







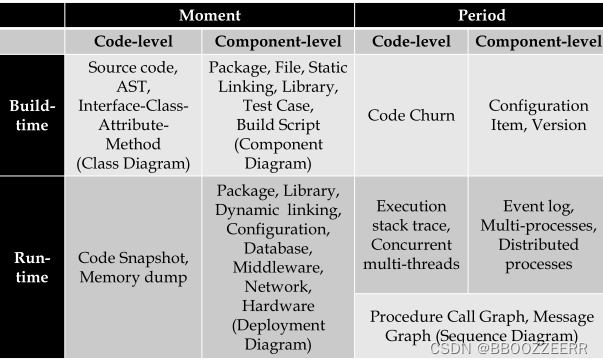
第一节 多维视图和质量目标
软件构造多维度视图
Build-time, moment, code-level
代码如何在逻辑上被组织为基本的程序块,例如函数、类、方法、接口等,以及其之间的依赖关系。
Build-time, period, code-level
代码在时间尺度上的变化,例如代码行的增删改。
Build-time, moment, component-level
源代码被组织为文件,文件被组织进目录;文件被包含在包中,在逻辑上也被包含在容器和子系统中;可复用的模块被组织为库。
Build-time, period, component-level
软件系统中的文件、包、容器、库随时间如何变化,或称版本如何变化。
Run-time, moment, code-level
快照图(snapshot diagram)、内存转储(memory dump)。即软件在运行时保有的数据及其在内存中的结构。
Run-time, period. code-level
顺序图(sequence diagram)、运行时栈跟踪(execution stack trace)
Run-time, moment, component-level
部署图(各个组件被部署在了哪些机器上)。
Run-time, period, component-level
事件日志
Moment 特定时刻的软件形态 Period 软件形态随时间的变化
AST (Abstract Syntax Tree) 抽象语法树
SCI (Software Configuration Item) 配置项
concurrent multithreads 并发多线程
内部质量/外部质量
外部质量因素影响用户,内部质量因素影响软件本身和它的开发者
外部质量取决于内部质量
软件的内部属性和外部属性(判断)
外部质量因素
正确性(Correctness)、健壮性(Robustness)(针对异常情况处理)、可扩展性(Extendibility)、可复用性(Reusability)、兼容性(Compatibility)、性能(Efficiency)、可移植性(Portability)(Java的优点之一)、易用性(Easy of use)、功能性(Functionality)、及时性(Timeliness)
质量目标之间冲突
不同质量因素折中,但”正确性“绝不能与其他质量因素折中
第二、十二节 测试、异常、健壮性
测试(Test)
测试用例 = 输入 + 执行条件 + 期望结果
写spec -> 写符合spec的测试用例 -> 写代码执行测试反复修改
TDD(Test-driven development)
好的测试用例的特性与好的测试的特性相似
*写测试用例时必须既要考虑有效输入也要考虑无效输入
单元测试
针对软件的最小单元模型开展测试,隔离各个模块,容易定位错误和调试
Junit assertEquals assertThat查看实际值是否满足指定条件
黑盒测试/白盒测试
黑盒测试:对程序外部表现出来的行为的测试(从spec导出测试用例,不考虑内部实现)
白盒测试:考虑内部实现细节(一般较早执行)
白盒测试一般由开发人员完成,黑盒测试一般由测试人员完成
白盒测试标准:独立/基本路径测试:对程序所有执行路径进行等价类划分,找出有代表性的最简单的路径(例如循环只需执行一次),设计测试用例使每一条基本路径被至少覆盖一次。
回归测试
一旦程序被修改,重新执行之前的所有测试
代码覆盖度
函数覆盖、语句覆盖、分支覆盖、条件覆盖、路径覆盖
分支覆盖和条件覆盖:分支覆盖 a && b – true/false 条件覆盖:a True a False b True b False
语句覆盖:只需要让 a && b 语句执行一遍即可
条件覆盖和分支覆盖之间没有包含关系
测试效果:路径覆盖 > 分支覆盖 > 语句覆盖(测试难度也是这个顺序)
*等价类划分(重点)
将被测函数的输入域划分成为等价类,从等价类中导出测试用例
例:乘法计算 BigInteger × BigInteger -> BigInteger 函数,可从正/负角度进行等价类划分,同时考虑边界条件—— 0,1,-1,很小的正整数,很小的负整数,很大的正整数,很大的负整数
(注:等价类划分时,错误数据也要考虑其中)?
