









第2章:Hadoop序列化
2.1 序列化概述
2.1.1什么是序列化
- 序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
- 反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
2.1.2为什么要序列化
- 一般来说,“活的”对象只生存在内存里,关机断电就没有了。而且“活的”对象只能由本地的进程使用,不能被发送到网络上的另外一台计算机。 然而序列化可以存储“活的”对象,可以将“活的”对象发送到远程计算机。
2.1.3 为什么不用Java的序列化
- Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,Header,继承体系等),不便于在网络中高效传输。所以,Hadoop自己开发了一套序列化机制(Writable)。
Hadoop序列化特点:
(1)紧凑 :高效使用存储空间。
(2)快速:读写数据的额外开销小。
(3)可扩展:随着通信协议的升级而可升级
(4)互操作:支持多语言的交互
2.2 自定义bean对象实现序列化接口(Writable)
- 在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。
具体实现bean对象序列化步骤如下7步。
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
public FlowBean() {
super();
}
(3)重写序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
(4)重写反序列化方法
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
(5)注意反序列化的顺序和序列化的顺序完全一致
(6)要想把结果显示在文件中,需要重写toString(),可用”\t”分开,方便后续用。
(7)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序。详见后面排序案例。
@Override
public int compareTo(FlowBean o) {
// 倒序排列,从大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}
2.3 序列化案例实操
1. 需求
- 统计每一个手机号耗费的总上行流量、下行流量、总流量
(1)输入数据
(2)输入数据格式:
| id | 手机号码 | 网络ip | 上行流量 | 下行流量 | 网络状态码 |
|---|---|---|---|---|---|
| 7 | 13560436666 | 120.196.100.99 | 1116 | 954 | 200 |
(3)期望输出数据格式
| 手机号码 | 上行流量 | 下行流量 | 总流量 |
|---|---|---|---|
| 7 | 13560436666 | 1116 | 954 |
2. 需求分析
- 数据如下
1 13631579850 120.196.100.82 2481 24681 200
2 13631579950 120.197.40.4 264 0 200
3 13631579930 120.196.100.99 132 1512 200
4 13631544000 120.197.40.4 240 0 200
5 13631579930 120.196.100.99 1527 2106 200
6 13631579930 120.197.40.4 4116 1432 200
7 13631579930 120.196.100.99 1116 954 200
8 13631579950 120.197.40.4 3156 2936 200
9 13631579830 120.196.100.82 240 0 200
10 13631544000 120.197.40.4 6960 690 200
11 13631579730 120.197.40.4 3659 3538 200
12 13631579930 120.196.100.99 1938 180 200
13 13631544000 120.196.100.99 918 4938 200
14 13631579930 120.197.40.4 180 180 200
15 13631579840 120.197.40.4 1938 2910 200
16 13631579950 120.196.100.82 3008 3720 200
17 13631544000 120.196.100.99 7335 110349 200
18 13631579930 120.196.100.99 9531 2412 200
19 13631579900 120.196.100.55 11058 48243 200
20 13631579930 120.196.100.82 120 120 200
21 13631579850 120.196.100.82 2481 24681 200
22 13631579930 120.196.100.99 1116 954 200
- 统计每个手机号(IP地址)的上行流量和下行流量总流量:
3. 编写MapReduce程序
- 编写流量统计的Bean对象
package com.zhangyong.serialize;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
/**
* @Author zhangyong
* @Date 2020/3/4 16:35
* @Version 1.0
* 编写流量统计的Bean对象
*/
public class FlowBean implements Writable {
private String phoneNumber; //电话号码
private long upFlow; //上行流量
private long downFlow; //下行流量
private long sumFlow; //总流量
public String getPhoneNumber() {
return phoneNumber;
}
public void setPhoneNumber(String phoneNumber) {
this.phoneNumber = phoneNumber;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
@Override
public String toString() {
return "FlowBean{" +
"phoneNumber='" + phoneNumber + '\'' +
", upFlow=" + upFlow +
", downFlow=" + downFlow +
", sumFlow=" + sumFlow +
'}';
}
/**
* 在反序列化时候,反射机制需要调用空参的构造方法
*/
public FlowBean() {
}
/**
* 为了对象数据的初始化方便,提供一个带参的构造方法
* @param phoneNumber
* @param upFlow
* @param downFlow
*/
public FlowBean(String phoneNumber, long upFlow, long downFlow) {
this.phoneNumber = phoneNumber;
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
/**
* 从数据流中反序列出对象的数据。从数据流中读取字段时必须和序列化的顺序保持一致
* @param in
* @throws IOException
*/
public void readFields(DataInput in) throws IOException {
phoneNumber = in.readUTF();
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
public void write(DataOutput out) throws IOException { //将对象数据序列化到流中
out.writeUTF(phoneNumber);
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
}
- 编写Mapper类
package com.zhangyong.serialize;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @Author zhangyong
* @Date 2020/3/4 16:35
* @Version 1.0
* 定义Mapper类
*/
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString (); //拿到一行数据
String[] fields = line.split ("\\s+"); //切分成各个字段
String phoneNumber = fields[1]; //手机号
// 取出上行流量和下行流量
long upFlow = Long.parseLong(fields[fields.length - 3]);//上行流量
long downFlow = Long.parseLong(fields[fields.length - 2]);//下行流量
//封装数据为key-value进行输出
context.write (new Text (phoneNumber), new FlowBean (phoneNumber, upFlow, downFlow));
}
}
- 编写Reducer类
package com.zhangyong.serialize;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @Author zhangyong
* @Date 2020/3/4 16:35
* @Version 1.0
* 定义Reducer类
*/
public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws InterruptedException, IOException {
long upFlowSum = 0; //上行流量计数器
long downFlowSum = 0; //下行流量计数器
for (FlowBean bean : values) {//上行流量和下行流量累加求和
upFlowSum += bean.getUpFlow ();
downFlowSum += bean.getDownFlow ();
}
//将结果输出
context.write (key, new FlowBean (key.toString (), upFlowSum, downFlowSum));
}
}
- 编写Driver驱动类
package com.zhangyong.serialize;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* @Author zhangyong
* @Date 2020/3/4 16:35
* @Version 1.0
* 编写Driver驱动类
*/
public class FlowDriver {
public static void main(String[] args) throws Exception {
// 数据输入路径和输出路径
args = new String[2];
args[0] = "src/main/resources/flowi";
args[1] = "src/main/resources/flowo";
Configuration cfg = new Configuration ();// 读取配置文件
//设置本地模式运行(即使项目类路径下core-site.xml文件,依然采用本地模式)
cfg.set ("mapreduce.framework.name", "local");
cfg.set ("fs.defaultFS", "file:///");
Job job = Job.getInstance (cfg);// 新建一个任务
job.setJarByClass (FlowDriver.class); // 设置主类
job.setInputFormatClass (TextInputFormat.class);//设置输入格式
job.setOutputFormatClass (TextOutputFormat.class);
//本job使用的mapper和reducer
job.setMapperClass (FlowMapper.class); // Mapper
job.setReducerClass (FlowReducer.class); // Reducer
//指定mapper输出数据的key-value类型
job.setMapOutputKeyClass (Text.class);
job.setMapOutputValueClass (FlowBean.class);
//指定最终输出数据的key-value类型
job.setOutputKeyClass (Text.class);
job.setOutputValueClass (FlowBean.class);
FileInputFormat.addInputPath (job, new Path (args[0])); // 输入路径
FileOutputFormat.setOutputPath (job, new Path (args[1])); // 输出路径
// 提交任务
int res = job.waitForCompletion (true) ? 0 : 1;
System.exit (res);
}
}
4. 用本地Hadoop运行程序结果
- 运行完成无报错并生成flowo表示运行成功

