






国家标准全文公开系统 为什么保存不了
一、显示原理
我尽量说详细一点,我真的很佩服这个开发的想法,很巧妙的用了很多办法展示,且阻止打印,真的很伟大。
这个文档16页,每一页对应一个div展示
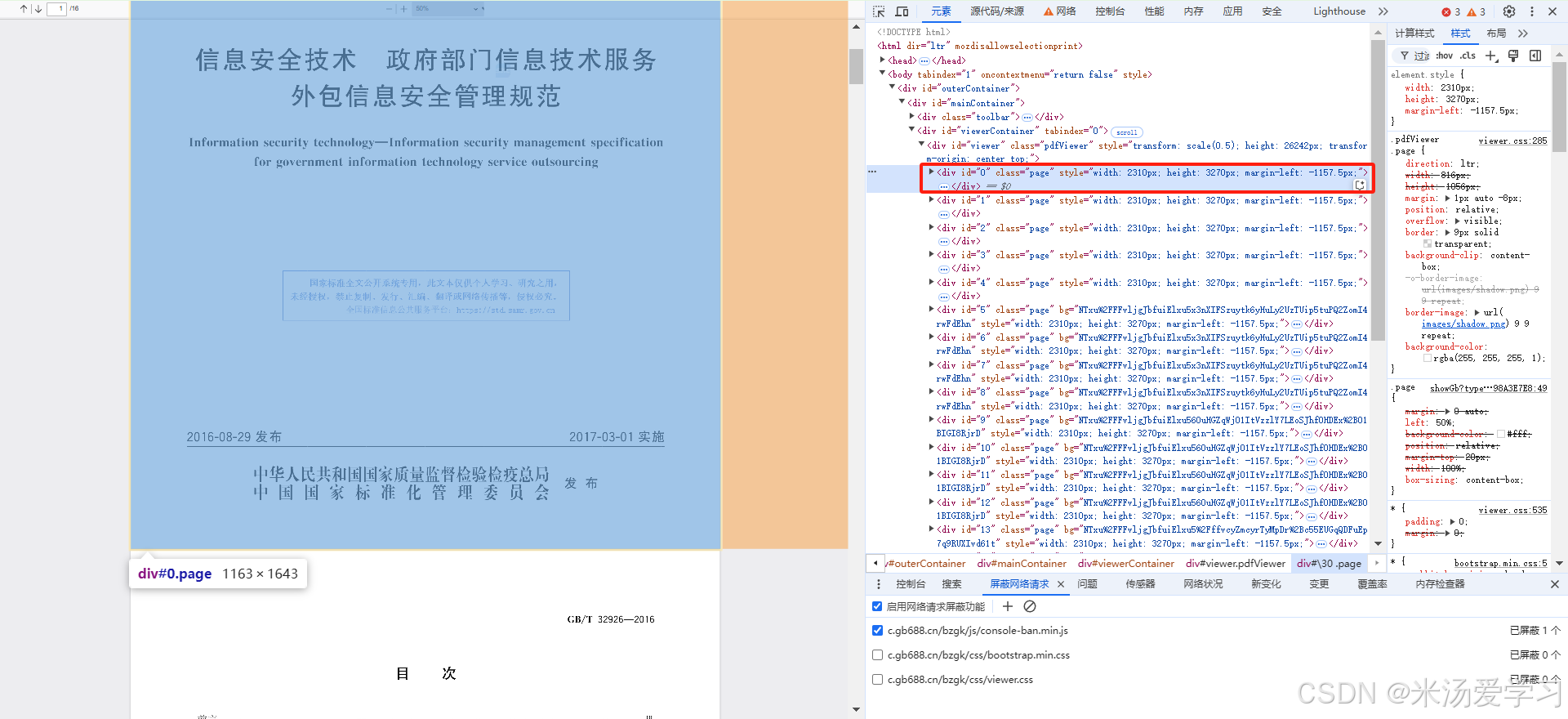
每个页面都是很多小方块(span)组成,其中有个样式,也就是说,这是一个巨大的图片,没有一个文字,全是像素!