BVA(Boundary Value Analysis)边界值分析:是对等价类划分方法的补充
在等价类划分时,将边界作为等价类之一加入考虑
(等价类划分具体写法可参见习题课)
健壮性和正确性
可靠性 = 正确性 + 健壮性
健壮性:面向用户 正确性:面向开发者
private方法可只保证正确性,但面向用户的还需要保证健壮性
错误和异常(Error and Exception)
Error:不是由程序本身引起,由系统限制引起
Exception:自己程序导致的问题,可以捕获、处理
下面绿色的部分表示是由用户输入等引起的,是可预测的,在程序运行时处理
不需要实例化Error,也不需要捕获(捕获了也处理不了)
异常分为:运行时异常(RuntimeException)和其他异常
运行时异常是程序员代码里处理不当造成,其他异常由外部原因造成
Checked and unchecked exceptions
Unchecked exceptions = Error + RuntimeExceptions
两者区分:编译器是否能检查出(编译器不会检查Unchecked exception)
checked exception 必须捕获并指定错误处理器handler,否则编译无法通过
五个处理异常时使用的关键字:try,catch,finally,throws,throw
Unchecked异常也能用try/catch来进行捕获,但大多数时时不需要的,也不应该这样做——掩耳盗铃,对发现的编程错误充耳不闻!
尽量用unchecked exception来处理编程错误——使代码更易读
错误可预料,不可预防,但有手段从中恢复,用checked exception
该表需要记住)
规约中需要包含所有该方法抛出的checked exception
异常的抛出需要满足LSP原则(协变):子类不能比父类抛出更多、更宽泛的异常
可自定义异常类
异常发生后如果找不到处理器,就终止程序,在控制台打印出 stack trace
异常只有两种处理方法:向上抛 / 捕获
如果父类型的方法没有抛出异常,那么子类型中的方法必须捕获所有的checked exception
try- catch -finally:无论是否出现异常,finally块中包含的语句都会被执行(一般为对资源的释放、管理等)
多个catch块不是依次顺序执行的,而是并发的,哪一个最匹配就执行哪一个
finally会在执行完try/catch块之后再执行
第三节 构造过程与配置管理
软件的过程模型
(会考察软件使用哪一种开发模型)
两种基本形式:Linear-线性过程 Iterative-迭代过程
五种模型:瀑布过程、增量过程、V字过程、原型过程、螺旋模型
瀑布模型(Waterfall)(顺序,不可迭代)
描述:按阶段实现软件,基本分为需求-设计-实现-验证-维护。
特点:容易使用,但实现后更改需求代价较大。
增量模型(Incremental)(不可迭代)
描述:软件被逐次一点点地设计、实现和测试,直至完成。相当于瀑布模型的反复增量完成。
特点:系统被分为许多子项目;高优先级的需求被首先完成;当一部分完成后,该部分的需求将被冻结。
V模型(V model)(为了测试)
描述:可看做是瀑布模型的扩展。阶段为:需求分析-概要设计-详细设计-软件编码-单元测试-集成测试-系统测试。
特点:适用于易被模块化的传统软件开发,开发和测试同时进行。
原型模型(Prototyping)(可迭代)
描述:产品原型仅模拟了最终产品的一部分,且可能完全不同。阶段为:确定基本需求-实现原型-复审-改进原型。
特点:软件设计者和开发者可从用户处得到反馈;客户可在软件开发过程中及时评价软件是否满足需求;总工程师可通过原型设计过程摸清软件架构,以及推算deadline可否满足。
螺旋模型(Spiral)(可迭代)
描述:螺旋模型是一个风险驱动模型,通过分析项目当前面临的风险来选择适当的开发模型(如瀑布模型等)。
