








论文:https://openreview.net/forum?id=At9JmGF3xy
代码:https://github.com/Xiangtaokong/TGBD
视觉脑解码旨在通过人类大脑活动解码视觉信息。先前工作通常基于“不同个体的脑活动存在差异”这一观察,对每个受试者分别建模或微调,甚至对脑解码能否泛化至全新受试者都鲜有探索。
本研究旨在探索视觉脑解码在不同受试者上是否有泛化能力。作者首先基于人类连接组计划(HCP)电影观看任务构建了大规模图像-fMRI数据集(177名受试者,55万对数据)。然后提出了统一学习范式,通过体素标准化和共享网络架构处理多受试者数据,避免个体化设计。因此,本研究可以支持大规模受试者训练以研究跨个体泛化能力。本研究通过实验发现:
(1)泛化能力的关键是受试者数量:训练受试者从1名增至167名时,在全新受试者(无需微调)上的图像检索TOP1准确率从2%提升至45%。
(2)泛化能力在不同架构下具备普适性:不同网络架构如MLP、CNN与Transformer均展现出泛化能力。
(3)泛化能力受试者相似性影响:相同性别的受试者之间更容易泛化;相似受试者训练组泛化能力显著优于非相似组。
这些发现揭示了视觉脑信号在不同个体间存在相似性。随着更大规模数据集的涌现,未来有望训练适用于所有受试者的通用的脑解码模型。
01
研究背景
视觉脑解码最近在深度学习技术的支持下,取得了许多新进展。但当前的视觉脑解码研究无论是数据集还是方法,大多集中在研究少量受试者上,且倾向于为每个受试者专门训练或者微调网络结构以及参数。解码模型的广泛应用离不开泛化能力,当面对大量新受试者时,研究人员不可能对每个人都重新调整模型。然而,目前鲜少有工作探讨模型在不同受试者之间的泛化能力,但泛化能力是实现解码模型大规模应用的前提。
(1)数据集
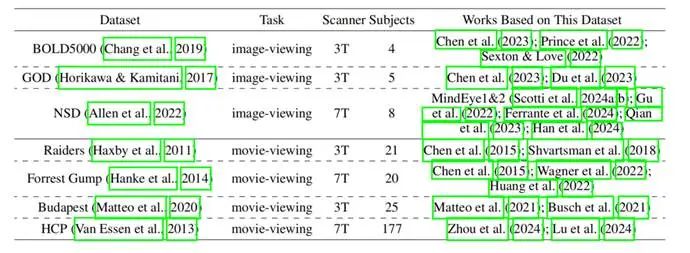
表1 目前常用的视觉脑信号解码数据集
如表1所示,目前常用的视觉脑信号解码数据集(NSD、BOLD)大多只有不到十名受试者,而且许多研究实际只使用了部分受试者数据。这使得现有数据集很难支持泛化性研究,从根本上限制了对跨受试者泛化能力的系统性研究。
(2)现有方法
由于数据集的限制,现有视觉脑解码的方法大多针对几个受试者而设计,比如MindEye1为每个受试者单独训练模型、UMBRAE为每个受试者准备一个分别的网络头。此外,一些方法还需要获得每个受试者的一部分数据做微调训练或者对齐。这些方法无法推广至大规模的新受试者。