background-position:控制背景图像在元素内的定位。决定了图像相对于元素的显示位置。
background-image:指定一个背景图像。它通过 URL 引入外部图像来设置背景
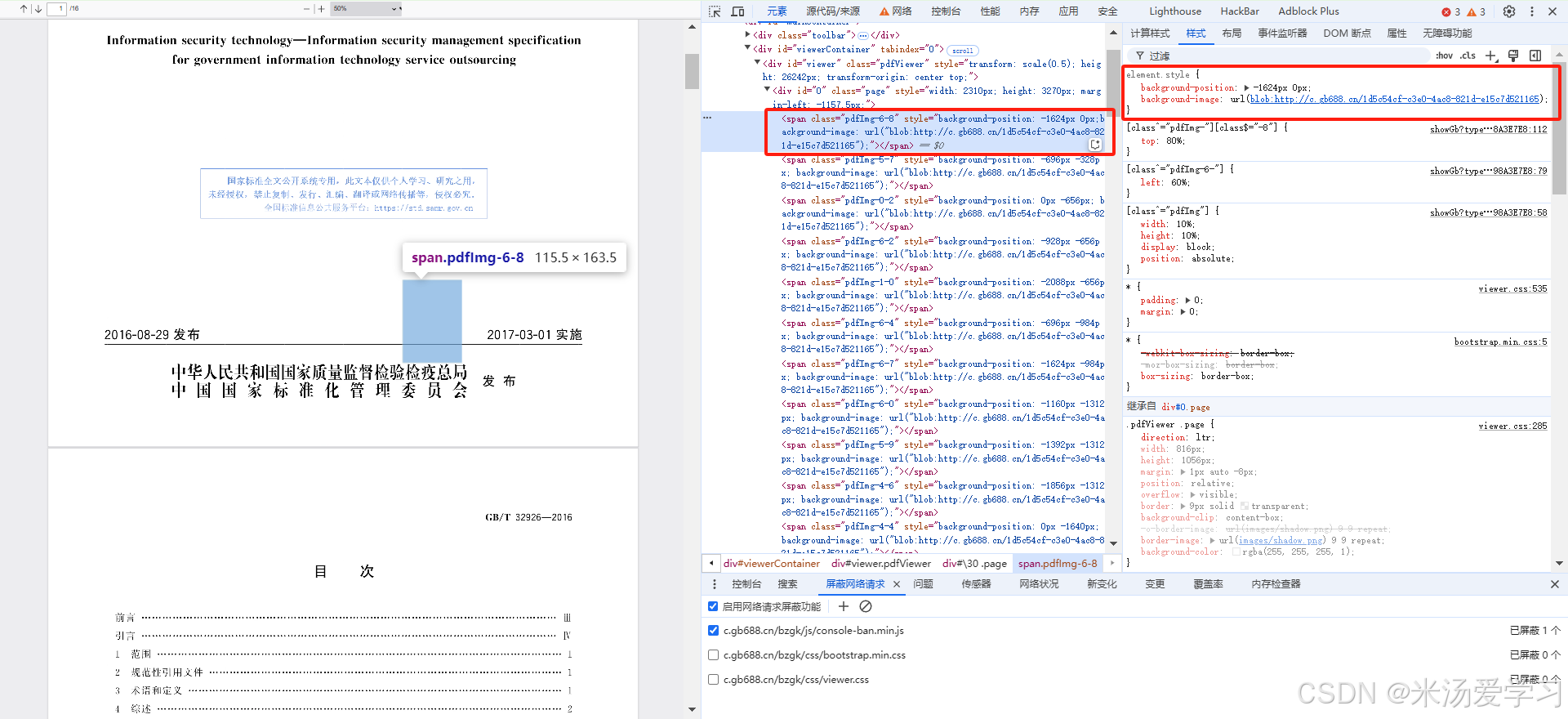
后面好奇为什么要拼接成一个页面,直接显示不好吗为什么要切块,我打开背景图片看看,我嘞个豆啊,明白了为什么要切块
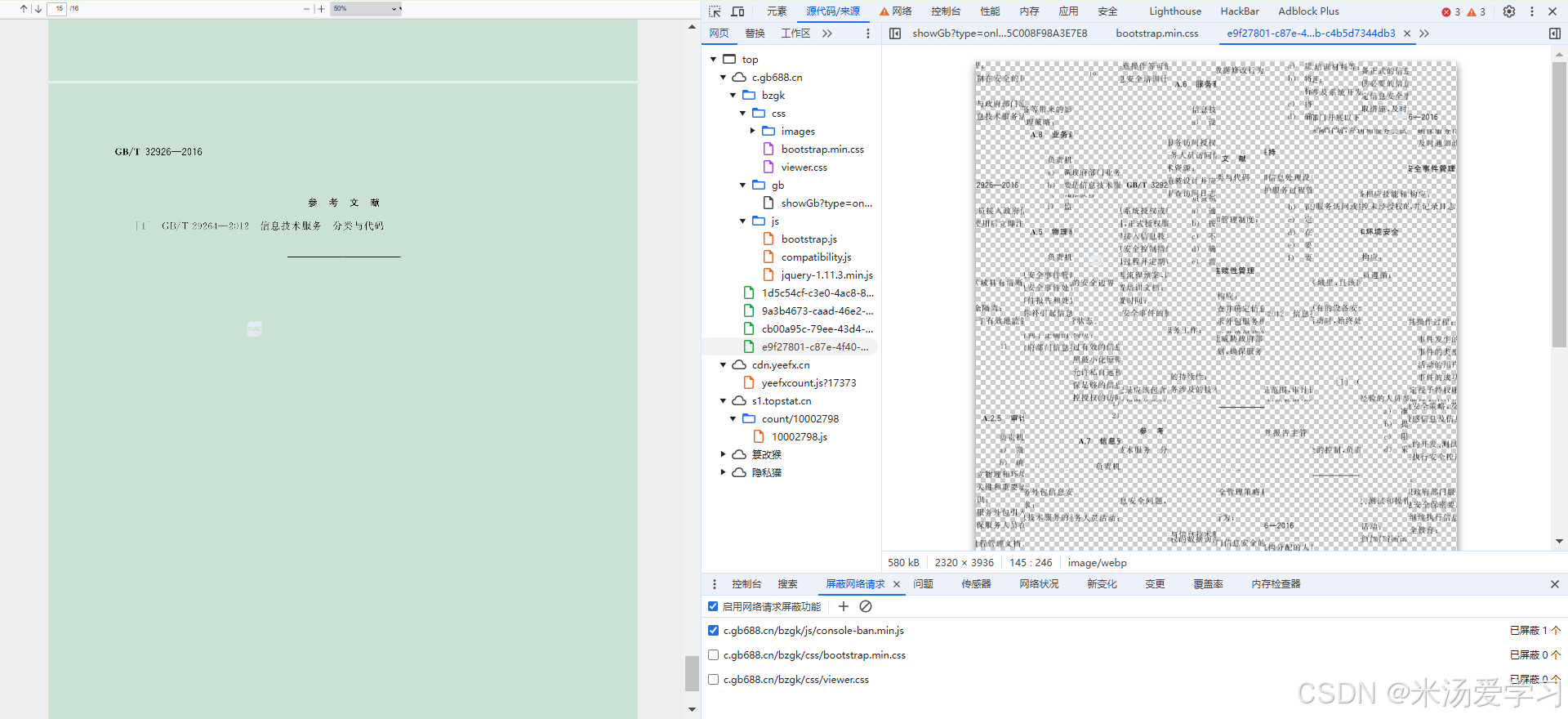
对比发现,有些页面span高达70个,有些低质10个,为什么呢,页面不都是一样大小,分析后发现,只有显示的地方才有span,才有数据,空白的地方都是空白背景,烤出来后我把背景改成红色,如下下图