特点:引入风险分析,使软件开发面临巨大风险时有机会停止;在每个迭代阶段构建原型以减小风险;适合大型昂贵系统开发。
敏捷开发(Agile development)
通过快速迭代和小规模的持续改进,快速适应变化。
要求:1. 强调交互 2. 不需要文档 3. 合作 4. 变化
适用于需求不稳定,快速开发(对高质量、高风险不适用)
SCM(软件配置管理)
软件配置管理:追踪和控制软件的变化。 软件配置项:软件中发生变化的基本单元
VCS(版本控制系统)
本地版本控制系统:仓库存储在开发者本地及其,无法共享和合作。
集中式版本控制系统:仓库存储于独立的服务器,支持多开发者之间协作。
分布式版本控制系统:仓库存储于独立的服务器 + 每个开发者的本地机器。(如Git)
*Git(重点)
Git的四个工作区域
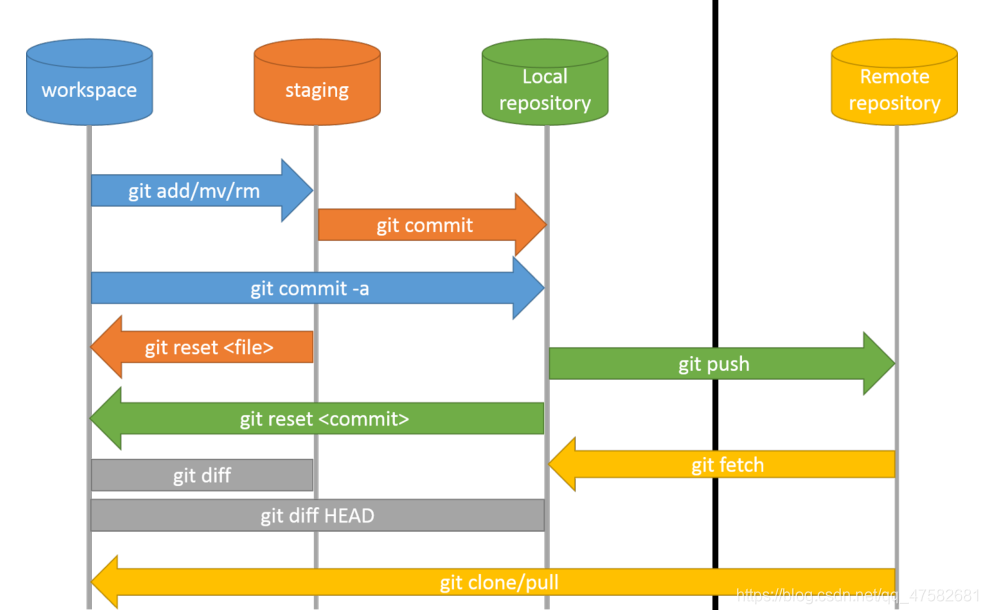
工作区,即平时存放代码的地方。
暂存区,虚拟区域,无真实空间,用于临时存放改动。
本地仓库,安全存放数据的位置,这里有提交到所有版本的数据
远程仓库,托管代码的服务器,如Github
需要掌握根据Git文件的状态来判断处于哪一目录/区域中。
Object Graph
边 A -> B表示在版本B的基础上作变化形成了版本A(指向的对象是父对象)
除了最初的commit,每个commit都有一个指向父亲的指针
多个commit指向同一个父亲——分支
一个commit指向两个父亲——合并
Git中一个子对象只能有0,1,2个父对象,而一个父对象可以有多个子对象。
Git和传统版本控制工具的区别:Git存储的是变化后的文件,传统VCS存储版本之间的变化(行),很难创建分支。
Git一个文件可以存在在不同的版本中。
Git命令和版本图
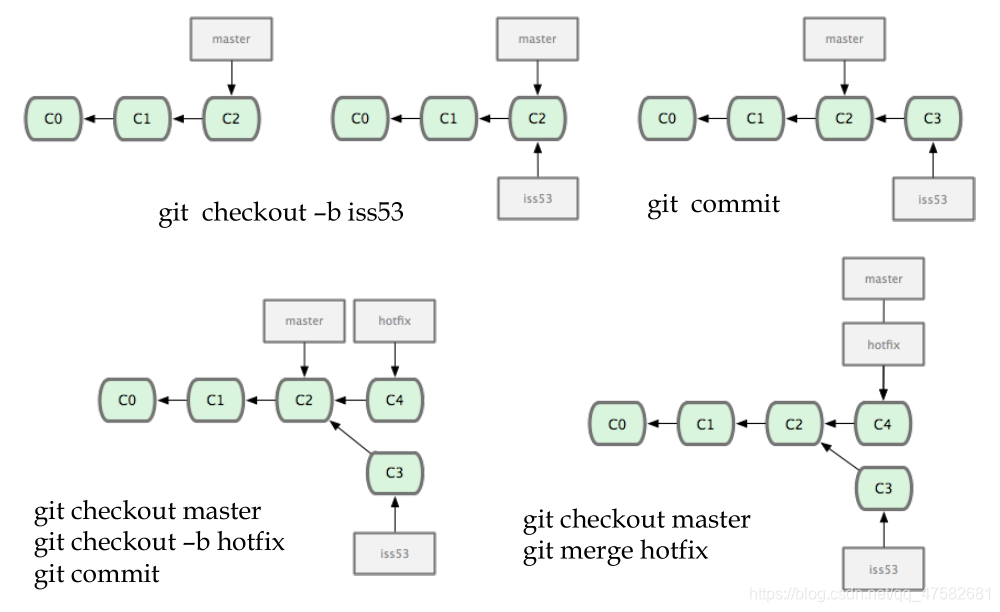
git commit -a :把所有的change先add然后再commit
git fetch :从远程获取最新版本到本地,不会自动merge
git checkout -b:创建并切换分支
git remote add origin … :与远程仓库关联
注:git会强制在push之前fetch(如果远程端做了更改),然后再merge和push
第四节 数据类型和类型检验
基本数据类型/对象数据类型

静态/动态类型检查
(Java是静态类型检查,在编译阶段进行检查,Java不进行动态类型检测)
静态类型检查:语法、类名/函数名、参数数目、参数类型、返回值类型
动态类型检查:非法的参数值、非法的返回值、越界、空指针
注意List<String>和List<Object>是在静态类型检测中报错。
Mutable/Immutable
Java可进行自动垃圾回收。 Immutable好处:安全,但浪费空间。
*final特性: final 限定的是引用不变(如果mutable改变值不会报错),final类无法派生子类,final方法无法被子类重写。
使用Mutable可获得更好的性能,也适合多个模块间共享数据,但不够安全!
Date也是mutable类!避免使用!
可以使用java.time包中的其他immutable类型的类:LocalDateTime, Instant等
immutable拷贝时间 O(n2)
传参数尽量用immutable类型(保证参数不变性),如果传mutable参数可先进行defensive copying(考试经常考)
必须通过类中的方法来改变类中的属性(防止信息泄露)
*Snapshot diagram(重点)
Immutable对象:用双线椭圆
不可变的引用(用final修饰的变量):用双线箭头
String s1 = new String("abc");
List<String> list = new ArrayList<String>();
list.add(s1);
s1 = s1.concat("d");
