







个人觉得这篇笔记写的比较适合我,就转载过来了:
转载链接:http://blog.csdn.net/feliciafay/article/details/22985917
课程引入
1 Regression和Classification的区别
Regression: to predict the continuous valued output.
Classification: to predict the discrete valued output.
2 如何用ML algorithm处理有infinite number of features?
SVM会有mathematical trick to allow computer to deal with infinite number of features without exhausting the memory.
3 Cocktail Party Algorithm 问题
Microphone1 有speaker1和speaker2的声音的混合,Microphone2也有speaker1和speaker2的声音的混合,如何从中清晰地分离出speaker1和 speaker2的声音呢?可以使用ML算法。
4选什么工具
Trust Professor,在学习Machine Learning时候使用的工具是 Octave or Matlab,比Java/C++更快
5 Supervised Learning和Unsupervised Learning的区别
Supervised Learning有labeled data,但是Unsupervised Learning没有
Cost Function, 求最小值,局部最优和全局最优
1 如下图,是线性回归(假设只有两个参数)cost function的可视化图形表达,是个(bowl)碗型平面

2 关于求导数的复习
2.1关于求导法则http://wenku.baidu.com/view/ace4483131126edb6f1a10ea.html

2.2 复合函数的导数的链式法则http://zh.wikipedia.org/wiki/%E9%93%BE%E5%BC%8F%E6%B3%95%E5%88%99

2.3 乘积求导法则配合复合函数求导法则使用http://wenku.baidu.com/view/ace4483131126edb6f1a10ea.html

2.4* 二阶偏导数http://wenku.baidu.com/view/7f549e225901020207409c9d.html
2.5* 隐函数的一阶求导和二阶求导http://sxyd.sdut.edu.cn/gaoshu2/lesson/8.5yinhanshuqiudao.htm
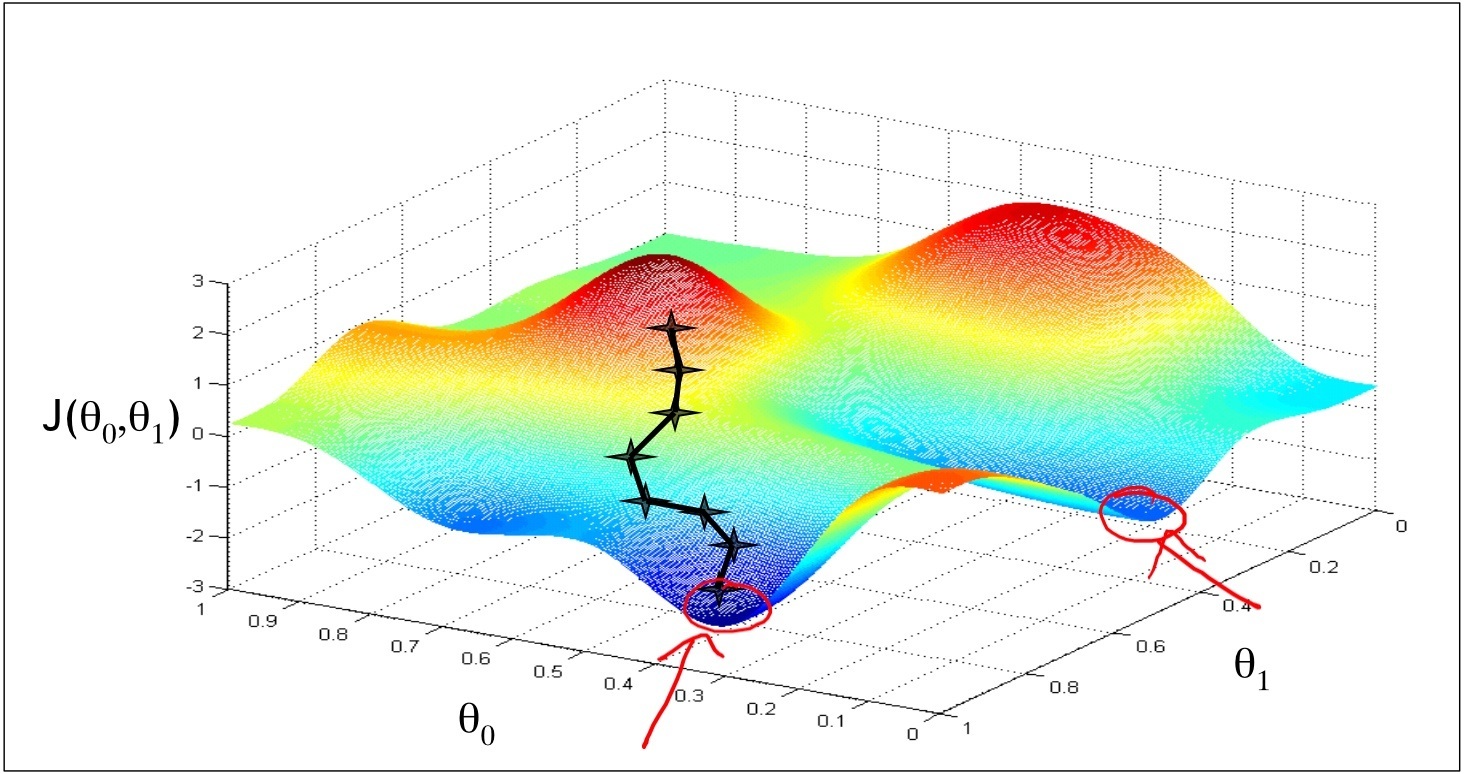
3 有没有可能gradient descent找到的是局部最优? 有可能。
Gradient Descent(梯度下降的)方法可能跳不出局部最优。 但是,对只有2个变量的线性函数的模型而言,由于cost function是一个凸函数,所以只有一个最优点,所以局部最优就是全局最优。
Contour Plot
如下,把bowl压扁了就是contour plot,每个圈圈上的点都有相同的J(θ₀,θ₁)取值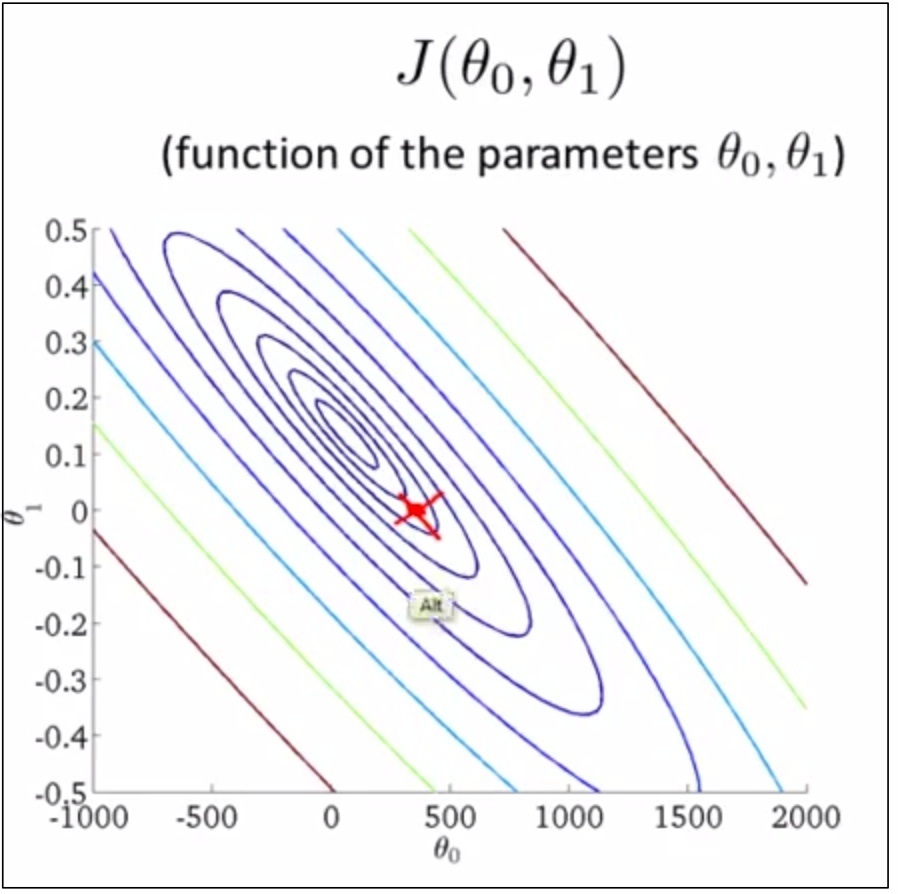

如上面2图,θ0减去α*偏导数的目的是为了使得θ,向着bowl平面的最低点聚拢,也就是向着二次函数的中间点聚拢。
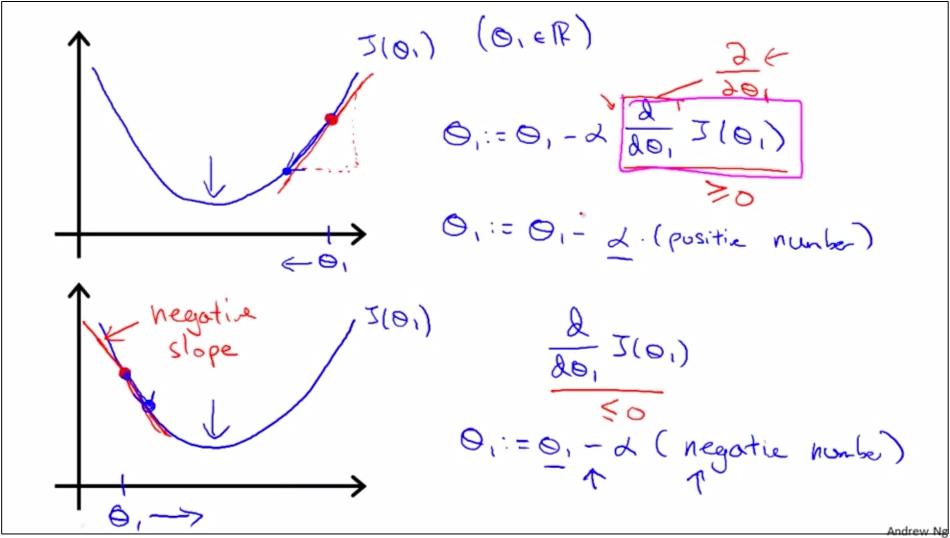
如上图,是公式的含义,Gradient Descent的工作机制是,as we approach a local minimum, Learning rate α will automatically take smaller steps, thus no need to decrease α over time.
