









相对于前面所说的那些MQ前辈们,Kafka可谓是不走寻常路的“天才少年”。与久负盛名的前辈们不同,Kafka从一开始就是走“互联网的野路子”,它抛弃了很多华而不实的企业级特性,专注于高性能与大规模这两个互联网应用的核心需求,并全面采用了新一代的分布式架构 的设计理念,从基因和技术两方面拉开了与前辈们的距离。
我们先来看看Kafka的一些激动人心的特性。
- 高吞吐量、低延迟:Kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 可扩展性:Kafka集群支持热扩展。
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)。
- 高并发:支持数千个客户端同时读写。
Kafka能拥有这样优异的特性,与它的优良设计与编码是分不开的。为了在做到高性能的消息持久化及海量消息时仍能保持常数时间复杂度的访问性能,Kafka特地设计了一个精巧的消息存储系统。Kafka储存消息的文件被称为log,进入Kafka的消息被不断地append到文件末尾,不论文件数据文件有多大,这个操作永远都是0(1)的,而且消息是不可变的,这种简单的log形式的文件结构很好地支撑了高吞吐量、多副本、消息快速持久化的设计目标。此外,消息的主体部分的格式在网络传输中和在log文件上是一致的,也就是说消息的主体部分可以从网络中读取后直接写入本地文件中,也可以直接从文件复制到网络中,而不需要在程序中二次加工,这有利于减少服务器端的开销。Kafka还采用了zero-copy (Java NIO File API)传输技术来提高I/O速度。如果log文件很大,那么查找位于某处的Message就需要遍历整个log文件,效率会很低。为了解决这个问题,Kafka釆用了消息分片 (Partition)、log分段(Segment)及增加索引(index)的 “组合拳”,如下图所示。
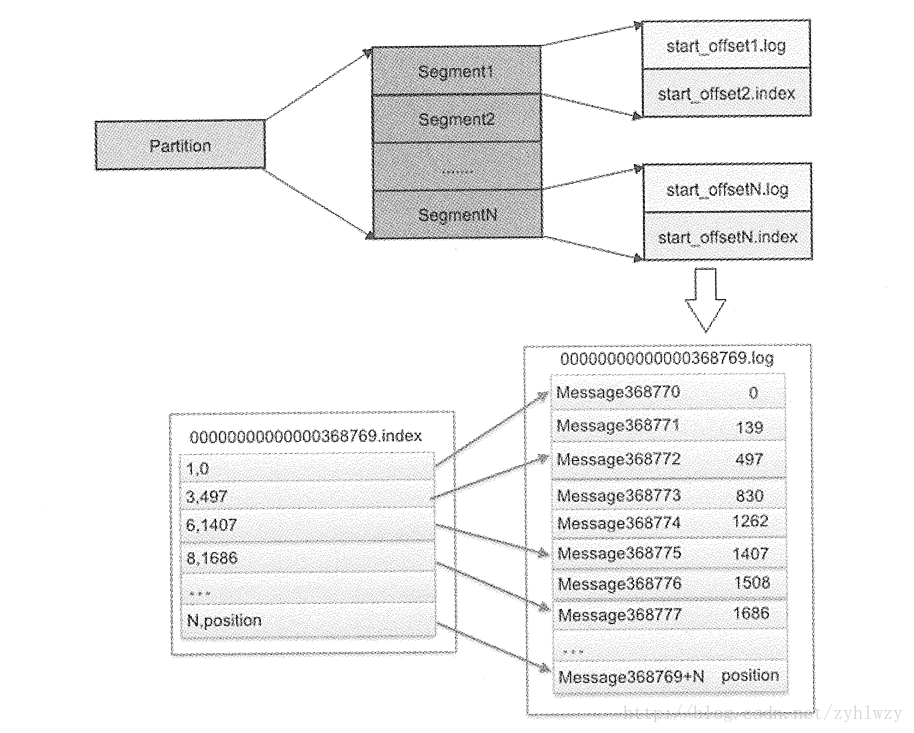
每个Topic上的消息可以被分为N个独立的Partion(分区)存储,每个Partion里的消息Offset(可以理解为消息的ID)从0开始不断递增,M个消息为一组并形成一个单独的Segment,每个Segment由两个文件所组成,其中start_offsetN.index为该Segment的索引文件,而对应的 start_offsetN.log则是保存具体Message内容的log文件。