表2 UMBRAE和我们的方法面对不同数量受试者时的网络参数量
如表2所示,UMBRAE仅仅为每个受试者准备了10M左右的网络头,在面对大量受试者时,网络规模会线性增大,更不用说对每个受试者都需要训练或微调对齐的方法。除此之外,这些方法在不微调的情况下,即使可以在新受试者上进行推理,但性能也基本完全丧失。
02
探索视觉脑解码的泛化能力
现有的数据集和方法都只针对少量受试者,不具备探索泛化能力的条件。作者选择了基础的fMRI-图像检索任务,构建了大规模的受试者数据集以及新的学习范式,这使得探索泛化性成为可能。
(1)构建大规模受试者数据集
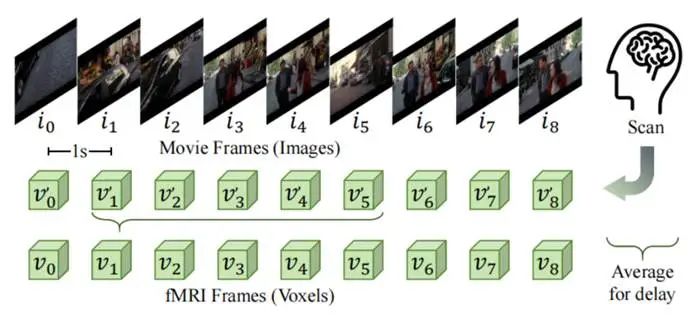
图1 fMRI-图像对数据集的构建
作者使用从HCP数据集的电影观看任务中提取fMRI信号-图像对,提取每秒末帧为刺激图像,基于4秒血流动力学延迟,平均后续4个TR的fMRI信号作为图像对应的fMRI信号。共收集了177名受试者的数据,每名受试者3,127对数据,总规模超55万对。
(2)统一的学习范式
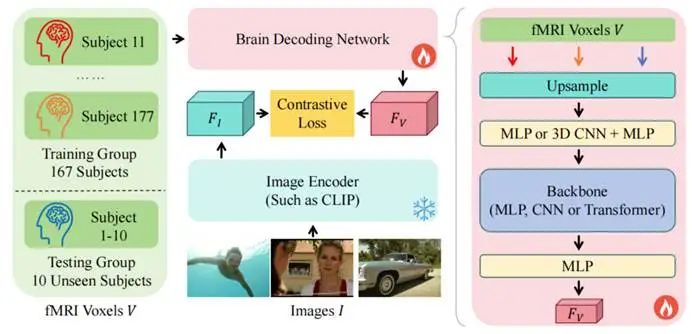
图2 统一处理所有受试者的学习范式
作者同时提出了统一的学习范式,使得网络去除对受试者的特异性设计,可以接受大量受试者同时进行训练。具体来说,先上采样所有受试者全脑的fMRI体素至统一尺寸,再使用MLP/CNN/Transformer等网络结构将体素映射至CLIP特征空间,在CLIP空间中使用双向对比损失(CLIP Loss),最大化对应fMRI-图像对的特征相似性。
03
实验与结论
作者使用fMRI-图像检索任务来进行实验,记录在300个fMRI-图像数据对的检索准确率,以探究解码模型在新受试者上有无泛化能力,以及泛化能力受哪些因素影响。
(1)受试者数量
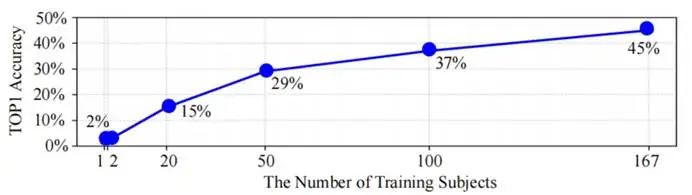
图3 在新受试者上检索准确率与训练受试者数目之间的关系
如图3所示,当受试者数量很少时,网络在新受试者上几乎表现不出泛化能力。但随着训练受试者数量增多,网络在新受试者上的泛化能力逐渐增强。直到达到167名受试者全部参与训练,泛化能力的增长也没有达到饱和。
(2)网络架构
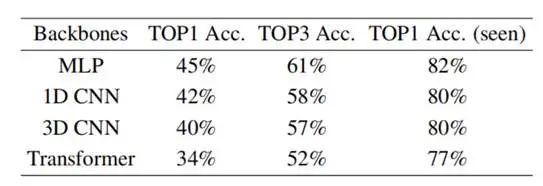
表3 不同网络结构对检索结果的影响
如表3所示,在都使用167名受试者训练时,不同网络结构都在新受试者上表现出了泛化能力。说明视觉脑解码的泛化能力并非是由特定的网络结构带来的,而更可能是人脑活动的相似性带来的。
(3)影响泛化性的因素
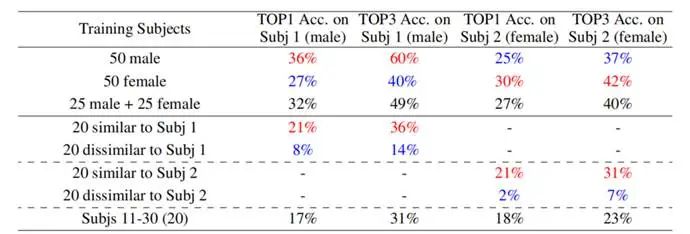
表3 不同相似程度的受试者训练组对检索结果的影响
