








垃圾收集阶段对于任何 Java 应用程序都至关重要。主要目标是保持高吞吐量和低延迟之间的平衡。通过配置垃圾收集器,我们可以提高性能,或者至少推动应用程序朝着特定的方向发展。
垃圾收集周期越短越好。因此,分配给垃圾收集器的资源越多,它的工作速度就越快,从而整体上改善我们的应用程序。为垃圾收集器分配更多资源是一个合理的想法,但它并不像听起来那么简单。
在本文中,我们将了解线程数对应用程序性能的影响。本文主要介绍直接在主机上运行的应用程序。**但是,我们也可以将这些见解应用于容器化应用程序。 **
垃圾收集线程
通常,垃圾收集器会使用多个线程来促进正确及时的收集过程。然而,我们通常对与之连接的两种类型的线程感兴趣:并行线程和并发线程。
请注意,某些算法可能会出于不同目的使用更多线程。 例如,G1 垃圾收集器会使用更多线程执行某些内部任务。
1.并发线程
这些线程的名称是不言而喻的。 垃圾收集器在并发阶段使用并发线程。 例如,CMS 将使用它们来清理旧代。提供更多线程有助于减少应用程序的延迟。
同时,完全 STW(stop-the-world)垃圾收集器不会使用它们,因为它们没有并发阶段。
2. 并行线程
这些线程在 STW 阶段发挥作用。 尽管名称如此,但它们并不与应用程序并行运行。这些线程将彼此并行运行,以减少垃圾收集暂停。
因此,更多的并行线程会减少 STW 时间。但是,我们需要验证所有假设并运行适当的基准测试。JVM使用合理的启发式方法根据 CPU 核心数来确定默认的垃圾收集线程数。这个想法很简单:更多核心等于更多线程:
在具有 N 个硬件线程且 N 大于 8 的机器上,并行收集器使用 N 的固定分数作为垃圾收集器线程数。对于较大的 N 值,该分数约为 5/8。当 N 值低于 8 时,使用的数字为 N。在选定的平台上,该分数下降到 5/16。
因此,在八核机器上,我们将有八个收集器线程;在三十二核的机器上,这个数字将是二十个。
手动配置
虽然 JVM 提供了有关默认线程数的合理启发式方法,但有时我们想要覆盖它们。 我们可以使用 VM 选项手动配置线程数。 显式配置可以更好地控制应用程序,并允许我们使用更合适的值覆盖默认值。
我们可以使用几个标志来配置线程数。正如我们所讨论的,垃圾收集过程通常使用两种类型的线程:并发和并行;我们有单独的参数来控制它们:
-XX:ParallelGCThreads=<number>
-XX:ConcGCThreads=<threads>
手动配置的主要问题是我们应该深刻理解我们的应用程序: 不完全是领域逻辑和类之间的联系,而是影响堆的资源消耗和进程。
我们还必须了解 JVM 和应用程序使用的垃圾收集算法。理解不当可能会导致性能下降。**同时,向 SerialGC 添加更多并发线程不会对其产生任何影响。 **
线程数
让我们使用一个简单的应用程序来检查垃圾收集线程。但是,我们不会在空闲应用程序上看到所有线程。因此,我们需要对垃圾收集器施加压力,以便它尝试利用所有资源:
public class GcThreadsOnOutOfMemoryErrorBenchmark {
public static void main(String[] args) {
LinkedList<String> strings = new LinkedList<>();
while (true) {
strings.add(new String("Hello World!!!!"));
}
}
}
此代码将导致OutOfMemoryError并使应用程序崩溃。但是,这正是我们强制它使用所有可用的垃圾收集线程所需要的。要在**OutOfMemoryError时创建线程转储,我们可以使用以下命令:
-XX:OnOutOfMemoryError= "kill -3 %p"
我们把并发线程数改为2个,并行线程数改为8个,可以使用*-XX:+PrintCommandLineFlags*来验证一下参数:
