






目录
一. 神经网络简介
二. 误差逆传播(error Back Propagation,BP )算法
三. python代码实现
四. 参考
一. 神经网络简介
神经网络式由具有适应性的简单单元组成的广泛并行交互的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。神经网络最基本的单元是神经元。早在1943年 McCulloch 和 Pitts将生物神经元抽象成如图1的简单模型,即M-P神经元模型。
图1
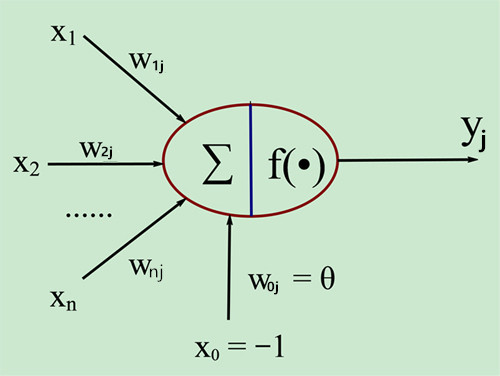
其中红色圈代表当前神经元,xi (i=1....n)是来自前面第i个神经元的输入,对应的wi (i=1....n)分别表示其权值,而x0及其对应权值w0 表示当前神经元的阈值θ。神经元的输出为
在M-P模型中,当前神经元接收来自n个其他神经元的输入信号,这些信号都带有权值。神经元将接收到的总输入值与其阈值进行比较,最后通过激活函数处理后输出。理想的激活函数为阶跃函数图2(a),其输出为0或1,其中0对应抑制,1对应兴奋。但由于其不连续,不光滑等不好的性质,因此常用sigmoid函数作为激活函数,下图2(b)。
图2(a) 图2(b)
图2(b)
神经网络中最简单的是感知机,它仅由输入层和输出层两层神经元组成,如图3。
图3
它能轻松解决与,或,非等非线性问题,但不能解决异或这种非线性问题。因此需要考虑多层神经元,如图4。图4中输入层和输出层之间有一层神经元,叫做隐层(hidden layer),隐层和输出层都是拥有激活函数的功能神经元。每层神经元与下一层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接,这样的神经网络又叫多层前馈神经网络。其中输入层神经元仅接受外界输入,隐层和输出层对信号进行加工,最终结果由输出层神经元输出。神经网络的学习过程就是根据训练集来调整神经元之间的权值和每个功能神经元的阈值。
图4
其他神经网络还有径向基函数(Radial Basis Function,RBF)网络,自适应谐振理论(Adaptive Resonance Theory,ART)网络,自组织映射(Self-Organizing Map,SOM)网络,递归(Recurrent)网络等,图5。
图5

二. 误差逆传播(error Back Propagation,BP )算法
误差逆传播算法是训练神经网络最成功的算法,现实任务中,大多是在使用BP算法进行训练。BP算法不仅可用于多层前馈神经网络还可用于其他类型,如递归神经网络。
误差逆传播算法常与梯度下降结合,因此在这之前先介绍梯度下降。梯度下降是一种常用的一阶优化方法,是求解无约束优化问题最简单,最经典的优化方法之一。梯度下降又包括标准梯度下降和随机梯度下降。其他优化方法还包括牛顿法,坐标下降法,模拟退火法等,由于笔者目前只学习了标准梯度下降,这篇文章只介绍标准梯度下降,其他算法会在随后的文章中专门介绍。
考虑无约束优化问题min(f(x)),其中f(x)是连续可微函数。若存在x0,x1,x2....满足

