







 Step1:读懂题目题目的意思训练集是:12个月–>每月的前20天–>每天的24小时–>每小时的18种不同属性的数值测试集:240天–>连续的9小时–>18种不同的属性要求的输出:根据某天连续的9小时–>18种不同的属性,预测第10小时的PM2.5的值。也就是通过一个18*9的矩阵预测出来一个值Step2:数据预处理# 读取数据csv文件,将csv数据保存为矩阵data = pd.read_csv('./train.csv', encoding='bi
Step1:读懂题目题目的意思训练集是:12个月–>每月的前20天–>每天的24小时–>每小时的18种不同属性的数值测试集:240天–>连续的9小时–>18种不同的属性要求的输出:根据某天连续的9小时–>18种不同的属性,预测第10小时的PM2.5的值。也就是通过一个18*9的矩阵预测出来一个值Step2:数据预处理# 读取数据csv文件,将csv数据保存为矩阵data = pd.read_csv('./train.csv', encoding='bi
Step1:读懂题目

 题目的意思
题目的意思
- 训练集是:12个月–>每月的前20天–>每天的24小时–>每小时的18种不同属性的数值
- 测试集:240天–>连续的9小时–>18种不同的属性
- 要求的输出:根据某天连续的9小时–>18种不同的属性,预测第10小时的PM2.5的值。也就是通过一个18*9的矩阵预测出来一个值
Step2:数据预处理
# 读取数据csv文件,将csv数据保存为矩阵
data = pd.read_csv('./train.csv', encoding='big5') # read_csv顾名思义-读取csv文件 big5的编码是台湾和香港用的繁体
# print(data)
data = data.iloc[:, 3:] # 要全部行、不要前三列
data[data == 'NR'] = 0 # FAINFULL的值原来是NR,现实意义中表示是否降雨那么可以用0 1 来表示
# print(data)
arr_data = data.to_numpy() # 将data转换为numpy矩阵
数据处理到这里首先得到了一个二维的矩阵,一共有12*20*18行,每一行有24列
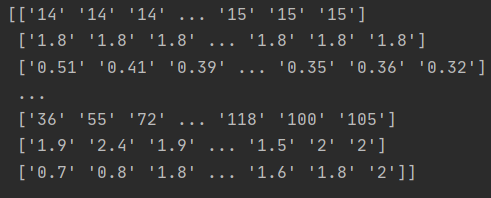 矩阵现在的结构是:
矩阵现在的结构是:

接下来要进一步处理数据,大致思想是把一个月的数据放到宏观的一行上去,这样一个月的小时就会一字排开,我们的实验是要求输入连续的9个小时的时间来预测第10小时的PM2.5值,放在一大行的好处就是可以有更多的连续9小时作为输入来训练。(我们将一个月的第一天到第二十天横向排序,那么我们可以使用滑动窗口的思想,取大小为9的窗口,从第一天的第0时一直可以划到第20天的第14时[为什么是14时,因为14+9=23,最后一个小时的PM2.5数据需要得到,所以这样处理可以最大化的利用已知训练集从而得到更多的数据]),画个图可能更好理解:
 首先把一个月放到一大行里,然后在慢慢滑动起始的时间,每9小时为为一组输入数据
首先把一个月放到一大行里,然后在慢慢滑动起始的时间,每9小时为为一组输入数据
 最后,再把12个月放在一起。
最后,再把12个月放在一起。
下面我们用代码实现以上思想,因为第一次接触这样处理数据还比较抽象,所以这里是直接copy了老师的代码再去理解。
month_data = {
}
for month in range(12):
sample = np.empty([18, 480]) # 一行sample代表一个月的20天数据-->18行(18种不同属性,每一天24小时一共20天,所以共有480列)
for day in range(20):
sample[:, (day * 24):((day + 1) * 24)] = arr_data[18 * (20 * month + day):18 * (20 * month + day + 1), :]
# 把一个月的所有天拼凑到一行上去
month_data[month] = sample
# 生成新的训练集矩阵
x = np.empty([12  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2689
2689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