-XX:ConcGCThreads=2 -XX:G1ConcRefinementThreads=8 -XX:GCDrainStackTargetSize=64 -XX:InitialHeapSize=268435456 -XX:MarkStackSize=4194304 -XX:MaxHeapSize=268435456 -XX:MinHeapSize=6815736 -XX:OnOutOfMemoryError=kill -3 %p -XX:ParallelGCThreads=8 -XX:+PrintCommandLineFlags -XX:ReservedCodeCacheSize=251658240 -XX:+SegmentedCodeCache -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseG1GC
根据之前的 VM 标志列表,我们将使用 G1GC 来查看并发和并行线程。 此外,我们还可以看到特定于此算法的其他垃圾收集线程:
Threads class SMR info:
_java_thread_list=0x0000600002d0ae80, length=12, elements={
0x0000000142016c00, 0x000000014380dc00, 0x000000014380b800, 0x00000001420d1600,
0x00000001420cf600, 0x000000014180b000, 0x00000001420d3400, 0x00000001420d6800,
0x000000014180d800, 0x0000000143009800, 0x0000000141812a00, 0x0000000141813000
}
"main" #1 [8451] prio=5 os_prio=31 cpu=68.74ms elapsed=1.41s tid=0x0000000142016c00 nid=8451 runnable [0x000000016d7d6000]
java.lang.Thread.State: RUNNABLE
"Reference Handler" #8 [31747] daemon prio=10 os_prio=31 cpu=0.43ms elapsed=1.40s tid=0x000000014380dc00 nid=31747 runnable [0x000000016e742000]
java.lang.Thread.State: RUNNABLE
"Finalizer" #9 [22531] daemon prio=8 os_prio=31 cpu=0.14ms elapsed=1.40s tid=0x000000014380b800 nid=22531 in Object.wait() [0x000000016e94e000]
java.lang.Thread.State: WAITING (on object monitor)
"Signal Dispatcher" #10 [31235] daemon prio=9 os_prio=31 cpu=0.07ms elapsed=1.40s tid=0x00000001420d1600 nid=31235 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Service Thread" #11 [23043] daemon prio=9 os_prio=31 cpu=0.15ms elapsed=1.40s tid=0x00000001420cf600 nid=23043 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Monitor Deflation Thread" #12 [30723] daemon prio=9 os_prio=31 