表3展示了性别和相似程度对泛化能力的影响。第一行使用了50名男性受试者训练模型,结果在未见过的男性测试者上取得了比未见过的女性测试者更好的泛化结果,第二行则相反,使用女性受试者训练的模型也在未见过的女性测试者上取得了更好的结果。
第4-8行显示了更相似的受试者能得到更好的泛化能力,相比于随机选取的20名训练受试者(第8行),使用20名与Subj1更相似(第4行)/更不相似(第5行)的训练受试者都会得到更好/更差的泛化结果。这个结论对于Subj2也成立(第6-7行),说明该现象不依赖于个体个例,而具有广泛适用性。
表3说明泛化能力受受试者之间相似程度的影响,受试者之间越相似,越容易相互泛化。
04
泛化能力的来源
首先,作者认为泛化能力并非源自复杂的上采样(对齐)模块或其他类似机制,而是源于对不同受试者模式的“包含”而非单纯的“对齐”。换言之,本方法在未见受试者上的优异表现源于:训练数据很可能覆盖了这些未见过受试者的某些特征映射模式。所以,随着训练受试者数量增加,泛化性能持续提升。这是因为,训练集更可能包含了新受试者的某些映射模式。同样地,在固定训练人数时,与测试受试者相似性更高的训练组(如性别匹配)往往表现出更强的泛化能力。这同样是因为,相似的受试者更容易“包含”他们之间的相似特征。本研究的核心贡献在于提出一种新视角:泛化能力可通过“包含”足够多样化的受试者群体获得,而非依赖对齐或微调机制;同时,泛化性能亦受个体间相似性影响。
05
总结
先前视觉脑解码研究主要集中于具体受试者,本研究旨在探究视觉脑解码在新受试者上的泛化能力。作者基于HCP大规模数据集,构建了177名受试者的图像-fMRI配对数据。利用该数据集,作者提出了一种统一的学习范式,无需个体特异性适配(即无需为每位受试者单独训练或微调模型),使得探索泛化能力成为可能。通过详细实验,作者发现模型的泛化能力随训练受试者数量增加而逐渐显现,且该能力在不同网络架构(如MLP、CNN、Transformer)中均得以体现。此外,泛化能力会显著被受试者间的相似程度影响。这些发现揭示了人脑活动跨个体的固有相似性,对后续研究具有重要启示。随着更大规模、更多样化数据集的涌现,本工作可为未来训练脑编码基础模型提供理论与方法基础。
仅用于学术分享,若侵权请留言,即时删侵!


加入社群
欢迎加入脑机接口社区交流群,
探讨脑机接口领域话题,实时跟踪脑机接口前沿。
加微信群:
添加微信:RoseBCI【备注:姓名+行业/专业】。
加QQ群:913607986
欢迎来稿
1.欢迎来稿。投稿咨询,请联系微信:RoseBCI
点击投稿:脑机接口社区学术新闻投稿指南
2.加入社区成为兼职创作者,请联系微信:RoseBCI

一键三连「分享」、「点赞」和「在看」
不错过每一条脑机前沿进展



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