log文件的大小默认为1GB,每个Partion 里的Segment文件名从0 开始编号,后续每个Segment的文件名为上一个Segment文件最后一条消息的offset值,比如上图的00000000000000368769.log文件中存储消息的Offset是从368769+1开始的,直到 368769+N。为了快速定位每个Segment里的某条消息,我们需要知道这个消息在此文件中的物理存储位置,即是从第几个字节开始的。上图中的00000000000000368769.index索引文件就完成了上述目标,文件中的每一行记录了一个消息的编号与它在log文件中的存储起始位置,比如图中的3497这条记录表明Segment里的第3条消息在log文件中的存储起始位置为 497。那么,要查询某个Partion里的任意消息,则如何知道去查哪个index文件呢?其实很简单, index文件名用二分法查找即可,可见编程基础多么重要。为了加速index文件的操作,又可以采用内存映射(MMAP) 的方式将整个或者一部分index文件映射到内存中操作。
接下来我们说说Kafka分布式设计的核心亮点之一的消息分区 。如下图所示,与之前的MQ不同,Kafka里Topic中的消息可以被分为多个Partion,不同的Topic也可以指定不同的分区数,这里的关键点是一个Topic的多个Partion可以分布在不同的Broker上,而位于不同节点上的producer可以同时将消息写入多个Partion中,随后这些消息又被部署在不同的机器上对多个 Consumer分别消费,因此大大增加了系统的Scale out能力。
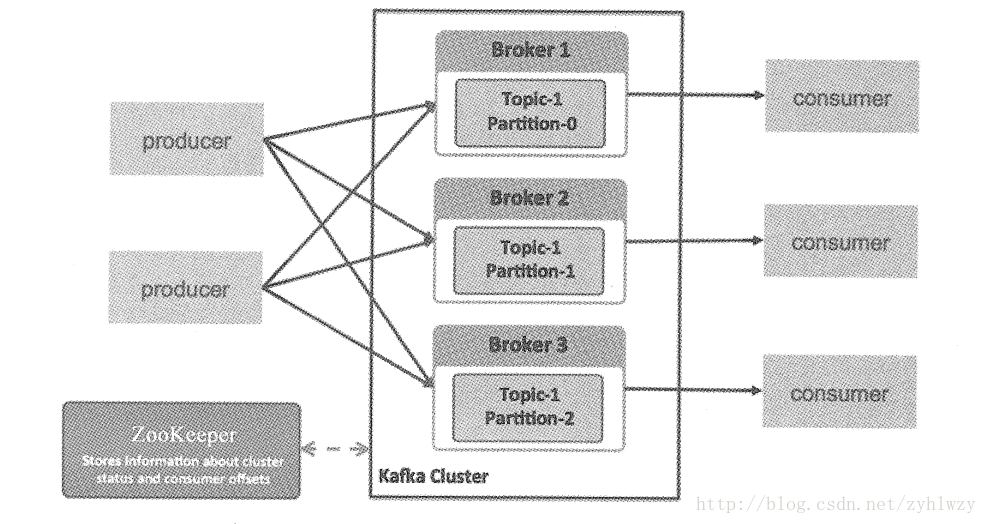
在消息分区的情况下,怎么确定一个消息应该进入哪个分区呢?正常情况下是通过消息的key的 Hash值与分区数取模运算的结果来确定放入哪个分区的,如果key为 Null,则采用依次轮询的简单方式确定目标分区。此外,我们还可以自定义分区来将符合某种规则的消息发送到同一个分区。Kafka要求每个分区只能被一个Consumer消费,所以N个分区只能对应最多N个 Consumer,同时,消息分区后只能保证每个分区下消息消费的局部顺序性,而不能保证一个 Topic下多个分区消息的全局顺序性。