cpu=0.03ms elapsed=1.40s tid=0x000000014180b000 nid=30723 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"C2 CompilerThread0" #13 [23555] daemon prio=9 os_prio=31 cpu=18.32ms elapsed=1.40s tid=0x00000001420d3400 nid=23555 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
No compile task
"C1 CompilerThread0" #16 [24067] daemon prio=9 os_prio=31 cpu=18.20ms elapsed=1.40s tid=0x00000001420d6800 nid=24067 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
No compile task
"Sweeper thread" #17 [30211] daemon prio=9 os_prio=31 cpu=0.04ms elapsed=1.40s tid=0x000000014180d800 nid=30211 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Common-Cleaner" #18 [29699] daemon prio=8 os_prio=31 cpu=0.20ms elapsed=1.40s tid=0x0000000143009800 nid=29699 waiting on condition [0x000000016f7a2000]
java.lang.Thread.State: TIMED_WAITING (parking)
"Monitor Ctrl-Break" #19 [24835] daemon prio=5 os_prio=31 cpu=14.32ms elapsed=1.37s tid=0x0000000141812a00 nid=24835 runnable [0x000000016f9ae000]
java.lang.Thread.State: RUNNABLE
"Notification Thread" #20 [25347] daemon prio=9 os_prio=31 cpu=0.04ms elapsed=1.37s tid=0x0000000141813000 nid=25347 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"VM Thread" os_prio=31 cpu=16.53ms elapsed=1.41s tid=0x000000014170e060 nid=19971 runnable
"GC Thread#0" os_prio=31 cpu=619.54ms elapsed=1.41s tid=0x0000000141706da0 nid=12547 runnable
"GC Thread#1" os_prio=31 cpu=672.72ms elapsed=1.36s tid=0x000000014161b6d0 nid=28931 runnable
"GC Thread#2" os_prio=31 cpu=559.43ms elapsed=1.36s tid=0x000000014161bb70 nid=25859 runnable
"GC Thread#3" os_prio=31 cpu=914.80ms elapsed=1.36s tid=0x000000014161c010 nid=26115 runnable