System.out.println(list.get(0));
String s2 = s1.concat("e");
list.set(0, s2);
System.out.println(list.get(0));
Array and Collections
Iterator
mutable类型,有两种方法:next()和hasNext(),next()方法是mutate的
需要注意,当用Iterator迭代List中元素,涉及到remove时,由于remove后List内元素索引会发生改变,会出现错误。
Collections
基本类型及其封装对象类型都是immutable的
List、Map、ArrayList等都是mutable的
可以利用Collections类提供的方法将mutable类包装成immutable
Collections.unmodifiableList Collections.unmodifiableSet Collections.unmodifiableMap
这种包装器得到的结果是不可变的,只能看,不能修改(其实就是disabled了一些mutate方法或者让其抛出异常)
这种”不可变“是在运行阶段获得的,编译阶段无法对此进行静态检查
虽然不能用包装后的对象对其进行修改,但依旧能用包装前的对象进行修改
第五节 设计规约
规约(Specifications)
规约不要给出任何方法的实现。
规约不能被程序进行检测 (×) ——函数描述可以被检测(参数类型),注释不能被检测。
规约注释包含:功能描述、输入数据限制、返回值
行为等价性(Behavioral equivalence)
一般站在用户(客户端)的角度看(可能会给一定前提),可根据规约判断是否行为等价
前置条件和后置条件
前置条件,关键词requires 后置条件,关键词effects
前置条件是对客户端的约束,在使用方法时必须满足的条件;后置条件是对开发者的约束,方法结束时必须满足的条件
如果前置条件满足,后置条件必须满足;如果前置条件不满足,后置条件想淦神魔都可以
Java中的规约
Java中的静态类型声明是一种规约,可据此进行静态类型检查static checking
方法前的注释也是一种规约,但需要人工判定其是否满足
前置条件在 @param中,后置条件在 @return和@throws中(@return中不能包含具体类型,如 @return boolean)
如果方法对输入的参数做了改变,一定要在规约中说明
*规约的强弱(本节重点)
判定标准
规约强度 S2 >= S1 : 前置条件更弱,后置条件更强
spec变强,即更放松的前置条件 + 更严格的后置条件
(考试常出无法比较的规约)
Diagramming specifications
每一个点代表一个方法的实现。如果某个具体实现满足规约,就落在其范围内;否则在其之外。
更强的规约,表示为更小的区域。(实现的自由度小,面积小)
第六节 抽象数据类型(ADT)
ADT 的特性:表示泄漏、抽象函数 AF 、表示不变量 RI
基于数学的形式对 ADT 的这些核心特征进行描述并应用于设计中
(本节常考大题,包括是否出现表示暴露,AF和RI等)
ADT是由操作定义的,与其内部实现无关
ADT四种操作类型
构造器(Creator):创建一个该类型的新对象(可能实现为构造函数或静态函数)
生产器(Producer):从一个类型的旧对象创建一个新对象(如String中concat方法)
观察器(Observer):返回一个不同类型的对象(如List中的size方法)
变值器(Mutator):改变对象属性的方法(如List中的add方法)
如果一个构造器是用静态方法来实现的,通常称为工厂方法 (factory method):如Java中String类的String.valueOf(Object obj)方法
Mutators通常返回void,但也可以返回非空类型,如Set.add()返回的类型为boolean