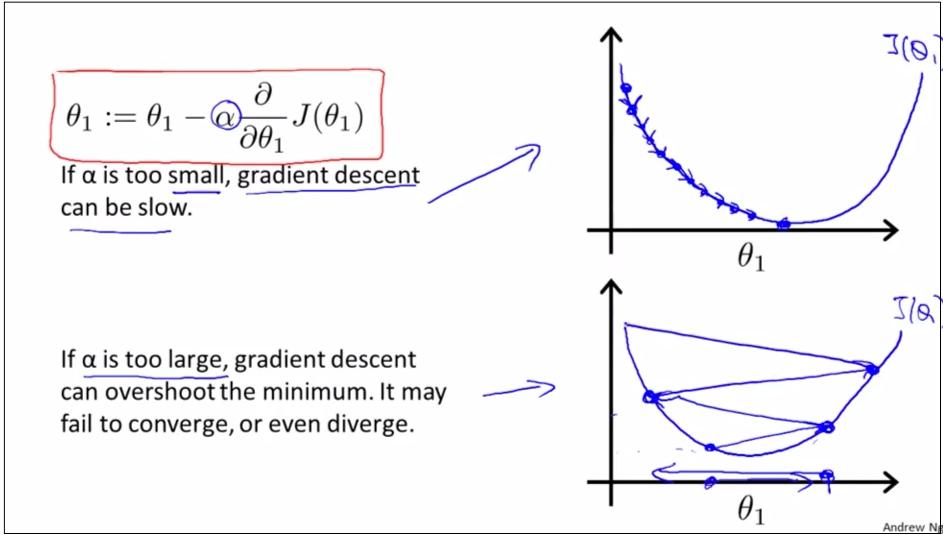
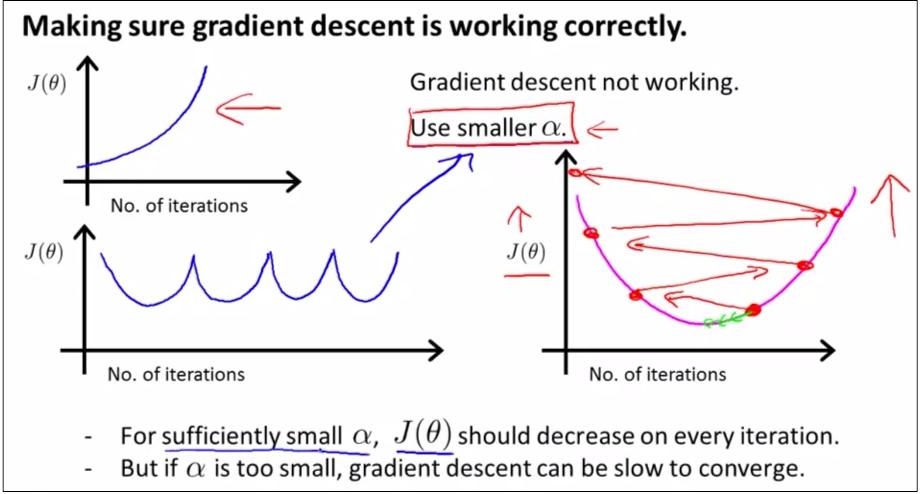
如上图,如果learning rate α过大过小会怎样?