则在不断迭代的过程中可以收敛到局部最小点。根据泰勒展开式由

欲满足
 式3
式3
其中![]() 是步长,又叫学习率,是一个介于0到1之间的数,
是步长,又叫学习率,是一个介于0到1之间的数, 是梯度。这种方法就是梯度下降法。之所以用梯度的原因是函数沿梯度方向增长最快,反之沿负梯度方向减小最快。
是梯度。这种方法就是梯度下降法。之所以用梯度的原因是函数沿梯度方向增长最快,反之沿负梯度方向减小最快。
给定训练集D={(x1, y1), (x2, y2).....(xm, ym)}, ![]() ,即输入由d个属性描述,输出l维向量。从图5来看,假设,拥有d个输入神经元,l个输出神经元,q个隐层神经元的多层前馈神经网络,其中输出层第j个神经元的阈值用
,即输入由d个属性描述,输出l维向量。从图5来看,假设,拥有d个输入神经元,l个输出神经元,q个隐层神经元的多层前馈神经网络,其中输出层第j个神经元的阈值用![]() 表示,隐层第h个神经元的阈值用
表示,隐层第h个神经元的阈值用![]() 表示。输入层第i个神经元与隐层第h个神经元之间的连接权值为
表示。输入层第i个神经元与隐层第h个神经元之间的连接权值为 ,隐层第h个神经元与输出层第j个神经元之间的权值为
,隐层第h个神经元与输出层第j个神经元之间的权值为 。隐层第h个神经元的输入为
。隐层第h个神经元的输入为 ,输出层第j个神经元的输入为
,输出层第j个神经元的输入为 ,其中bh为第h个隐层神经元的输出。假设激活函数为sigmoid函数f(x)。
,其中bh为第h个隐层神经元的输出。假设激活函数为sigmoid函数f(x)。
对于样本(xk, yk),假设神经网络的输出为
则在对于yk,其均方误差为 ,我们的目的就是要最小化均方误差。
,我们的目的就是要最小化均方误差。
我们采用梯度下降的策略,对任意参数p有 。
。
对于参数,给定学习率![]() 有
有
 式4。
式4。
先影响到 再影响到
再影响到![]() 最后影响到
最后影响到 ,于是有
,于是有
 式5
式5
这就是误差逆传播。
根据链式法则有
 式6
式6
根据有
 式7
式7
对于sigmoid函数有
 式8
式8
根据 和
和 的定义,可以定义一个新变量
的定义,可以定义一个新变量 ,称为隐层梯度,于是有
,称为隐层梯度,于是有
 式9
式9
然后有
 式10
式10
其中 式11。
式11。
其他参数有