immutable类型的ADT无变值器(Mutator)
判断是哪种操作类型,首先需要确定是mutable还是immutable
注:Collections.unmodifiableList() 是 producer; 如果一个方法既改变了对象属性,也返回了不同类型的对象,它是变值器Mutator
*表示独立性(Representation Independence)
表示独立性:client使用ADT时无需考虑其内部如何实现,ADT内部表示的变化不应该影响外部spec和客户端。
上述实例就违反了表示独立性,因为public限定了这是一个instance variable,但是后面的final又限定了客户端不能够实际改变这个类的immutability属性
*不变性(Invariants)
由ADT来负责其不变量,与client端的任何行为无关
(考试必考表示泄露)
表示泄露出现情况:
public 类型的数据 -> private final
mutable 类型共享引用
不应该包含mutate方法
当复制代价很高时,可在规约中强加条件(但是不推荐!)
*Rep Invariant and Abstraction Function(RI and AF)
R : 表示空间 A:抽象空间(ADT开发者关注表示空间R,client关注抽象空间A)
R -> A 的映射:1. 满射:所有抽象值都要有一个rep value 2. 未必单射:一个抽象值可能有多个表示 3. 未必双射:不是所有的表示值都有对应的抽象值
抽象函数(AF):R和A之间映射关系的函数
表示不变性 RI:某个具体的“表示”是否是“合法的”(R -> boolean)
在ADT的规约里若出现"值",也只能是A空间的"值"
有益的可变性(Beneficent mutation)
(该部分大概率会出选择)
即immutable的属性是可变的,但是要保证用户角度是一样的
例如:[1, 2] 和 [2, 4]在A空间可均表示1/2
书写AF和RI
可用ADT的不变量来代替前置条件(相当于将复杂的precondition封装到了ADT内部)
第七节 面向对象的编程(OOP)
静态/实例方法
在类中使用static修饰的静态方法会随着类的定义而被分配和装载入内存中;而非静态方法属于对象的具体实例,只有在类的对象创建时在对象的内存中才有这个方法的代码段
编译器只为整个类创建了一个静态变量的副本,也就是只分配一个内存空间,虽然可能有多个实例,但这些实例共享该内存
接口(Interface)
接口之间可以继承与扩展,一个类可以实现多个接口,一个接口可以有多种实现类
接口:确定ADT规约; 类:实现ADT
Java的接口中不能含有constructors,但是从Java 8开始接口中可以含有static工厂方法,可用其替代constructors
default
通过default方法,可以在接口中统一实现某些功能,无需在各个类中重复实现它。好处是以增量式为接口增加额外的功能而不破坏已经实现的类
重写(Overriding)
严格继承:子类只能添加新方法,无法重写超类中的方法
如果想要一个java中方法不能被重写,必须要加上前缀final
父类型中的被重写函数体不为空:意味着对其大多数子类型来说,该方法是可以被直接复用的。对某些子类型来说,有特殊性,故重写父类型中的函数,实现自己的特殊要求
如果父类型中的某个函数实现体为空,意味着其所有子类型都需要这个功能,但各有差异,没有共性,在每个子类中均需要重写
重写时,可以利用super()来复用父类型中函数的功能
抽象类(Abstract Class)
抽象方法:只有声明没有具体实现的方法。用关键词abstract来定义
抽象类:如果一个类含有至少一个抽象方法,则被称为抽象类
接口:一个只含有抽象方法的抽象类
如果某些操作是子类型都共有,但彼此有差别,可以在父类型中设计抽象方法,在各子类型中重写
接口和抽象类都不能实例化!