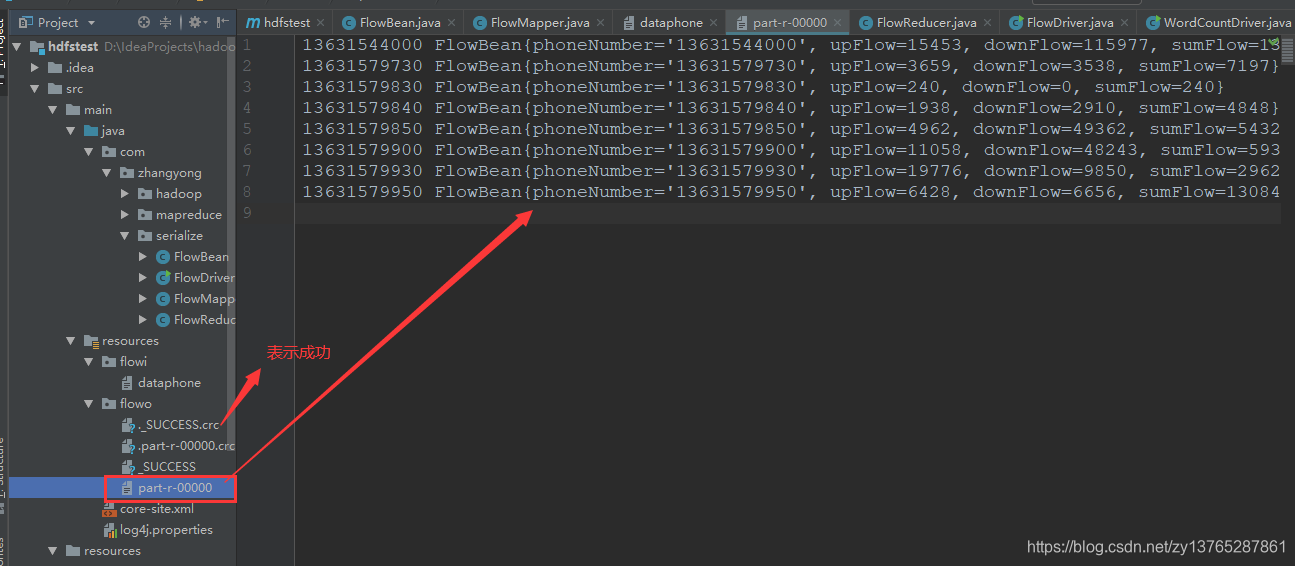
- 结果如下
13631544000 FlowBean{phoneNumber='13631544000', upFlow=15453, downFlow=115977, sumFlow=131430}
13631579730 FlowBean{phoneNumber='13631579730', upFlow=3659, downFlow=3538, sumFlow=7197}
13631579830 FlowBean{phoneNumber='13631579830', upFlow=240, downFlow=0, sumFlow=240}
13631579840 FlowBean{phoneNumber='13631579840', upFlow=1938, downFlow=2910, sumFlow=4848}
13631579850 FlowBean{phoneNumber='13631579850', upFlow=4962, downFlow=49362, sumFlow=54324}
13631579900 FlowBean{phoneNumber='13631579900', upFlow=11058, downFlow=48243, sumFlow=59301}
13631579930 FlowBean{phoneNumber='13631579930', upFlow=19776, downFlow=9850, sumFlow=29626}
13631579950 FlowBean{phoneNumber='13631579950', upFlow=6428, downFlow=6656, sumFlow=13084}














 1007
1007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