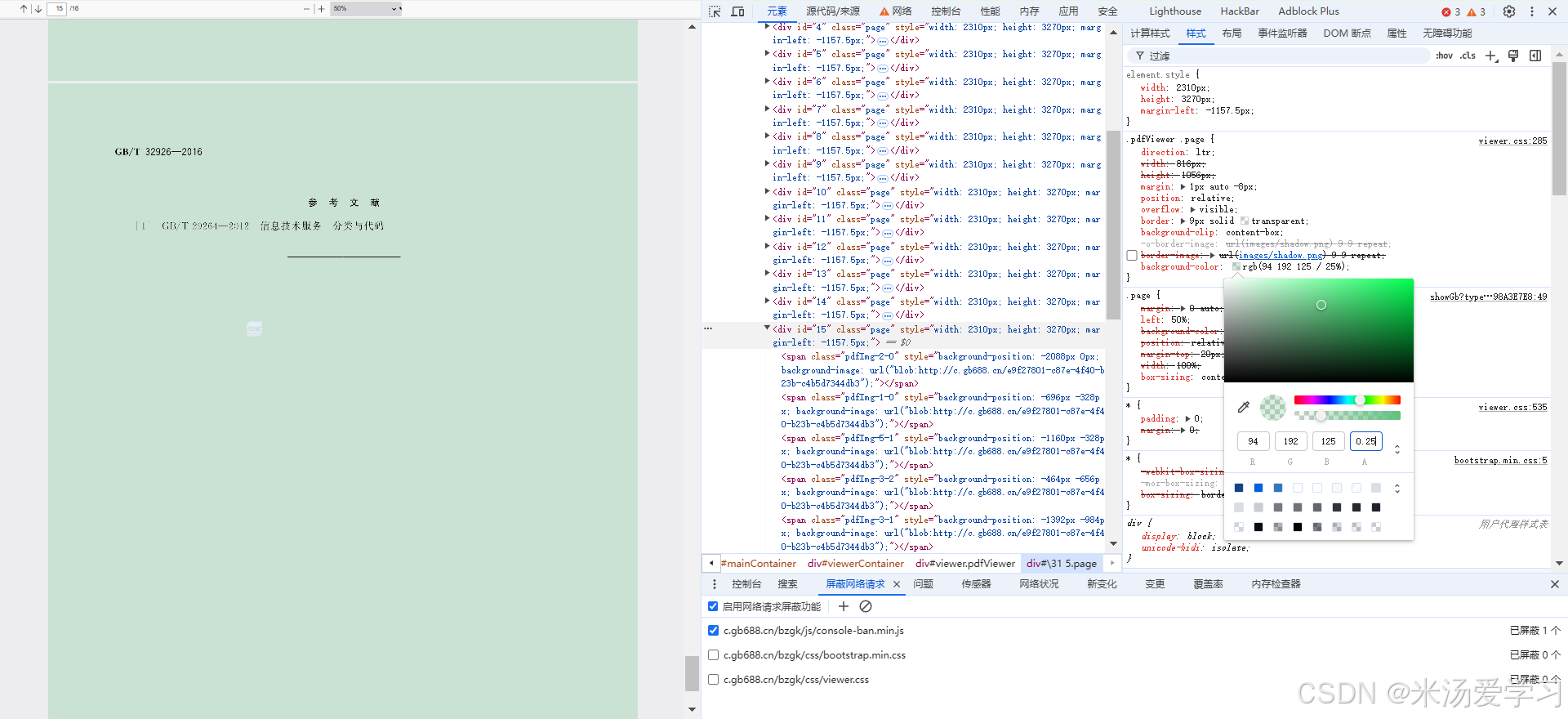
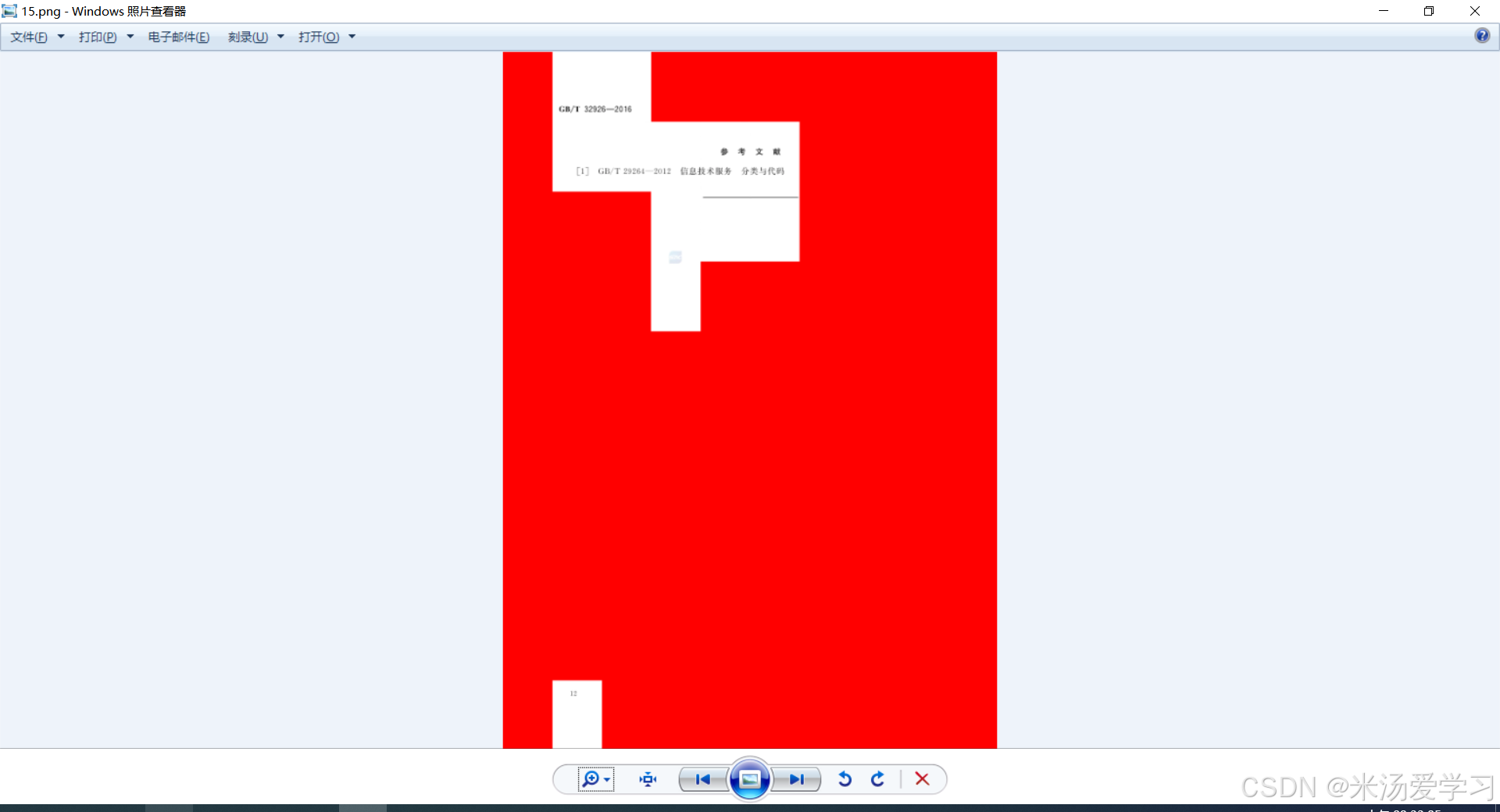
现在我们知道了大概原理,每一个页面分成了很多span元素块
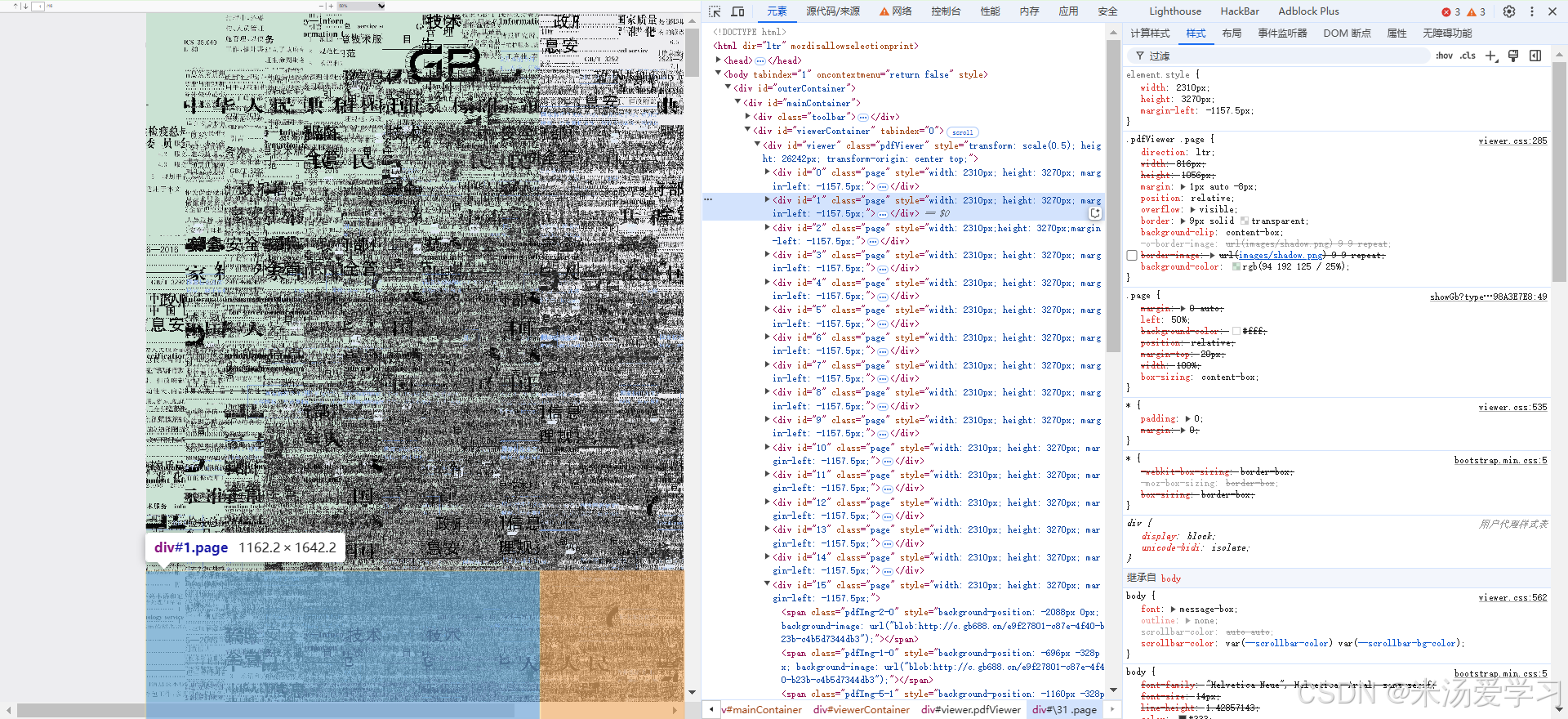
span元素先限制展示大小,然后图片定位显示,相当于整个图片都显示在页面上,只给你看了一部分,但全部加载了,下面图片是去除展示显示,全部显示,知道多牛了吧
这样你要保存成pdf,就得开背景图形,多的页面70多个span,相当于你要重复加载70多次,相当于叠了70层,同一张图片然后合成,大约(0.7秒/张),那不得等疯了