Linear Regression with Multiple Variables
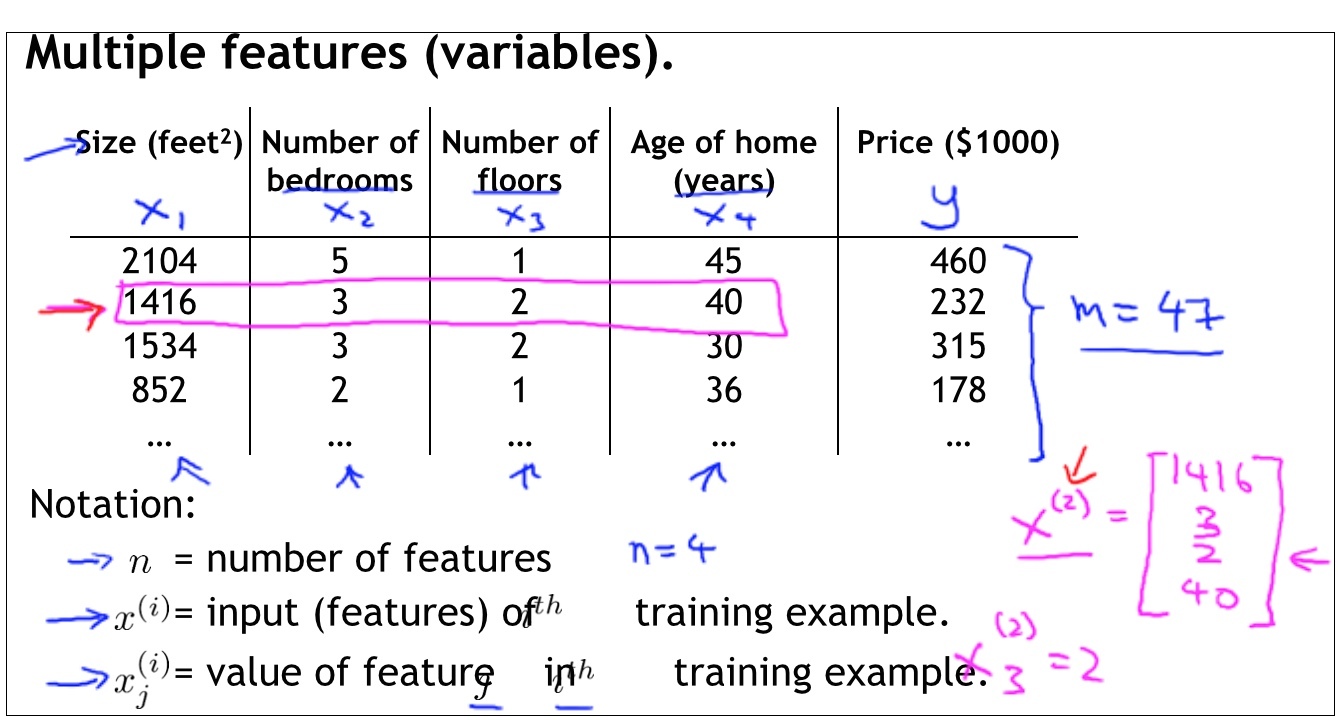
如上图,各种变量的含义

如上图,说明了在多变量的情况下,如何在每步使用Gradient Descent对进行更新。
Feature Scaling make sure that features are on a similar scale

如上图,做Feature Scaling的好处是,可以尽可能低使得contour长得像个circle,所以gradient descent在找寻global minimun的过程中就会有更加直接的路径(右图),而不是像左图那样。

如上图,对feature的取值做处理通常包含两件事情,1 feature scaling 2 mean normalization
