







计算的复杂度和时间的关系:

Collection 接口扩展了Iterable接口。

List 接口扩展了Collection接口。

- 在遍历 List数组的时候,尤其是链表的情况下。有以下两种方案
1.通过while或者for循环,利用i遍历。如
while(i<list.size()){
list.get();
}for(Object i : list){
...
}
但是第二中方案有个坑,在做删除的时候会遇到一些问题,如:
List<Integer> link = makeList(2, 100);
for (Integer x : link) {
if(x%2==0){
link.remove(x);
}
}会抛出异常ConcurrentModificationException。该数组存入的内容是从0开始依次递增。在遍历list第一个数字为0,之后按照逻辑list的第一项被remove,之后返回到for循环那一步,并报错。可以利用迭代器解决该问题:
List<Integer> link = makeList(2, 100);
Iterator<Integer> linkIterator = link.iterator();
while(linkIterator.hasNext()) {
if(linkIterator.next()%2==0){
linkIterator.remove();
}
}- java 嵌套类和内部类的区分。
- 递归操作,每一层递归会产生一个活动记录的栈,如果递归过多,会导致栈溢出。 所以要注意代码编写的 防止“尾递归”使用不当。下面就是一个反面教材
public void printList (Iterator itr){
if (itr.hasNext())
return;
System.out.println(itr.next());
printList(itr)
}- 对于大量的输入数据,链表的线性访问时间太慢,不宜使用,移除二叉树。
- 二叉查找树的删除:情况有3:1. 叶子节点,删了就行。2.一个孩子,绕开即可。3.俩孩子,用其右子树的最小的数据,代替该节点的数据并递归删除。在java二叉树的删除中,和c中不同,例如abc三个节点,c在b右侧,b在a右侧,删除b。c语言的思路是,让a.right=c,java的思路是,b=c,这样a.right 就表示的c节点了。
AVL树
- AVL树的特性,是左右子树的深度最多差1。
- 不平衡的四种情况(不平衡的节点为a):1.a左儿子的左子树进行了一次插入。2.a左儿子的右子树进行了一次插入。3.a右儿子的左子树进行了一次插入。4.a右儿子的右子树进行了一次插入。归纳后为实际为两大类。
- 单旋转:旋转方法,从插入的节点开始,向根节点上行。遇到第一个不平衡的节点,标记a,该节点在路径上行时候的前一个节点b向上提拉。实现旋转。也就是原来b是a的子节点,a是根,旋转之后,b为根,a成了b的子节点。
- 双旋转: k1,k2,k3 分别对应 7.16.15 三个数,转化后k2,左k1,右k3
- 伸展树,当一个节点被访问后,它就要经过一系列的AVL树的旋转被推到根上。
B树
- 特点:M阶B树:
- 数据项存在树叶上。
- 非叶子节点存储直到M-1个关键字以指示搜索方向;关键字i代表子树i+1中的最小的关键字。
- 树的根或者是一片树叶或者儿子数在2和M之间。
- 除根外,所有非树叶节点的儿子数在┌M/2┐和M之间
- 所有的树叶都在相同的深度上并有┌L/2┐和L之间个数据项
- 插入:弱满则拆分。根节点满了增加跟。 删除:少则整合。
散列
链式和非链式
- 链式散列,在头端插入新元素,新近插入的元素最有可能不就又被访问。
- 装填因子(load factor)λ为散列中元素个数对该表大小的比。散列表的大小实际上并不重要,而装填因子才重要。散列大小最好是素数 或奇数。
- 双散列。完美散列0→1 1→null 2→2^2 4→1 6→2^2 9→3^2。布谷鸟散列,一个数据两种选择。跳房子,线性探测,事先确定一个队计算机底层结构而言最优的常熟,给探测序列的最大长度加个接线。
优先队列
- 二叉堆,后面堆排序用的到
- 左堆式。任一节点X的零路经常npl(x)定义为从x到一个不具有两个儿子的及诶点的最短路径的长。对于堆中每一个X,左儿子npl至少与右孩子npl相等。
排序
| 排序方法 | 时间复杂度(平均) | 时间复杂度(最坏) | 时间复杂度(最好) | 空间复杂度 | 稳定性 | 复杂性 |
|---|---|---|---|---|---|---|
| 直接插入排序 | O(n2)O(n2) | O(n2)O(n2) | O(n)O(n) | O(1)O(1) | 稳定 | 简单 |
| 希尔排序 | O(nlog2n)O(nlog2n) | O(n2)O(n2) | O(n)O(n) | O(1)O(1) | 不稳定 | 较复杂 |
| 直接选择排序 | O(n2)O(n2) | O(n2)O(n2) | O(n2)O(n2) | O(1)O(1) | 不稳定 | 简单 |
| 堆排序 | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | O(1)O(1) | 不稳定 | 较复杂 |
| 冒泡排序 | O(n2)O(n2) | O(n2)O(n2) | O(n)O(n) | O(1)O(1) | 稳定 | 简单 |
| 快速排序 | O(nlog2n)O(nlog2n) | O(n2)O(n2) | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | 不稳定 | 较复杂 |
| 归并排序 | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | O(n)O(n) | 稳定 | 较复杂 |
| 基数排序 | O(d(n+r))O(d(n+r)) | O(d(n+r))O(d(n+r)) | O(d(n+r))O(d(n+r)) | O(n+r)O(n+r) | 稳定 | 较复杂 |
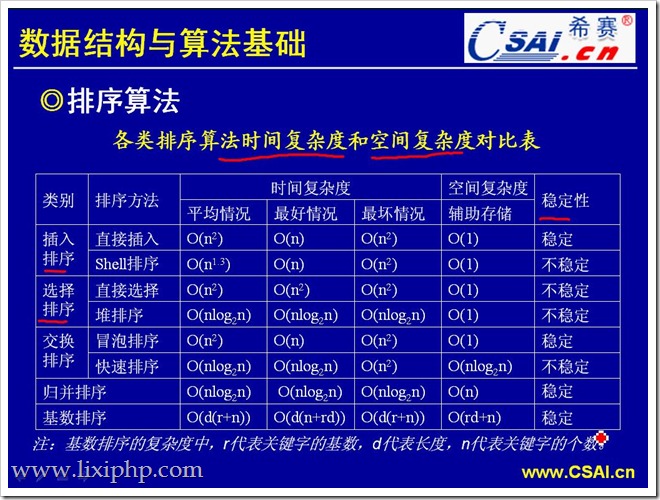
- 希尔,设定一半排序长度为步长,对步长内元素排序,步长/2,再次排序。
- 堆排序是一个非常稳定的算法,它使用的比较平均只比最坏情况界支出的略少。
- 快排枢纽元的寻找。
- 基数排序实现的内部,对于一小组的数排序,需要采用稳定的算法,如插入。
- 插入希尔归并快排。插入适合少量输入。希尔适合中等输入。归并需要额外空间。
图
- 无向图,每个顶点到其他顶点都有一条路径,连通图。
- 有向图,如上,强连通。
- 如果一个有向图不是强连通,但是基础图(去除弧上的方向形成的图)是联通的,弱联通。
- 完全图,每一对顶点都存在一条边。
- 拓扑排序
- 最短路径算法,dijkstra,无圈图,最早完成时间,最晚完成时。
- 网络流通
- 最小生成树
- 贪婪算法,下项合适,首次合适,最佳合适。联机,脱机。
- 分治算法。最近点。
- 动态规划
- 随机化算法
- 回溯算法















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