BP算法的工作流程为:将输入数据提供给输入层然后继续往前传播,直到得出最终结果,然后计算输出层误差,并将误差逆向传播到隐层,最后根据隐层神经元误差来对阈值和权值进行调整,一直重复上述步骤直到达到某一条件。
三. python代码实现
python实现单隐层前馈神经网络,算法流程依据西瓜书P104:
输入:训练集D={(xk, yk)},k=1,2,...m
过程:
1.在(0,1)范围内随机初始化网络中所有连接权值和阈值
2.while True
3.for all(xk,yk) do
4. 根据当前参数计算出样本输出y_hat
5. 计算输出层梯度gj
6. 计算隐层梯度eh
7. 更新连接权值和阈值
8. end for
9. until 达到停止条件
10. break
输出:连接权值与阈值确定的多层前馈神经网络
在写的过程中尽量少用循环,多用矩阵运算。代码实现的是一次性计算整个训练集而不是单个样本,因此省去了一层循环。
import numpy as np
class Operator:
def calc_hide_input(self, v, x, n_num):
size = x.shape
alpa = np.zeros(shape=(n_num, size[1]))
alpa = np.dot(x, v.T)
return alpa # m*n_num
def calc_hide_grad(self, b, g, omega):
size = b.shape
e = np.zeros(shape=size)
e = np.multiply(np.multiply(b, (1 - b)), np.dot(g, omega))
return e
def calc_hide_output(self, alpa, gamma, n_num):
b = 1 / (1 + np.exp(gamma - alpa))
return b
def calc_output_input(self, omega, b):
size1 = b.shape
size2 = omega.shape
beta = np.zeros(shape=(size1[0], size2[1]))
beta = np.dot(b, omega.T)
return beta
def calc_output_grad(self, y, y_hat):
g = np.multiply(np.multiply(y_hat, (1 - y_hat)), (y - y_hat))
return g
def calc_output(self, beta, thta):
y_hat = 1 / (1 + np.exp(thta - beta))
return y_hat
def update_omega(self, omega, g, b, eta):
hide_out = np.mat(b)
out_grad = np.mat(g)
omega = omega + eta * np.dot(out_grad.T, hide_out)
return omega
def update_thta(self, thta, g, eta):
thta = thta - eta * g
return thta
def update_v(self, v, e, x, eta):
org_input = np.mat(x)
hide_grad = np.mat(e)
v = v + eta * np.dot(hide_grad.T, org_input)
return v
def update_gamma(self, gamma, e, eta):
gamma = gamma - eta * e
return gamma
class NeuralNetwork(Operator):
"""
m为样本数, d为属性数, n_num为隐层神经元数, l为输出y的维数, eta为学习率
x=m*d 样本集
v=n_num*d 输入层到隐层权值
alpa=m*n_num 隐层输入
gamma=m*n_num 隐层阈值
b=m*n_num 隐层输出
omega=l*n_num 隐层到输出层权值
beta=m*l 输出层输入
thta=m*l 输出层阈值
y_hat 输出层输出
e=m*n_num 隐层梯度
g=m*l 输出层梯度
"""
def __init__(self, x, y, n_num, l, eta=1, max_repeat=100):
self.x = np.atleast_2d(x)
self.y = y
self.eta = eta
self.max_repeat = max_repeat
self.n_num = n_num
size = x.shape
m, d = size[0], size[1]
self.count = 0
self.v = np.random.rand(n_num, d)
self.gamma = np.random.rand(m, n_num)
self.omega = np.random.rand(l, n_num)
self.thta = np.random.rand(m, l)
self.alpa = np.random.rand(m, n_num)
self.b = np.zeros(shape=(m, n_num))
self.beta = np.zeros(shape=(m, l))
self.y_hat = np.zeros(shape=(m, l))
self.e = np.zeros(shape=(m, n_num))
self.g = np.zeros(shape=(m, l))
def fit(self):
while True:
self.alpa = self.calc_hide_input(self.v, self.x, self.n_num) #### 隐层输入
self.b = self.calc_hide_output(self.alpa, self.gamma, self.n_num) #### 隐层输出
self.beta = self.calc_output_input(self.omega, self.b) #### 输出层输入
self.y_hat = self.calc_output(self.beta, self.thta) #### 输出
if self.count == self.max_repeat:
print("Fitting completely")
break
self.g = self.calc_output_grad(self.y, self.y_hat) #### 输出层梯度
self.e = self.calc_hide_grad(self.b, self.g, self.omega) #### 隐层梯度
#### 更新连接权值
self.v = self.update_v(self.v ,self.e , self.x, self.eta)
self.omega = self.update_omega(self.omega, self.g, self.b, self.eta)
#### 更新阈值
self.thta = self.update_thta(self.thta, self.g, self.eta)
self.gamma = self.update_gamma(self.gamma, self.e, self.eta)
self.count += 1
return self.y_hat, self.v, self.omega, self.thta, self.gamma下面是测试
x = np.mat(np.array([[0,1,1], [1,1,1], [0, 1, 0], [0, 0, 1], [1, 1, 0]]))
y = np.mat(np.array([[0], [1], [0], [1], [1]]))
nn = NeuralNetwork(x, y, n_num=5, l=1, max_repeat=10000)
y_hat, v, omega, thta, gamma = nn.fit()结果:

可以看出与输入结果已经很接近了,并且总体趋势是对的。
博客写到这里就结束了,第一次写还有很多不足的地方,各位看官也可指出,以后会多多改进。文章思路基本是按照西瓜书的思路,然后结合自己的理解。
四. 参考:
西瓜书















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