多态、子类型、重载(Polymorphism, subtyping and overloading)
(考试经常出现重载和重写的对比考察)
多态的三种类型
特殊多态(Ad hoc polymorphism):重载
参数化多态(Parametric polymorphism):泛型
子类型多态、包含多态(Subtyping):继承
特殊多态和重载(Overloading)
重载:多个方法具有同样的名字,但有不同的参数列表或返回值类型
重载是一种静态多态,根据参数列表进行"最佳匹配",进行静态类型检查
重载的解析在编译阶段,与之相反,重写的方法是在运行阶段进行动态类型检查
参数列表必须不同
相同/不同的返回值类型
相同/不同的public/private/protected
可以声明新的异常
Overloading和Overriding的对比
参数多态和泛型(Generic)
泛型擦除:运行时泛型类型消除(如:List<String>运行时是不知道String的),所以,不能使用泛型数组(如: Pair < String >[] foo = new Pair < String >[42]; 是错误的!不能被编译!)
如下是一个错误的实例:
List<Object> a; List<String> b; a = b;
通配符(Wildcards),只在使用泛型的时候出现,不能在定义中出现。 如:List< ? extends Animal >
?extends T 和 ?super T 分别表示T和它的所有子/父类
子类型多态、继承
重写时,子类的规约要强于父类的规约(更弱的前置条件,更强的后置条件)
子类的可见性要强于父类(即父类如果是public,子类不能为private)
子类不能比父类抛出更多的异常
(详情见LSP原则)
注:Java无法检测1,但是可以检测出2、3
子类型多态:不同类型的对象可以统一的处理而无需区分。
instanceof
instanceof()判断对象运行时的类型
注:其父类也会判为true,如 a instanceof Object 始终为true
getclass()获取当前类型
List<Object>不是List<String>的父类
List<String>是ArrayList<String>的父类
List<?> 是 List<String>的父类
注:重写equal()方法时,需要注意参数类型,必须也是Object类型
第八节 ADT和OOP中的相等性
相等关系
相等关系是一种等价关系,即满足自反、对称、传递
可以用"是否为等价关系"来检验equals()是否正确
Immutable类型的相等
判相等要从A空间来看(用户角度) AF映射到相同结果,则等价
站在外部观察者角度:对两个对象调用任何相同的操作,都会得到相同的结果,则认为这两个对象是等价的。
== vs. equals()
== 表示的是引用等价性(一般用于基本数据类型的相等判定)
equals()表示的是对象等价性 (用于对象类型相等判定)
在自定义ADT时,需要重写Object 的 equals() 方法
equals()方法的实现
在Objects中实现的缺省equals()是在判断引用相等性(相当于==)
用instanceof操作可以判断对象是否是一种特殊的类型(用instanceof是一种动态类型检查,而不是静态类型检查)
注意:不能在父类中用instanceof判断子类类型
等价的对象必须拥有相同的hashCode;不相等的对象也可以映射为同样的hashCode,但是性能会变差
重写equals方法必须要重写hashCode方法(除非能保证你的ADT不会被放入到Hash类型的集合中)
mutable类型的相等
观察等价性:在不改变状态的情况下,两个mutable对象是否看起来一致
行为等价性:调用对象的任何方法都展示出一致的结果
对于mutable类型来说,往往倾向于实现严格的观察等价性(但是在有些时候,观察等价性可能导致bug,甚至破坏RI)
注意:如果某个mutable的对象包含在Set集合类中,当其发生改变后,集合类的行为不确定!