Debugging and make sure that gradient descent works well
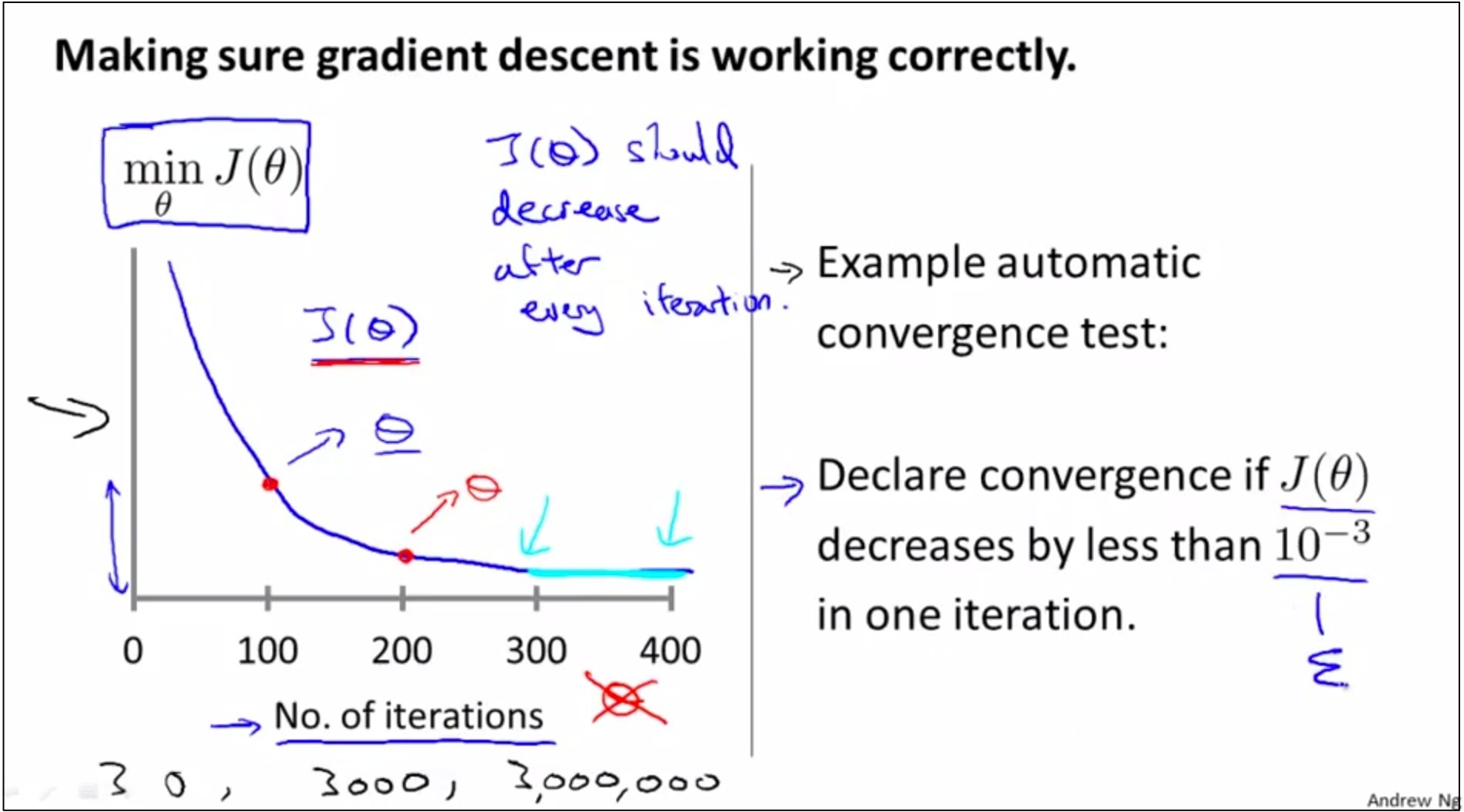
如上图,有两种办法,分别在竖线左边和竖线右边。
第一种: 作图,看看是否随着iteration的进行,min J(θ)是先减小然后逐渐flatten的趋势
第二种: automatic convergence test,难点是很难找到合适的threshold

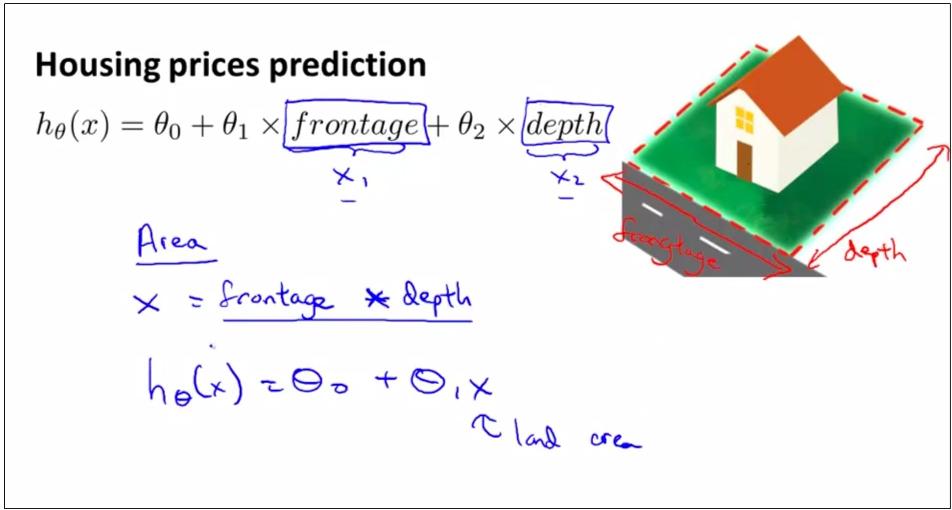
如上图,特征1“房屋的长”, 特征2“房屋的深”,从特征1和特征2可以构造一个新的特征,特征1-new “房屋的面积”。
在Polynomial Regression中应该如何选
(0)比如应该选择2次函数模型还是2次函数模型呢?
