







逻辑回归复习
一句话概括逻辑回归:
逻辑回归假设数据服从伯努利分布,通过极大似然函数的方法,
运用梯度下降法来求解参数,来达到将数据二分类的目的
这句中有5个考点:
- LR的基本假设
- LR的损失函数
- LR的求解方法
- LR的目的
- LR如何做分类
基本假设
假设数据服从伯努利分布,就是假设 h θ ( x ) h_θ(x) hθ(x)样本的正面的概率为p,负面概率为1-p
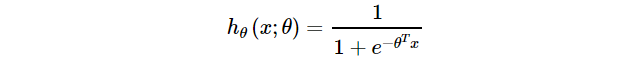
损失函数
损失函数一般有四种,平方损失函数,对数损失函数,HingeLoss0-1损失函数,绝对值损失函数
LR的损失函数就是它的极大似然函数,将极大似然函数取对数以后等同于对数损失函数,其实就是交叉熵
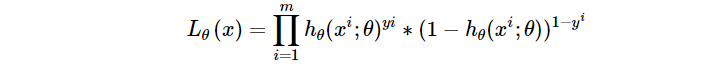
为
什
么
不
用
平
方
损
失
函
数
?
\color{red}为什么不用平方损失函数?
为什么不用平方损失函数?
答:因为如果你使用平方损失函数,你会发现梯度更新的速度和sigmod函数本身的梯度是相关的,梯度都不大于0.25,导致训练很慢,而对数损失函数的求解与sigmoid本身梯度无关
求解方法
sigmoid函数求导:
g
‘
(
z
)
=
g
(
z
)
(
1
−
g
(
z
)
)
g`(z)=g(z)(1-g(z))
g‘(z)=g(z)(1−g(z))
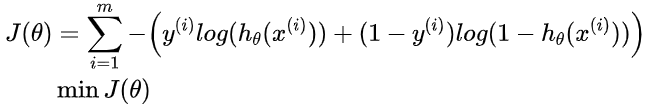
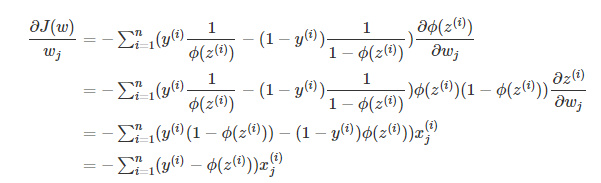
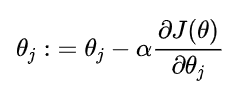
最终得到下面这个:
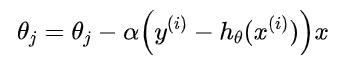
逻辑回归和最大熵模型本质上没有区别,最大熵在解决二分类问题时就是逻辑回归,在解决多分类问题时就是多项逻辑回归
这里包含了一个优化方法,就是梯度下降本身,有随机梯度下降,批梯度下降,small batch 梯度下降三种方式,如何选择最合适的方式?
答:
- 批量的优点是获得全局最优解,缺点是更新每个参数都要遍历所有数据,计算量很大
- SGD的优点是会找到新的和潜在的更好的局部最优解,缺点是收敛过程比较复杂
- 小批量的优点是结合上面两个的优点,每次更新n个样本,减少参数更新次数,达到稳定收敛的结果,深度学习用得比较多.
再深入就是学习率调整,Adam和动量法,学过,但暂时不说太多,反正就是学习过程中调整学习率。
逻辑回归的目的
对数据进行二分类,提高准确率,确定一个阈值来做分类
LR的优点
- 形式简单,模型可解释性好
- 模型效果不错,作为baseline很好用
- 训练速度较快
- 资源占用少,内存方面只需要存储各个维度的特征值
LR的缺点
- 准确率不算太高,且模型结构比较简单,很难拟合数据的真实分布
- 很难处理数据不平衡问题
- 如果不引入其他方法,处理不了非线性数据
其他问题
为什么把高度相关的特征去掉?
其实有很多特征高度相关也不会影响分类器的性能,但是可以大大提高训练速度,特征过多会影响训练时间
LR为什么要对特征进行离散化?
- 计算简单,稀疏向量内积乘法运算更快
- 鲁棒性更强,不易受噪声影响,碰到异常数据也不会造成过大干扰
- 模型泛化能力强,使得每个变量有单独权重,引入了非线性,增加模型表达能力,还可以做特征交叉,引入非线性
离散特征和连续特征其实就是,海量离散特征+简单模型” 与 “少量连续特征+复杂模型”的权衡,前者折腾特征,后者折腾模型(复杂模型通常是深度学习)
LR是线性模型吗?
广义上讲是线性模型,但是引入了sigmoid,所以狭义上又是非线性模型,本质是线性回归,只是加了一层sigmoid函数的映射
线性回归和逻辑回归区别?
- 线性回归
- 目标函数是最小二乘
- 服从高斯分布
- 输出是连续值
- 逻辑回归
- 目标函数是极大似然
- 服从伯努利分布
- 输出是离散值
SVM和LR的区别:
- 相同点:
- 都是分类、监督学习、判别式算法
- 都可以通过核函数针对非线性情况分类
- 都能减少离群点的影响
- 不同点:
- 损失函数不同,LR是交叉熵,SVM是Hinge loss
- LR优化参数时所有样本点都参与,SVM只取离分离超平面最近的支持向量样本。
- LR对概率建模,SVM对分类超平面建模
- LR是处理经验风险最小化,svm是结果风险最小化,体现在svm自带L2正则项
- LR是统计方法,SVM是几何方法
Naive Bayes与LR的区别:
-
相同点:
- 监督学习、分类算法
- 当NB的条件概率 P ( X ∣ Y = c k ) P(X|Y=c_k) P(X∣Y=ck)服从高斯分布,计算出来的 P ( Y = 1 ∣ X ) P(Y=1|X) P(Y=1∣X)形式与LR一样
-
不同点:
- LR是判别模型求p(y|x),NB是生成模型求p(x,y)
- LR要迭代优化,NB不用
- 数据量较少时,NB更好,反之,LR更好
- NB假设每个特征权重独立,若数据不符合,NB会表现不好















 921
921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