Collections 使用的是观察等价性,但是其他的mutable类(如StringBuilder)使用的是行为等价性
对mutable类型,实现行为等价性即可。也就是说只有指向同样内存空间的objects,才是相等的,所以对mutable类型来说,无需重写这两个函数,直接调用Object的两个方法即可。(如果一定要判断两个对象"看起来"是否一致,最好定义一个新方法,e.g. similar() )
immutable类型必须重写equals() 和 hashCode()
mutable类型可以不重写,直接继承自Object
clone()
clone()创建并返回对象的一个copy
浅拷贝:对于基本数据类型,无影响;对于数组或对象数据类型,浅拷贝只是将内存地址赋值给了新变量,它们指向同一个内存空间。改变其中一个对另一个也会产生影响。
Java中的clone实现的是浅拷贝。
要避免一些问题,建议使用深拷贝。
Autoboxing
Integer 和 int 注意区别
flase
(Numbers between -128 and 127 are true.)
第九节 面向复用的软件构造技术
(重点:LSP和组合与委托)(考试大部分为小题,LSP会出大题)
复用的类型
软件复用:最主要的是代码复用,但也有其他方面。
Source code level:methods, statements, etc Module level:class and interface Library level:API Architecture level:framework
白盒复用:源代码可见、可修改和扩展(对应继承)
黑盒复用:源代码不可见,不能修改,只能通过API接口使用(对应委托)
代码复用
即直接复制代码(不推荐)
类的复用
inheritance 继承 delegation 委托
继承能做的事委托也能做,继承要求严格父子关系
框架(framework)
框架:一组具体类、抽象类、及其之间的连接关系
开发者根据framework的规约,填充自己的代码进去,形成完整系统
API和框架的区别:主控端在用户/框架
*LSP(重点)
子类型多态:客户端可以用统一的方式处理不同类型的对象。
LSP原则
能被Java静态类型检测检测出的:
子类型可以增加方法,但不可以删除方法
子类型需要实现抽象类型中的所有未实现的方法
子类型中重写的方法必须返回相同的类型或者子类型(满足协变)
子类型中重写的方法必须使用同样类型的参数(或符合逆变的参数)
子类型中重写的方法不能抛出额外的异常(协变)
不能被静态类型检测出的:
更强的不变量
更弱的前置条件
更强的后置条件(与上条综合即规约更强)
协变:父类型->子类型:越来越具体
反协变(逆变):越来越抽象
注意:Java不支持反协变!Java识别其为重载(而非重写)
数组满足协变。
泛型中的LSP
泛型不满足协变 List<String>不是List<Object>的子类型
Object是所有泛型的父类,List<?>是List<Object>的父类
(该图为考点!)
委托(Delegation)
Interface Comparator< T >
int compare(T o1, T o2): Compares its two arguments for order
如果你的ADT需要比较大小,或者要放入Collections或Arrays进行排序,可以实现Comparator接口并且override compare()函数
另一种方法:让ADT实现Comparable接口,然后override compareTo() 方法
与使用Comparator的区别:不需要构建新的Comparator类,比较代码放在ADT内部
委托
委托/委派:一个对象请求另一个对象的功能。
如果子类只需要复用父类中的一小部分方法,可以通过委托机制调用。
委托是复用的一种常用形式。(CRP原则:尽量使用委托进行复用)
Use 使用:通过方法的参数传递(use_a)
Association 关联:通过类的属性传递(has_a)
class B{
void b(A a){ //use 使用
...
}
}class B{
A a; //Association 关联
....
