






前言
最近在排查公司Hadoop集群性能问题时,发现Hadoop集群整体处理速度非常缓慢,平时只需要跑几十分钟的任务时间一下子上张到了个把小时,起初怀疑是网络原因,后来证明的确是有一部分这块的原因,但是过了没几天,问题又重现了,这次就比较难定位问题了,后来分析hdfs请求日志和Ganglia的各项监控指标,发现namenode的挤压请求数持续比较大,说明namenode处理速度异常,然后进而分析出是因为写journalnode的editlog速度慢问题导致的,后来发现的确是journalnode的问题引起的,后来的原因是因为journalnode的editlog目录没创建,导致某台节点写edillog一直抛FileNotFoundException,所以在这里提醒大家一定要重视一些小角色,比如JournalNode.在问题排查期间,也对YARN的JournalNode相关部分的代码做了学习,下面是一下学习心得,可能有些地方分析有误,敬请谅解.
JournalNode
可能有些同学没有听说过JournalNode,只听过Hadoop的Datanode,Namenode,因为这个概念是在MR2也就是Yarn中新加的,journalNode的作用是存放EditLog的,在MR1中editlog是和fsimage存放在一起的然后SecondNamenode做定期合并,Yarn在这上面就不用SecondNamanode了.下面是目前的Yarn的架构图,重点关注一下JournalNode的角色.
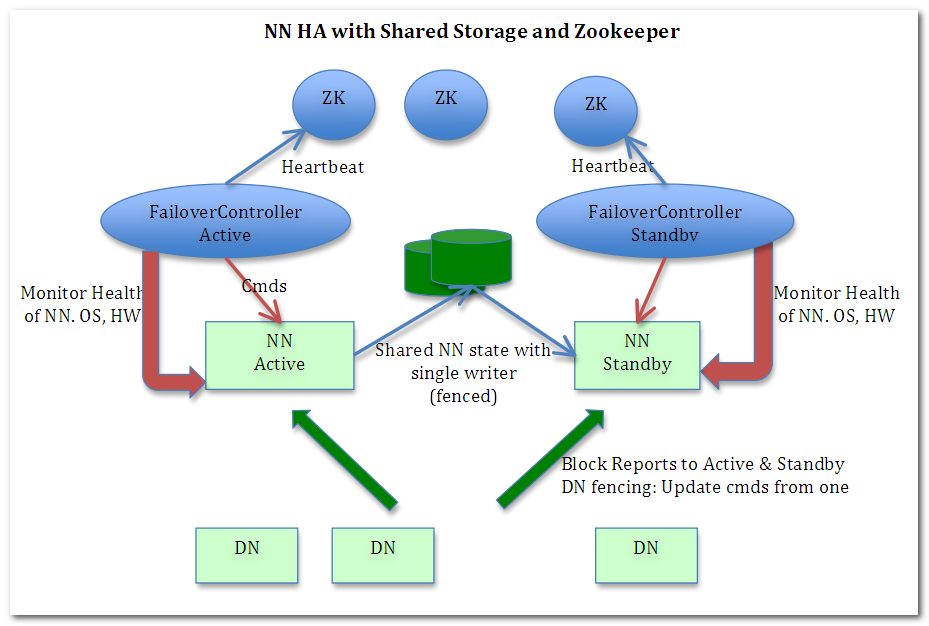
上面在Active Namenode与StandBy Namenode之间的绿色区域就是JournalNode,当然数量不一定只有1个,作用相当于NFS共享文件系统.Active Namenode往里写editlog数据,StandBy再从里面读取数据进行同步.
NameNode之间共享数据(NFS 、Quorum Journal Node(用得多))
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
Hadoop中的NameNode好比是人的心脏,非常重要,绝对不可以停止工作。在hadoop1时代,只有一个NameNode。如果该NameNode数据丢失或者不能工作,那么整个集群就不能恢复了。这是hadoop1中的单点问题,也是hadoop1不可靠的表现,如图1所示。hadoop2就解决了这个问题。

图1
hadoop2.2.0(HA)中HDFS的高可靠指的是可以同时启动2个NameNode。其中一个处于工作状态,另一个处于随时待命状态。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,手工或者自动切换到另一个NameNode提供服务。
这些NameNode之间通过共享数据,保证数据的状态一致。多个NameNode之间共享数据,可以通过Nnetwork File System或者Quorum Journal Node。前者是通过linux共享的文件系统,属于操作系统的配置;后者是hadoop自身的东西,属于软件的配置。
我们这里讲述使用Quorum Journal Node的配置方式,方式是手工切换。
集群启动时,可以同时启动2个NameNode。这些NameNode只有一个是active的,另一个属于standby状态。active状态意味着提供服务,standby状态意味着处于休眠状态,只进行数据同步,时刻准备着提供服务,如图2所示。

图2
架构
在一个典型的HA集群中,每个NameNode是一台独立的服务器。在任一时刻,只有一个NameNode处于active状态,另一个处于standby状态。其中,active状态的NameNode负责所有的客户端操作,standby状态的NameNode处于从属地位,维护着数据状态,随时准备切换。
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了,如图3所示。

图3
为了确保快速切换,standby状态的NameNode有必要知道集群中所有数据块的位置。为了做到这点,所有的datanodes必须配置两个NameNode的地址,发送数据块位置信息和心跳给他们两个。
对于HA集群而言,确保同一时刻只有一个NameNode处于active状态是至关重要的。否则,两个NameNode的数据状态就会产生分歧,可能丢失数据,或者产生错误的结果。为了保证这点,JNs必须确保同一时刻只有一个NameNode可以向自己写数据。
硬件资源
为了部署HA集群,应该准备以下事情:
* NameNode服务器:运行NameNode的服务器应该有相同的硬件配置。
* JournalNode服务器:运行的JournalNode进程非常轻量,可以部署在其他的服务器上。注意:必须允许至少3个节点。当然可以运行更多,但是必须是奇数个,如3、5、7、9个等等。当运行N个节点时,系统可以容忍至少(N-1)/2(N至少为3)个节点失败而不影响正常运行。
在HA集群中,standby状态的NameNode可以完成checkpoint操作,因此没必要配置Secondary NameNode、CheckpointNode、BackupNode。如果真的配置了,还会报错。

















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