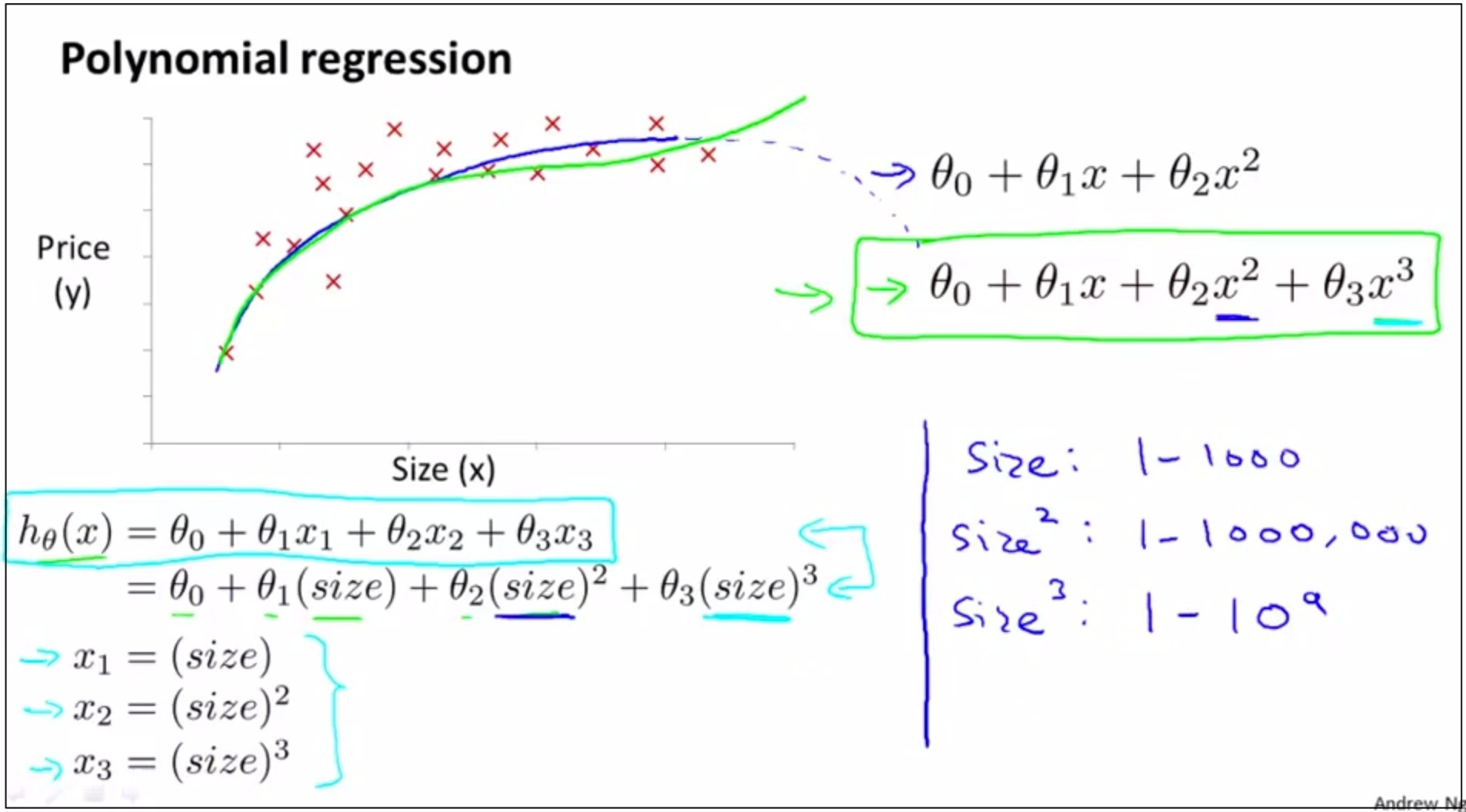
(1) 如上图,将这个问题映射为多元回归求解。
如果使用一次函数模型,将x1=house size放入多元回归求解,转化为梯度下降求解的问题。
如果使用二次函数模型,将x2=square (house size)和x1共同作为2个变量放入多元回归求解,转化为梯度下降求解的问题。
如果使用三次函数模型,将x3=cubic(house size),和x2,x1共同作为3个变量放入多元回归求解,转化为梯度下降求解的问题。

(2) 如上图,在上面的转化为多元回归求解的过程中,feature scaling 非常重要
(3) 也要结合问题的实际意义,比如根据房子的面积预测房价,就不太可能选择二次函数,因为房价只会随着面积的增加逐渐增加,不太可能随着面积的增加先增大后减小。
Normal Equation
(0)和Gradient Descent并列的一种办法,用来就求使得min J(θ)=min时的θ
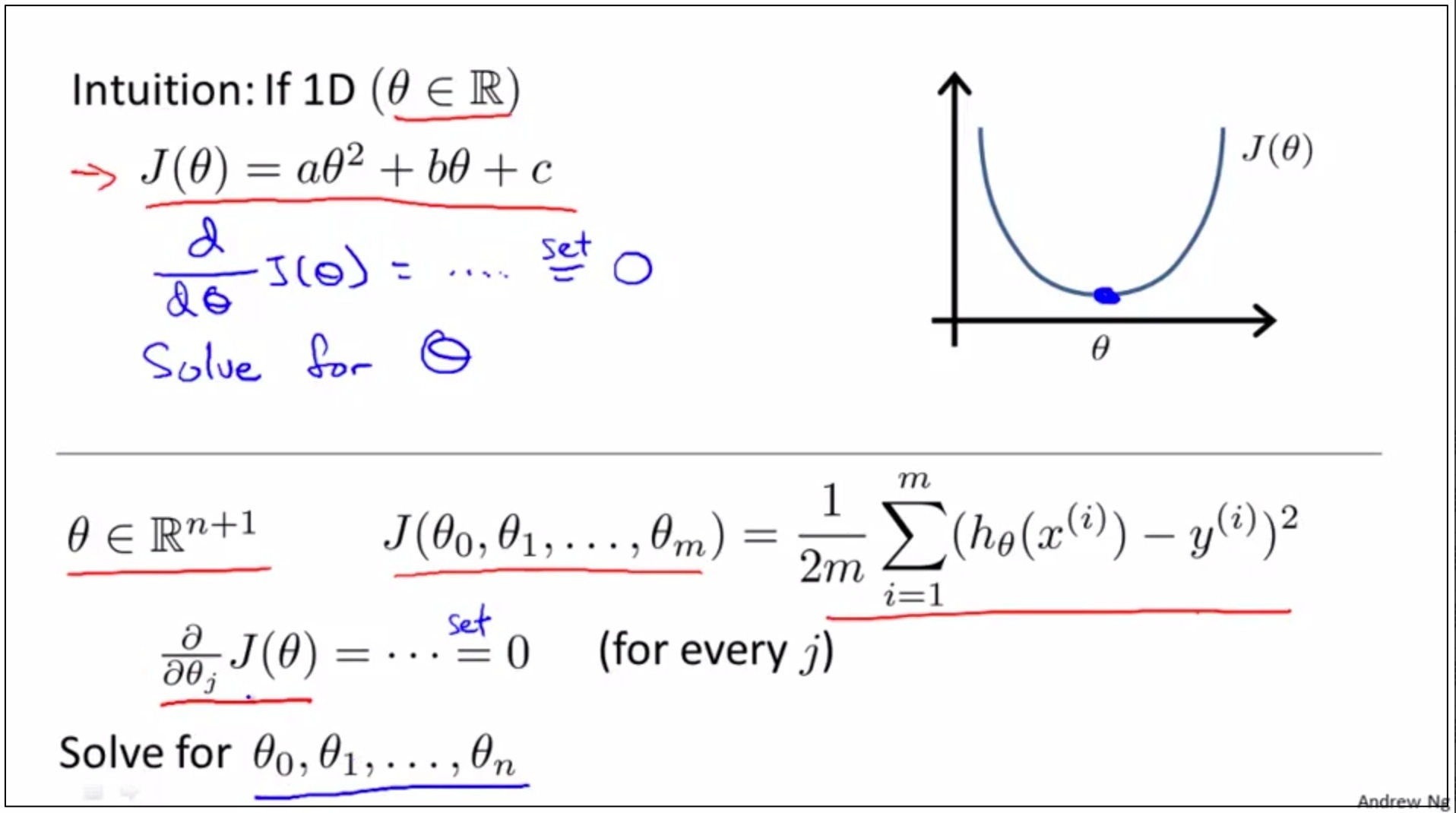
