






spark集群搭建
安装虚拟机linux系统-具体参照hadoop 安装文档
克隆三台:
修改网卡信息 改名字及物理地址(ens33,kel 后一般不用改):
vim /etc/udev/rules.d/70-persistent-ipoib.rules

修改主机名
vim /etc/sysconfig/network
修改ip、uuid、HWADDR信息
vim /etc/sysconfig/network-scripts/ifcfg-ens33
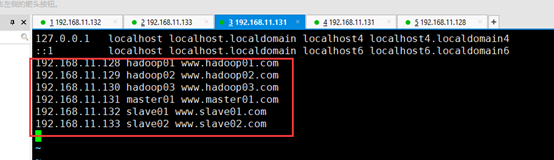
修改映射
vim /etc/hosts 192.168.11.128 hadoop01 www.hadoop01.com 192.168.11.129 hadoop02 www.hadoop02.com 192.168.11.130 hadoop03 www.hadoop03.com 192.168.11.131 master01 www.master01.com 192.168.11.132 slave01 www.slave01.com 192.168.11.133 slave02 www.slave02.com
三台机器都同样配置,并安装好JDK1.8,配好环境变量
以下是我的集群分配:
master01: 主节点:192.168.11.131 slave01: worker :192.168.11.132 slave02: worker :192.168.11.133
开始安装:
- 下载spark-2.1.1-bin-hadoop2.7
- 减压到usr/local/ spark-2.1.1-bin-hadoop2.7
- 修改配置文件
cd /usr/local /spark-2.1.1-bin-hadoop2.7/conf
将slaves.template复制为slaves
将spark-env.sh.template复制为spark-env.sh
修改slave文件,将work的hostname输入:

修改spark-env.sh文件,添加如下配置:

将spark-defaults.conf.template 复制为spark-defaults.conf
修改spark-defaults.conf 文件,添加JAVA_HOME

修改好后,分发到slave01,slave02
scp –r /usr/local/spark-2.1.1-bin-hadoop2.7 slave01:/usr/local/
scp –r /usr/local/spark-2.1.1-bin-hadoop2.7 slave02:/usr/local/
注意,如果没配 ssh免密登录请先配(每次输密码很烦):
在master01这台机器上执行:
ssh-keygen -t rsa
一直回车即可
执行完成后:执行
ssh-copy-id slave01
ssh-copy-id slave02
测试
ssh slave01
ssh slave02
都不需要输入密码即可登录
Spark集群配置完毕,目前是1个Master,2个Work,master01上启动Spark集群
/usr/local/spark-2.1.1-bin-hadoop2.7/sbin/start-all.sh

启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://master01:8080/

到此为止,Spark集群安装完毕.
注意:如果遇到 “JAVA_HOME not set” 异常,可以在sbin目录下的spark-config.sh 文件中加入如下配置:
export JAVA_HOME=XXXX
如果遇到Hadoop HDFS的写入权限问题:
org.apache.hadoop.security.AccessControlException
解决方案: 在hdfs-site.xml中添加如下配置,关闭权限验证
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
配置Job History Server
进入到Spark安装目录
cd /usr/local/spark-2.1.1-bin-hadoop2.7/conf
将spark-default.conf.template复制为spark-default.conf
修改spark-default.conf文件,开启Log:
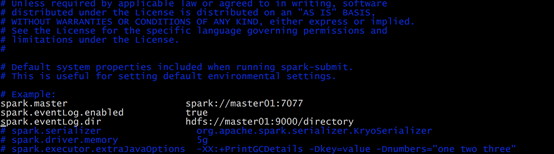
注意:hdfs://master01:9000/directory,有的hdfs 和spark 在不同机器上master01改为自己的hdfs:
我的是:hdfs://hadoop01:9000/directory
如果不知道端口号,请去hadoop主节点上启动hsfs,不需要整个hadoop集群全部启动:
start-dfs.sh
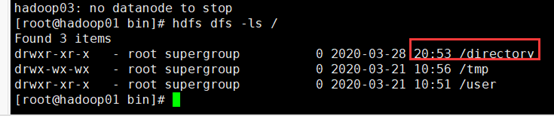
如果hdfs下没有derectory 请先创建
hdfs dfs –mkdir /derectory

spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://master01:9000/directory"
配置号后分发到其他节点上
参数描述:
spark.eventLog.dir:Application在运行过程中所有的信息均记录在该属性指定的路径下;
spark.history.ui.port=4000 调整WEBUI访问的端口号为4000
spark.history.fs.logDirectory=hdfs://master01:9000/directory 配置了该属性后,在start-history-server.sh时就无需再显式的指定路径,Spark History Server页面只展示该指定路径下的信息
spark.history.retainedApplications=3 指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
将配置好的Spark文件拷贝到其他节点上
启动
/usr/local /spark-2.1.1-bin-hadoop2.7/sbin/start-all.sh

启动后执行(请先到启动hdfs,到hadoop集群上启动hdfs)
如hdfs未启动,请去hadoop namenode 上 启动 hdfs:
hadoop-daemon.sh start/stop namenode
hadoop-daemons.sh start/stop datanode
如已启动hdfs,直接启动:
/usr/local/hadoop/spark-2.1.1-bin-hadoop2.7/sbin/start-history-server.sh
成功后成功页面访问
History server访问:http://192.168.11.131:4000/:
spak主节点访问:http://192.168.11.131:8080/
查看hdfs是否启动:http://192.168.11.128:50070



最后测试:
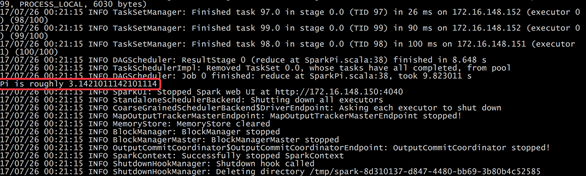
执行第一个spark程序
/usr/local /spark-2.1.1-bin-hadoop2.7/bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://master01:7077 \ --executor-memory 1G \ --total-executor-cores 2 \ /usr/local/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar \ 100
参数说明:
–master spark://master01:7077 指定Master的地址
–executor-memory 1G 指定每个executor可用内存为1G
–total-executor-cores 2 指定每个executor使用的cup核数为2个
该算法是利用蒙特·卡罗算法求PI














 1393
1393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