在消费消息时,Consumer可以累积确认(Acknowledge)它所接收到的消息,当它确认了某个offset的消息时,就意味着之前的消息也都被成功接收到, 此时Broker会更新ZooKeeper上此Broker所消费的offset记录信息,当 consumer意外宕机后, 由于可能没有确认之前消费过的某些消息,因此ZooKeeper上仍然记录着旧的Offset信息,当 consumer恢复以后,最近消费的消息可能会被重复投递,这就是Kafka所承诺的 “消息至少投递一次”(at-least-once delivery)的背后原因。
我们知道传统的消息系统有两种模型:点对点与发布-订阅模式,Kafka则提供了一种单一抽象模型,从而将这两种模型统一起来,即consumer group。consumer group可以被理解为Topic订阅者的角色,Topic中的每个分区只会被此group中的一个consumer消费,但一个consumer可以同时消费Topic中的多个分区中的消息。比如某个group订阅了一个具有100个分区的topic,它下面有20个 consumer,则正常情况下Kafka平均会为每个consumer分配5个分区。此外,如果一个Topic被多个consumer group订阅,则类似于消息广播。下图中有4个分区的Topic中的每条消息都会被广播到Group A与 Group B中。
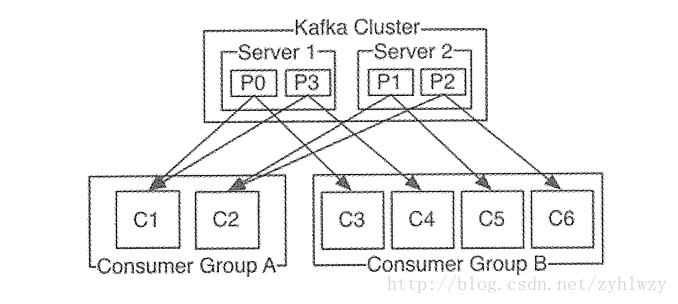
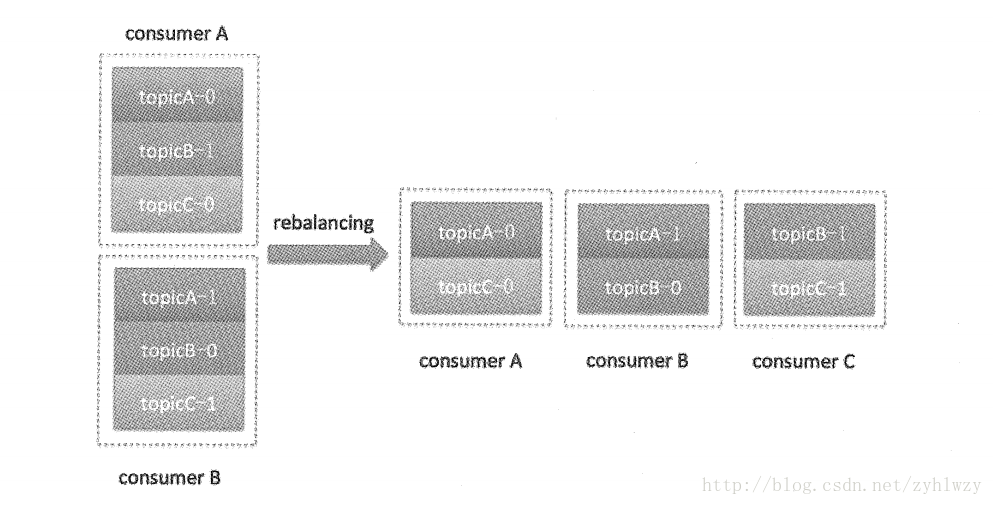
当一个consumer group的成员发生变更时,例如新consumer加入组、己有consumer宕机或离开、分区数发生变化等,都会涉及分区与group成员的重新配对过程,这个过程就叫作 rebalance。下图给出了新consumer加入一个group后的rebalance结果。
我们再看看Kafka是如何解决HA问题的。
由于消息都是保存在每个Broker的本地磁盘中的,所以当某个Broker所在的机器磁盘损坏时,这些数据就永久性地丢失了。对于一个靠谱的消息系统来说,这显然是不可接受的缺陷。通过前面的学习,我们知道,分区结合副本的设计思路已经成为新一代分布式系统中的经典设计套路了,互联网血统出身的Kafka毫无悬念地也采用了这种设计。