







去重:distinct
将查询结果去重,原表数据不会被修改,只是查询结果去重。
如:查看岗位

注意: distinct只能出现在所有字段的最前方,distinct出现在两个字段之前,表示将两个字段联合去重
如:

也可以用在分组函数中
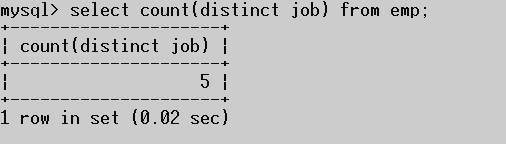
如:统计一下工作岗位的数量
连接查询(重点)
1、什么是连接查询?
从一张表中单独查询,称为单表查询。
两张表联合起来查询数据,这种跨表查询,多张表联合起来查询数据,被称为连接查询。
2、连接查询的分类
根据语法的年代分类
SQL92:1992年时的语法
SQL99:1999年时的语法(目标)
根据表连接的方式分类
内连接
等值连接
非等值连接
自连接
外连接
左外连接(左连接)
右外连接(右连接)
全连接
3、当两张表进行连接查询时,没有任何条件的限制会发生什么现象?
如:查询每个员工所在部门名称
select ename,dname from emp,dept
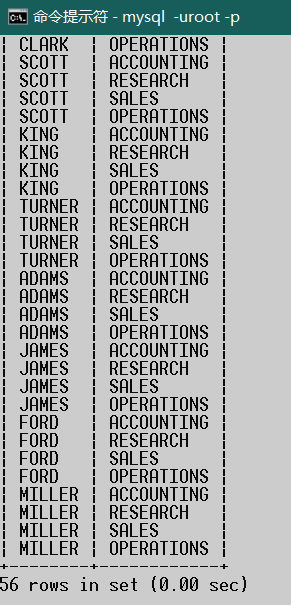
结论: 当两张表进行连接查询,没有任何条件限制的时候,最终查询结果条数,是两张表条数的乘积,这种现象被称为:笛卡尔积现象。(笛卡尔发现的,这是一个数学现象)
4、怎么避免笛卡尔积现象
连接时加条件,满足这个条件的记录才会被筛选出来!
如:
SQL92语法:
select
e.ename,d.dname
from
emp e,dept d //表起别名,可以很大的提高效率
where
e.deptno = d.deptno;
**sql92缺点:** 结构不清晰,表的连接条件,和后期进一步筛选的条件,都放到了where后面。

SQL99语法:

SQL99优点: 表连接的条件是独立的,连接之后,如果还需要进一步筛选,再往后继续添加where
99语法格式:
select
...
from
a
inner join //inner可以省略(带着inner可读性更好!)
b
on
a和b的连接条件
where
筛选条件
注意: 这么写最终的查询结果条数是14条,单是匹配的过程中,依旧是56次(emp表14条数据,dept表4条数据),只不过进行了四选一,匹配的次数并没有减少!,所以,通过笛卡尔积现象得出,表的连接次数越多效率越低,尽量避免表的连接次数
5、内连接之等值连接
select
...
from
a
inner join //inner可以省略(带着inner可读性更好!)
b
on
a和b的连接条件(条件为等量关系,所以被称为等值连接,如:e.deptno = d.deptno)
where
筛选条件
内连接特点: 完全能够匹配上这个条件的数据都查询出来
6、内连接之非等值连接
案例:找出每个员工的薪资等级,要求显示员工名、薪资、薪资等级
select
e.ename,e.sal,s.grade
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal;
因为老板没有上级所以只有14条记录,要想全部查看,需要使用外连接。

7、内连接之自连接
案例:查询员工的上级领导,要求显示员工名和对应的领导名
select
a.ename '员工名',b.ename '领导名'
from
emp a
join
emp b
on
a.mgr = b.empno; //员工的领导编号 = 领导的员工编号
自连接技巧:将一张表看做两张表
8、外连接
右外连接
//outer 可以省略不写,写了可读性更强
select
e.ename,d.dname
from
emp e right outer join dept d
on
e.deptno = d.deptno;
right代表将join关键字右边的这张表看成主表,主要是为了将这张表的数据全部查询出来,捎带着关联查询左边的表。
在外连接当中,两张表产生了主次关系。

左外连接
//outer 可以省略不写,写了可读性更强
select
e.ename,d.dname
from
dept d left outer join emp e
on
e.deptno = d.deptno;
带有right的是右外连接,又叫做右连接。
带有left的是左外连接,又叫做左连接。
任何一个右连接都有左连接的写法。
任何一个左连接都有右连接的写法。
思考:外连接的查询结果条数一定是大于等于内连接的查询结果条数吗?
正确!
案例:查询每个员工的上级领导,要求显示所有员工的名字和领导名