}
composition/aggregation 组合/聚合(可认为是Association的两种具体形态)
聚合运行时可更改绑定对象(较弱的关联)
聚合B类销毁时,A类可能不会销毁(可能还有指向其的指针);组合B类销毁时,A类同时被销毁
第十节 面向可维护性的软件构造技术
(本章重点:SOLID、正则表达式)
可维护性度量指标
圈复杂度(Cyclomatic Complexity)、代码行数、可维护性指数(MI)、继承的层次数、类之间的耦合度、单元测试的覆盖度
模块化编程
高内聚(High cohension) 低耦合(Low coupling)
耦合(Coupling):不同模块之间的相互依赖性
内聚(Cohension):模块内功能和职责的一致性
耦合和内聚之间的权衡:
即不能同时高/同时低
SOLID设计原则
SRP(单一责任原则)
OCP(开放-封闭原则)
LSP(Liskov替换原则)
DIP(依赖转置原则)
ISP(接口聚合原则)
SRP(单一责任原则)
把类拆分,使得每个类只完成一个功能。(不应该有多于一个的原因使得类发生变化)
SRP是最简单的原则,却是最难做好的原则
OCP(开放/封闭原则)
对扩展性的开放:模块的行为应该是可扩展的
对修改的封闭
关键的解决方案:抽象技术
例:如果有多种类型的Server,那么针对每一种新出现的Server,不得不修改Server类的内部具体实现;
通过构造一个抽象的Server类:AbstractServer,该抽象类中包含针对所有类型的Server都通用的代码,从而实现了对修改的封闭;当出现新的Server类型时,只需从该抽象类中派生出具体的子类ConcreteServer即可,从而支持了对扩展的开放。
LSP(Liskov替换原则)
详情见第九节LSP原则
ISP(接口隔离原则)
尽量和专用接口连接(客户端不应依赖于它们不需要的方法)
DIP(依赖转置原则)
尽量依赖抽象类而不是具体类
也就是delegation的时候,通过interface来建立联系,而非具体子类
正则表达式
*:重复0-多次
|:选择 a|b
?:0次或1次 x ::= y ? x为y或空串
[a-c]:‘a’ | ‘b’ | ‘c’
[^a-c]:‘d’ | ‘e’ | ‘f’ …(相当于补)
Parse Tree
正则语法(Regular grammar)
正则语法:简化之后可以表达为一个产生式而不包含任何非终止节点
正则表达式:左侧为非终结符,右侧没有非终结符
注意有的字符需要进行转义
Java中的正则表达式
Pattern是对regex正则表达式进行编译之后得到的结果
Matcher:利用Pattern对输入字符串进行解析
Matcher对象只能通过Pattern静态方法创建,不能new
第十一节 设计模式
分为以下三类模式:创建型模式、结构型模式、行为型模式
创建型模式(Creational patterns)
*工厂方法模式(Factory Method pattern)
当client不知道要创建哪个具体类的实例,或者不想再client代码中指明要具体创建的实例时,用工厂方法。
工厂模式:将创建一个对象的方法委托给另一个类(工厂类)来实现
Client用工厂方法来创建实例,得到的实例类型是抽象接口而非具体类
静态工厂方法(在工厂方法前加static):既可以在ADT内部实现,也可以单独创建工厂类
该设计模式是OCP(扩展/开放原则)的一个体现。
优点:实现信息隐藏
缺点:需要额外创建工厂类,程序更复杂
结构型模式(Structural patterns)
适配器模式(Adapter)
将某个类/接口转换为client期望的其他形式(主要解决接口不匹配问题)
通过增加一个接口,将已存在的子类封装起来,client面向接口编程,从而隐藏了具体子类
装饰器模式(Decorator)
对一个类的功能进行扩充(实现特性的组合)
装饰器在运行时组合特性;继承在编译时组合特性
行为型模式(Behavioral patterns)
*策略模式(Strategy)
使用功能的时候不访问功能实现,访问接口(在多个功能间灵活切换)
考试时一般要做的:1. 抽象出一个接口类 2. 调用接口
*模板模式(Template Method)
共性的操作步骤在抽象类中公共实现,差异化的步骤在各个子类中实现
使用继承和重写来实现模板模式
模板模式在框架中应用广泛
抽象类中有一些方法用final来修饰,这些方法即为模板方法
迭代器(Iterator)
将集合类的迭代操作委托给迭代器来实现。
让自己的集合类实现 Iterable 接口,并实现自己的独特 Iterator 迭代器 (hasNext, next, remove) ,允许客户端利用这个迭代器进行显式或隐式的迭代遍历:
*Visitor模式
把类中的某些功能委托给别人实现(实现功能时要反过来用到原来的类)
Visitor vs Iterator
迭代器:以遍历的方式访问集合数据而无需暴露其内部表示,将“遍历”这项功能delegate到外部的iterator对象。
Visitor:在特定ADT上执行某种特定操作,但该操作不在ADT内部实现,而是delegate到独立的visitor对象,客户端可灵活扩展/改变visitor的操作算法,而不影响ADT
迭代器和Vistor模式结构相同,只是方法不同(本质上无区别)
Strategy vs visitor
自己的独特 Iterator 迭代器 (hasNext, next, remove) ,允许客户端利用这个迭代器进行显式或隐式的迭代遍历















 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









