







1.
顺序存储:顺序查找可以通过下标快速访问,相当于数组的访问形式,因此是O(1)。查找简单 O(1) ,但是插入和删除复杂度高O(n)。当删除顺序表某个结点后,计算机会自动将后续各个单元向前移动
链式存储:查找复杂度 O(n), 插入和删除操作:在第一次查找到插入或者删除位置时所需复杂度为O(n),插入和删除操作本身复杂度为O(1),因此,对于插入或者删除数据越频繁的操作,链表的优势越明显。当删除链中某个结点后,只是链表中节点指针指向的改变,链表不移动。
看具体应用场景,顺序存储比较适用于访问,删除和插入代价较大。顺序表可以根据索引直接定位元素(因为在内存中是顺序的,所以知道第一个元素的内存地址,其他元素都可以推算出来),而链表需要从头节点遍历整个表。
2.
线索二叉链表是利用(rchild)域存储后继结点的地址。
左孩子域:0:指示左孩子 1:指示节点的前驱
右孩子域:0:指示右孩子 1:指示节点的后继
线索二叉树(引线二叉树) 的定义如下:“一个二叉树通过如下的方法“穿起来”:所有原本为空的右(孩子)指针改为指向该节点在中序序列中的后继,所有原本为空的左(孩子)指针改为指向该节点的中序序列的前驱。”
孩子兄弟表示法是左孩子右兄弟
3.

循环队列是线性结构,实现申请一段连续存储空间
双向链表相比单链表只是在结点中增加了前驱指针域,不能由此判定是二叉树的存储结构
二叉树就是非线性结构,二叉树存在顺序存储结构,只是适合用于完全二叉树。所以4对
4.

最省时间:删除的话需要先找到,那样单链表(双向或者单向)就需要先循环一次,循环双链表直接找头结点的前一个即可。
5.
二叉树不满足线性表的线性结构特点:
(1)存在唯一的一个被称作“第一个”的数据元素;
(2)存在唯一的一个被称作"最后一个"的数据元素;
(3)除第一个元素之外,集合中的每个元素均只有一个前驱;
(4)除最后一个元素之外,集合中的每个元素均只有一个后继;
常用的线性结构:栈、队列、数组、串、链表、顺序表;
非线性结构:树(二叉树等)、图、二维数组、多维数组;
6.
一个非空广义表的表头可以是原子,也可以是子表;表尾一定是子表。
(1)《数据结构》对广义表的表头和表尾是这样定义的:
如果广义表LS=(a1,a2...an)非空,则 a1是LS的表头,其余元素组成的表(a2,a3,..an)是称为LS的表尾。
根据定义,非空广义表的表头是一个元素,它可以是原子也可以是一个子表,而表尾则必定是表。例如:LS=(a,b),表头为a,表尾是(b)而不是b.另外:LS=(a)的表头为a,表尾为空表().
(2)非空广义表,除表头外,其余元素构成的表称为表尾,所以非空广义表尾一定是个表
7.

头指针并不是链表的第一个节点,它指向头结点,头结点一般用来存储链表长度等无关信息,头指针的next指向链表第一个元素,因此选head→next==NULL。选项C的话 是针对循环链表的 循环链表为空,头结点指针指向自己。

注意:不论是带头结点的链表还是不带头结点的链表,头指针head(是指针)都指向链表中的第一个结点。如果该链表有头结点,则头指针head指向头结点,如果没有头结点,则头指针head指向链表的第一个节点。
1 带头结点的单链表中头指针head指向头结点,头结点的值域不含任何信息,从头结点的后继结点开始存储信息。头指针head始终不等于NULL,head->next等于NULL的时候链表为空。
2 不带头结点的单链表中的头指针head直接指向开始结点,当head等于NULL的时候链表为空。
头结点的存在,使得空链表与非空链表的处理变得一致,也方便了对链表的开始结点插入或删除操作。
 没有带头节点单链表
没有带头节点单链表
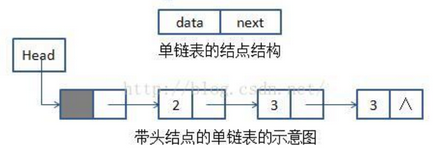 头结点:数据域可以不存储任何信息,头结点的指针域指向第一个结点。
头结点:数据域可以不存储任何信息,头结点的指针域指向第一个结点。


8.
数组优于链表的
(1)数组访问查询高效,可以随机存取,因为数组在内存里是连续的空间;链表在内存地址可能是分散的.所以必须通过上一节点中的信息找能找到下一个节点.。
(2)内存空间占用的少,因为链表节点会附加上一块或两块下一个节点的信息.但是数组在建立时就固定了。
链表优于数组:
(1)链表插入、删除操作方便,不会导致元素的移动,因为元素增减,只需要调整指针。 但是数组插入、删除操作不方便,因为插入、删除操作会导致大量元素的移动。
(2)链表可动态添加删除,大小可变;大小固定,不适合动态存储,不方便动态添加。
9.
线性表的长度是线性表所占用的存储空间的大小。 (错误)
线性表长度的定义是它所包含的元素的个数。元素的类型决定了元素所占用存储空间的大小,但元素的个数不等价于元素的类型。
10.
无向图存储:邻接矩阵、邻接表、多重邻接表
有向图存储:邻接矩阵、邻接表、十字链表















 5055
5055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