二、保存PDF
1、打开调试(方便后续操作)
2、修改css(去除限制打印)
3、修改overflow(去除一页限制)
三、流量分析
1、图片来源
2、fileName来源
3、验证码地址
4、验证码提交
四、代码爬取(python)
1、用户输入
首先,要求输入一个编号(hcno),这是该标准或文件的标识。
2、设置请求的头部和Cookie
代码设置了请求头和Cookie,这些是为了模拟浏览器访问,并绕过一些反爬虫机制。
3、验证码处理
程序首先发送一个请求,获取一个验证码的图片(通常用于防止机器人访问)。这个验证码需要通过OCR(光学字符识别)技术来识别。
图片被编码为Base64格式并发送给一个验证码识别服务【自己云部署的】,通过该服务获取验证码的识别结果。
如果验证码识别成功,程序继续执行;如果失败,则会退出,一直重复到成功。
4、页面内容的解析
使用 BeautifulSoup 解析从目标网站获取的HTML内容。
该网站包含多个页面,其中每一页可能包含图像或其他资源。通过分析HTML,程序找到每一页的图像URL。
5、下载图像
从目标网站下载每一页的图片,并将这些图像保存为WebP格式文件(这是一种图像压缩格式)。
6、图像处理
处理每张下载的图片,使用PIL库将图像裁剪和拼接到一个画布上。图像裁剪的区域根据网页中的样式信息进行计算。
每一页的图像会被保存为一个PNG格式的图片文件。
7、生成PDF
通过 FPDF 库,将之前处理过的PNG图片转换为PDF文件。每张图片会根据其纵横比自动调整大小,以适应A4纸张大小(210mm宽,297mm高)。
最终生成一个包含所有图像的PDF文件。
8、保存PDF
PDF文件的命名基于当前的时间戳,并将其保存到本地。
代码太丑了,就不公布了。
五、参考文献
1.吾爱(1699809)
https://www.52pojie.cn/thread-1699809-1-1.html



















 9512
9512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











