoClient
import datetime
import csv
import pandas as pd
client1=MongoClient('mongodb://账户:密码@IP:端口/database名')
db1=client1.university#数据库名
mycol=db1.studyrecord#数据表名
cur=mycol.find({"courseid":{"$in":[16967,……]},\
"username":{"$in":['F2847673',……]}},\
{'_id':0,"courseid" :1,"wareid":1,"username" :1,"starttime":1,\
"endtime" :1,"increasetime" :1,"createdate" :1})
study=pd.DataFrame(list(cur),columns=['courseid',"wareid",'username',"starttime",\
"endtime","increasetime","createdate"])#学习记录
client1.close()
2.MongoDB数据库存储时间,有三种常见格式:ISODate(“2021-02-05T03:18:00.509Z”),Date(-62135596800000),这两种时间格式出现在一列如何进行时间筛选,详见文章《pymongo多条件筛选时间报错‘module‘ object is not callable》https://blog.csdn.net/zxxxlh123/article/details/108747680,NumberLong(1612559021241)。
对于类似ISODate(“2021-02-05T03:18:00.509Z”)的时间格式,在作为筛选条件时,采用datetime(2021,2,5,0,0,0,0),具体如下:
cur=mycol.find({"createdate":{"$gte":datetime(2021,2,5,0,0,0,0)},
"courseid":{"$in":[16942,……]}},\
{'_id':0,"courseid" :1,"username" :1})#时间筛选
下面来看一下NumberLong(1612559021241)格式的数据,如何转化为时间格式:
study['starttime'][0]#输出1611633530811
import time
time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(study['starttime'][0]/1000))
#输出'2021-01-26 11:58:50'
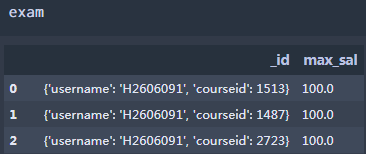
3.将MongoDB数据读入转成数据框,会遇到某一列为字典,需要将字典键值对取出转为多列。
pd.DataFrame(exam['_id'].tolist()
exam=pd.merge(pd.DataFrame(exam['_id'].tolist()),exam[['max_sal']],how= 'inner', left_index=True,right_index=True)#通过索引再与其他列关联
处理前
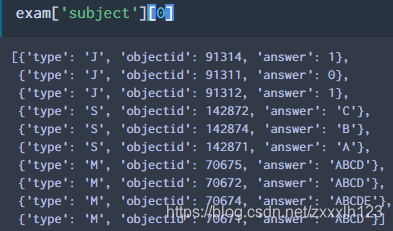
4.将MongoDB数据读入转成数据框,会遇到某一列为列表嵌套字典,需要转为数据框
其中的[‘subject’]列就是列表嵌套字典
df_list = [pd.DataFrame(d) for d in exam['subject']]
df = pd.concat(df_list, keys=exam.index).reset_index(level=1,drop=False)
exam_=pd.merge(exam[['courseid','username',"timestart","timeend","createdate","timeinterval","score"]],df,how='left',left_index=True,right_index=True)#用索引关联原数据框其他列
处理前:

处理后: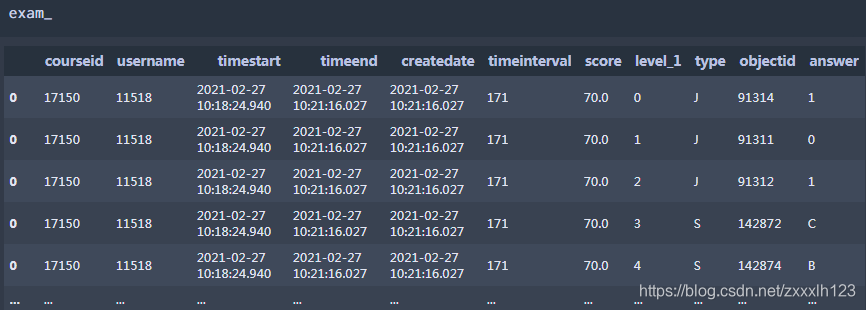
**整理内容不易,走过路过觉得课程内容不错,请帮忙点赞、收藏!Thanks♪(・ω・)ノ****如需转载,请注明出处
参考文献:
https://www.it1352.com/1725492.html
https://blog.csdn.net/Poppy_tester/article/details/105064093














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