9、三张表、四张表怎么连接
语法:
select
...
from
a
join
b
on
a和b的连接条件
join
c
on
a和c的连接条件
(right/left)join
d
on
a和d的连接条件
一条SQL语句中内连接和外连接可以混合,都可以出现!
案例:找出每个员工的部门名称以及工资等级,还有上级领导,要求显示员工名、部门名、薪资、薪资等级,领导名
select
e.ename '员工名',d.dname '部门名',e.sal '薪资',s.grade '薪资等级'
from
emp e
join
dept d
on
e.deptno = d.deptno
join
salgrade s
on
e.sal between s.losal and s.hisal
left join
emp l
on
e.mgr = l.empno;

子查询
1、什么是子查询
select语句中嵌套select语句,被嵌套的select语句成为子查询
2、子查询都可以出现在哪里?
select
..(select).
from
..(select).
where
..(select).
3、where子句中的子查询
案例:找出比最低工资高的员工姓名和工资
实现思路:
第一步:查询最低工资是多少
select min(sal) from emp;
第二步:找出>800(最低工资)的
select ename,sal from emp where sal > 800;
第三步:合并
select ename,sal from emp where sal > (select min(sal) from emp);

4、from子句中的子查询
注意: from后面的子查询,可以将子查询的查询结果当做一张临时表(技巧!)
案例:找出每个岗位的平均薪资的薪资等级
select l.job,l.avgsal,s.grade from (select job,avg(sal) avgsal from emp group by job) l join salgrade s on l.avgsal between s.losal and hisal;

思路:
第一步:找出每个岗位的平均薪资,按照岗位分组求平均值
第二步:克服心理障碍,把以上的查询结果当做一张真实存在的表
5、select后面出现的子查询(了解即可)
案例:找出每个员工的部门名称,要求显示员工名,部门名

注意: 对于select后面的子查询来说,这个子查询只能一次返回1条结果,多于1条,就报错了!!
6、union:合并查询结果集
案例:查询工作岗位是MANAGER和SALESMAN的员工

或者

使用union

union特点:
union的效率要高一些,对于表连接来说,每连接一次新表,则匹配的次数满足笛卡尔积,成倍的翻。
但是union可以减少匹配的次数,在减少匹配次数的情况下,还可以完成两个结果集的拼接。
a 连接 b 连接 c
a 10条记录
b 10条记录
c 10条记录
匹配次数是:10*10*10 = 1000次
a 连接 b 一个结果:10*10 = 100次
a 连接 c 一个结果:10*10 = 100次
使用union的话:匹配次数是:100+100 = 200次(union将乘法变成了加法运算)
使用union时的注意事项:
union在进行结果集合并的时候,要求两个结果集的列数相同(如:查询字段的数量)
查询结果集的数据类型,在MySQL中可以忽略结果集的数据类型,但是在oracle中不行,oracle要求合并时列和列的数据类型也必须一致!
limit(重要*****)
1、limit作用是将查询结果集的一部分取出来,通常使用在分页当中
分页的作用是为了提高用户体验,因为一次全部查出来,用户体验差,可以一页一页的翻页看
2、limit使用方法
案例:按照薪资降序排序,取出排名在前5名的员工

完整用法:limit startindex(起始下标,从0开始) length(长度)
缺省用法:limit 5;去前5条数据
3、MySQL当中limit在order by 之后执行!!!
案例:取出工资排名在3-5名的员工
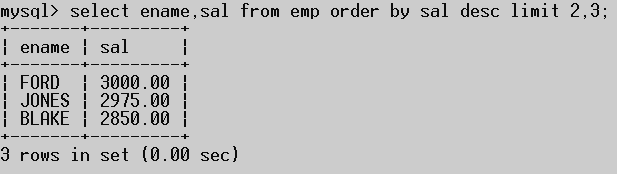
limit 2,3:2代表起始位置从下标开始,就是第三条记录,3表示长度
取出工资排名在5-9名的员工

4、分页
例如:每页显示3条记录
第一页:limit 0,3 [0 1 2]
第二页:limit 3,3 [3 4 5]
第三页:limit 6,3 [6 7 8]
第四页:limit 9,3 [9 10 11]
每页显示pagesize条数据
第pageNo页就是:
limit (paheNo -1) * pagesize,pagesize(**公式!**)
关于DQL语句的大总结:
select
...
from
...
where
...
group by
...
having
...
order by
...
limit
...
执行顺序:
1、form
2、where
3、group by
4、having
5、select
6、order by
7、limit















 2882
2882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