如上图,使用偏导数方法对求出极值。
step 1, take the partial derivative of J, with respect to every parameter of θ J in turn,
step 2, set all of these to 0.
step 3, solve for the values of θ₀ ,θ₁,…,up to θN
step 4, this would give you that values of θ to minimize the cost function J.

如上图,使用矩阵方法求出了θ的最优值,这里不进行数学证明。 具体步骤如下:
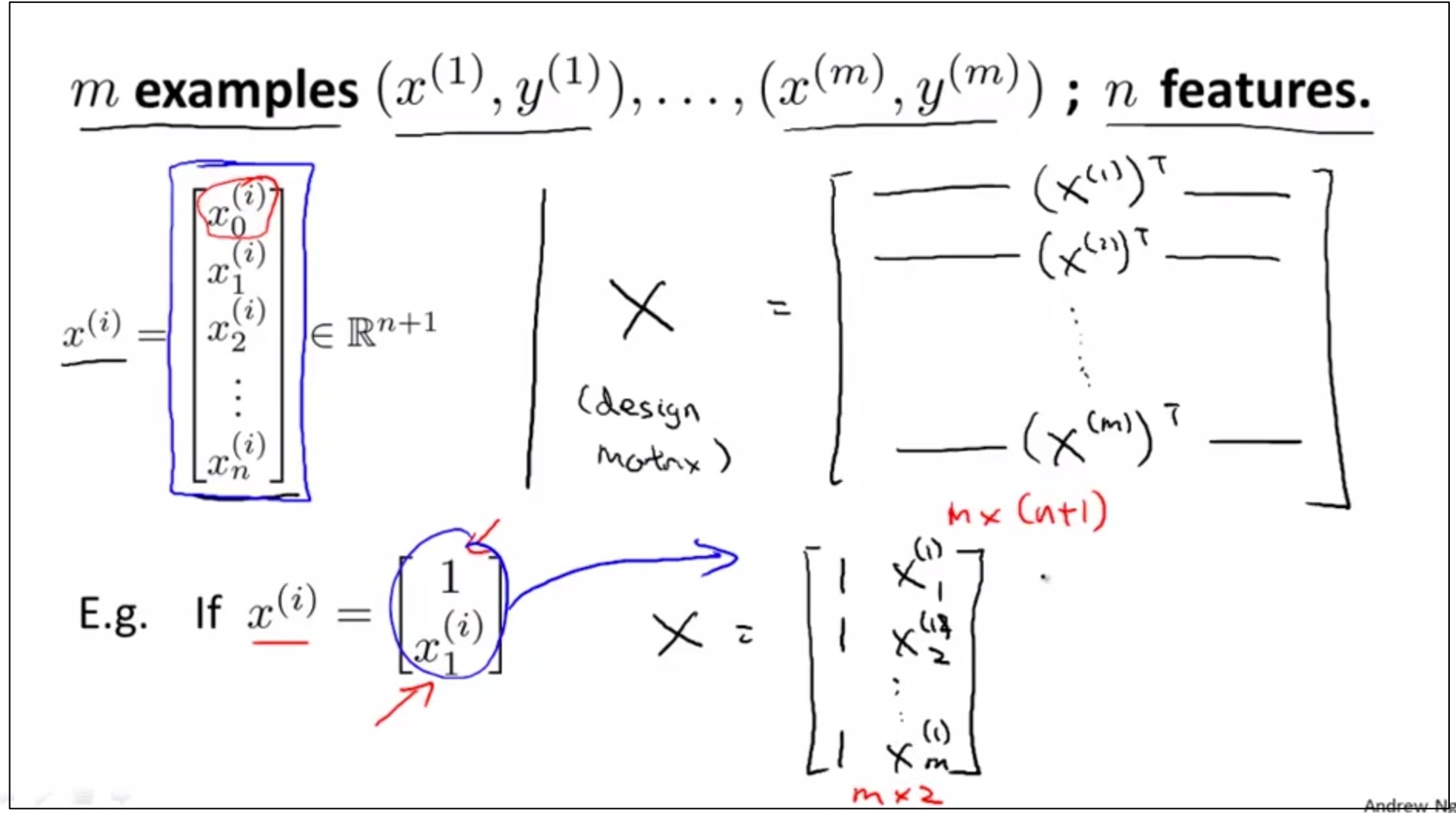
如上图,展示了矩阵算法的具体步骤
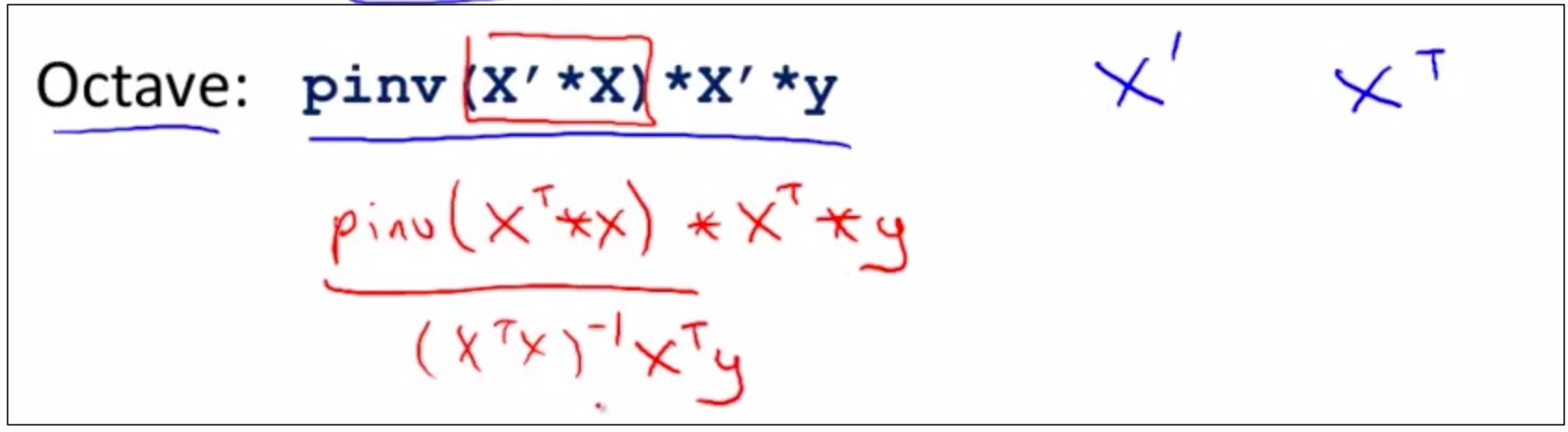
如上图,在octave中的计算如上。
另外注意1,如果使用了octave,那么feature scaling 其实并不是necessary了(why ?)
另外注意2, octave中的pinv()函数和inv()函数都可以用来计算矩阵的transpose,但是pinv()函数对于即使non-invertible的矩阵,也可以最终计算出θ
另外注意3,什么时候transpose(X)*X无法求逆? 一,有redundant features(如面积和m²,需要去掉重复),二,m<n(特征数大于样本数,需要做regulation)

Andrew说,Normal Equation对于特征数n<10000的线性回归,是很好用的。但是当非线性回归时,无法用Normal Equation,并且, 当线性回归的特征数>10000时,工程上Normal Equation 是unscalable的,时间复杂度陡然上升到不能忍的程度了















 1067
1067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