"GC Thread#4" os_prio=31 cpu=613.24ms elapsed=1.36s tid=0x000000014161c4b0 nid=28163 runnable
"GC Thread#5" os_prio=31 cpu=491.98ms elapsed=1.36s tid=0x000000014161c950 nid=27907 runnable
"GC Thread#6" os_prio=31 cpu=844.52ms elapsed=1.36s tid=0x000000014161cdf0 nid=27395 runnable
"GC Thread#7" os_prio=31 cpu=662.01ms elapsed=1.36s tid=0x000000014161d290 nid=27139 runnable
"G1 Main Marker" os_prio=31 cpu=0.13ms elapsed=1.41s tid=0x0000000141707470 nid=14339 runnable
"G1 Conc#0" os_prio=31 cpu=17.27ms elapsed=1.41s tid=0x0000000141707d10 nid=13827 runnable
"G1 Conc#1" os_prio=31 cpu=17.35ms elapsed=1.09s tid=0x000000014161dc30 nid=43267 runnable
"G1 Refine#0" os_prio=31 cpu=1.00ms elapsed=1.41s tid=0x0000000141709ba0 nid=16643 runnable
"G1 Service" os_prio=31 cpu=0.41ms elapsed=1.41s tid=0x000000014170a4d0 nid=21507 runnable
"VM Periodic Task Thread" os_prio=31 cpu=0.22ms elapsed=1.37s tid=0x000000014161a930 nid=25603 waiting on condition
虽然手动配置可能很有用,但也可能导致严重问题。 我们可以将自动计算与限制相结合来避免错误。 以下标志可以帮助我们自动计算线程数,但也允许我们设置一些限制:
-XX:+AdaptiveGCThreading
-XX:ParallelGCMaxThreads
线程转储分析
我们可以在应用程序中创建线程转储,因为它们不会产生太多开销。**最好多次创建线程转储,每次之间都留出短暂的停顿,例如 10 秒。 **
虽然线程转储通常可读,但更方便的是可视化和比较随时间变化的信息。 标准工具可以帮助我们可视化、过滤和搜索,但它们没有提供比较转储的便捷方法 。
yCrash 提供了一些工具,可以帮助分析和测试应用程序的性能。其中 之一是fastThread ,它可以根据线程转储创建综合报告:
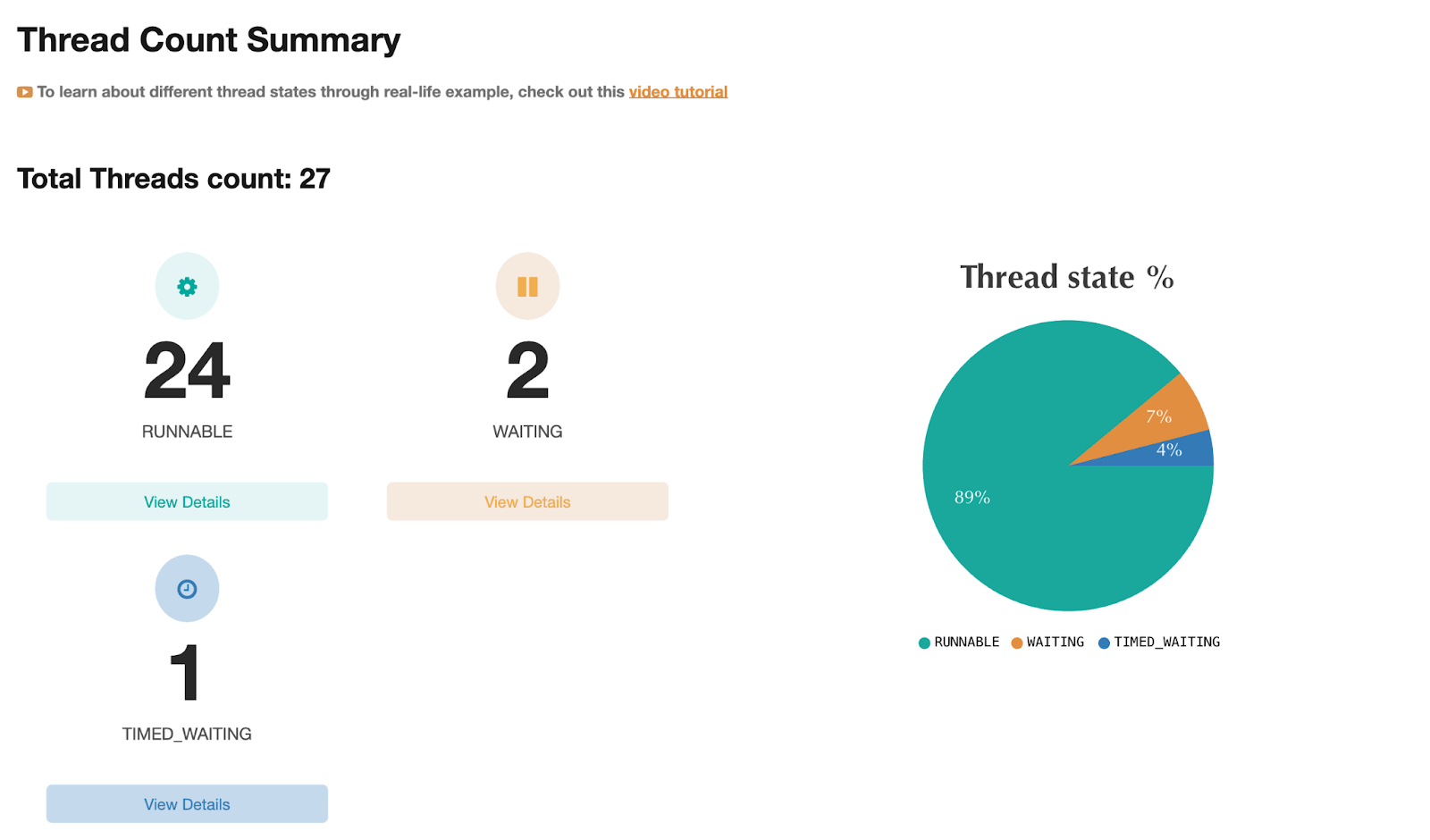
如图:快速线程报告 摘要
然后可以对这些报告进行比较和审查:

如图:快速线程比较总结
可以通过 yCrash 仪表板访问这些报告,以访问同一应用程序中的所有报告。
另外,我们可以在同一个报告页面上检查线程池:
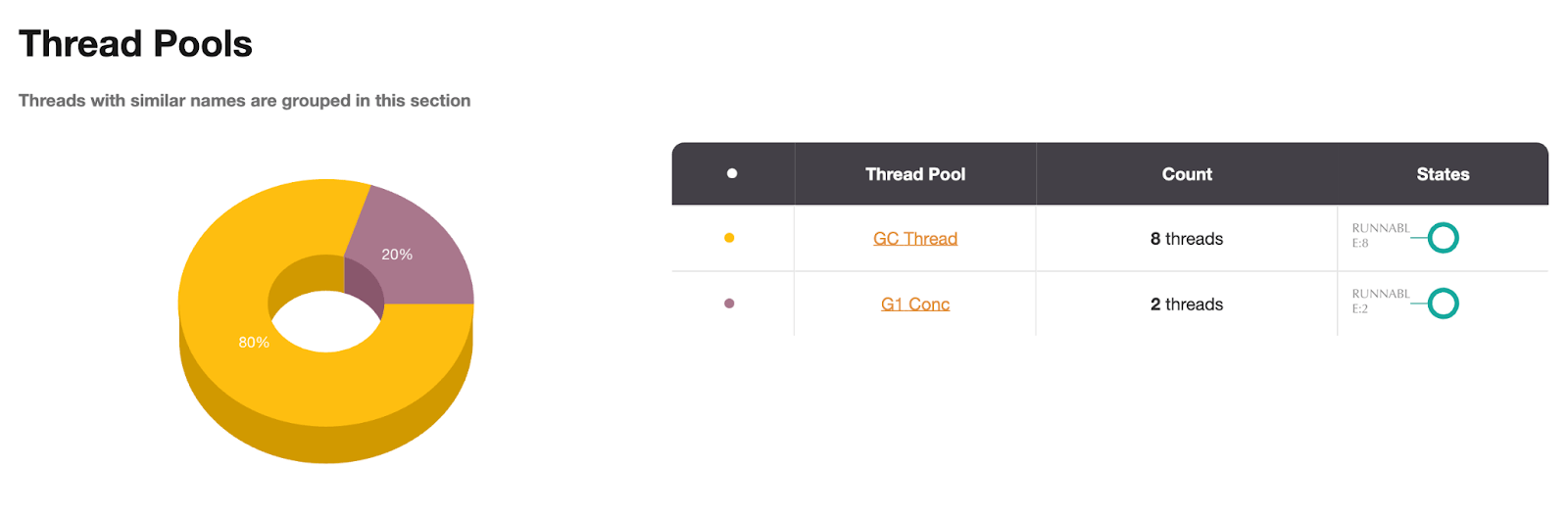
如图:快速线程线程池
结论
垃圾收集线程的默认配置通常都很好。 但是,JVM 允许手动配置,我们可以使用它来微调应用程序并提高其性能。此过程应包括监控和分析。
线程转储不会产生太多开销 ,因此我们可以定期运行它们。 这样,我们可以在不同阶段监控应用程序的变化,这有助于识别热点。
然而,为了更好地了解应用程序的问题,必须进行几次线程转储,并在每次转储之间进行短暂的暂停。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