下图给出了一个分区结合副本模式的高可靠Kafka集群,从图中我们看到Topic A分为两个分区(Partion 1与 2),每个分区都有3 个副本,其中一个副本为Leader,用于写入消息,其他副本为Follower,都从Leader同步消息,这些副本分散在4个Broker上,任何一个Broker失效,都不会影响集群的可用性, 如果这个Broker上恰好承担着某个分区的Leader角色,则通过Leader选举机制重新选择下一 任 Leader。
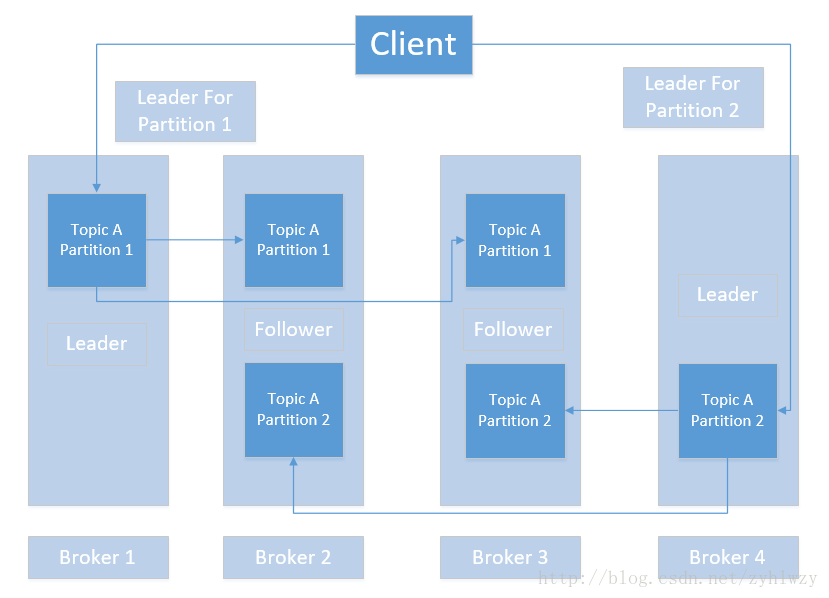
每个分区的Leader会跟踪与其保持同步的Follower节点,该列表被称为ISR ( 即 in-sync Replica) ,如果一个Follower岩机,或者掉队太多(指 Follower复制的消息落后于Leader的条数太多或者Follower的响应太慢),则 Leader将把它从ISR中移除。Producer发布消息到某个Partition之前,会先通过ZooKeeper找到该Partition的Leader,然后写入消息,Leader会将该消息写入其本地Log,而每个Follower都从Leader拉取消息数据,Follower存储的消息顺序与 Leader保持一致。Follower在收到该消息并写入其Log后,向 Leader发送ACK, 一旦 Leader 收到了ISR中所有Follower 的ACK 应答,则该消息被认为已经commit 了,Leader随后将向 Producer发送ACK,确认消息发布成功。
Kafka的复制机制很有趣,它既不是完全意义的同步复制,也不是简单的异步复制。完全同步复制要求所有能工作的Follower都复制完 (而不是仅仅来自ISR列表中的那些Follower), 才能确认消息写入成功,这种复制方式会极大地影响系统吞吐率,而高吞吐率是Kafka追求的非常重要的一个特性,因此这种模式显然不能被接受。而异步复制方式下,数据只要被Leader 写入Log就被认为己经commit,在这种情况下所有Follower都落后于Leader是一个大概率事件,此时如果Leader突然罢工,则很可能会丢失数据,因此也是不能被接受的。而 Kafka使用 ISR名单的同步方式很巧妙地均衡了性能与可靠性这两方面的要求。
















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











