







最近在练习使用python做一个爬虫练习,并打算使用双色球的数据来作为文本的测试
本文的思路是
1.先python GET网页源码获取网页源码
# ----------------------------------- 获取网页
def get_html(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
return response.text
except requests.RequestException:
return "Error"这里我们用GET参考的双色球频道_往期回顾
因为不同的网站源码不一样,主要讲解思路

soup = BeautifulSoup(html, 'html.parser')
2.使用BS4解析,通过特定标签取出期号+中奖球号
lottery_info = soup.find_all('tr')#根据tr标签找到开奖所有的期号行
先找到所有的tr行,因为我发现这个网站源码它没有class来标识
lottery_info会得到所有的tr行数据元素,然后我们在lottery_info中再去查找期号+球号
第二步使用center属性找到tr中的期号和球号,这里需要过滤一些

lottery_data = lottery_info[i].find_all('td',attrs={'align':'center'})
我们会发现期号就在
print(lottery_data[1].string) #从0开始,获得期号
第三步,我们再用em标签来获取具体的球号

#打印红球
redball = lottery_data[2].find_all('em')
print('红球的个数为是%d' % len(redball))
for i in range(len(redball)):
red = redball[i].string
print(red.strip()) #打印一只红球
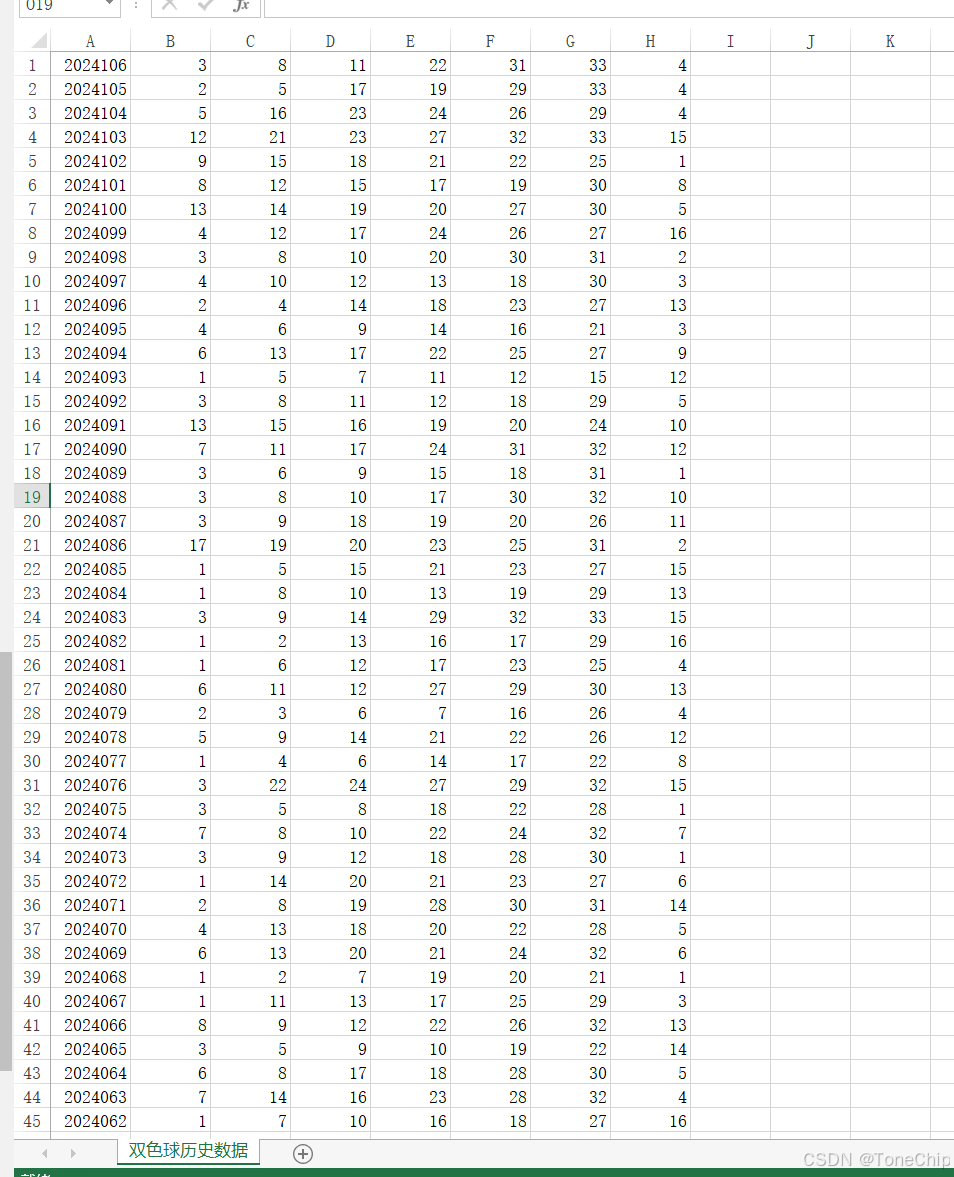
3.使用csv文件来保存文件
# ----------------------------------- 数据保存在文末
def append_to_csvFile(csv_data, filename):
with open(filename, 'a', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
# writer.writerow(['期号', '红球1', '红球2', '红球3', '红球4', '红球5', '红球6', '蓝球'])
for row in csv_data:
writer.writerow(row) #逐行写入最后保存结果如下
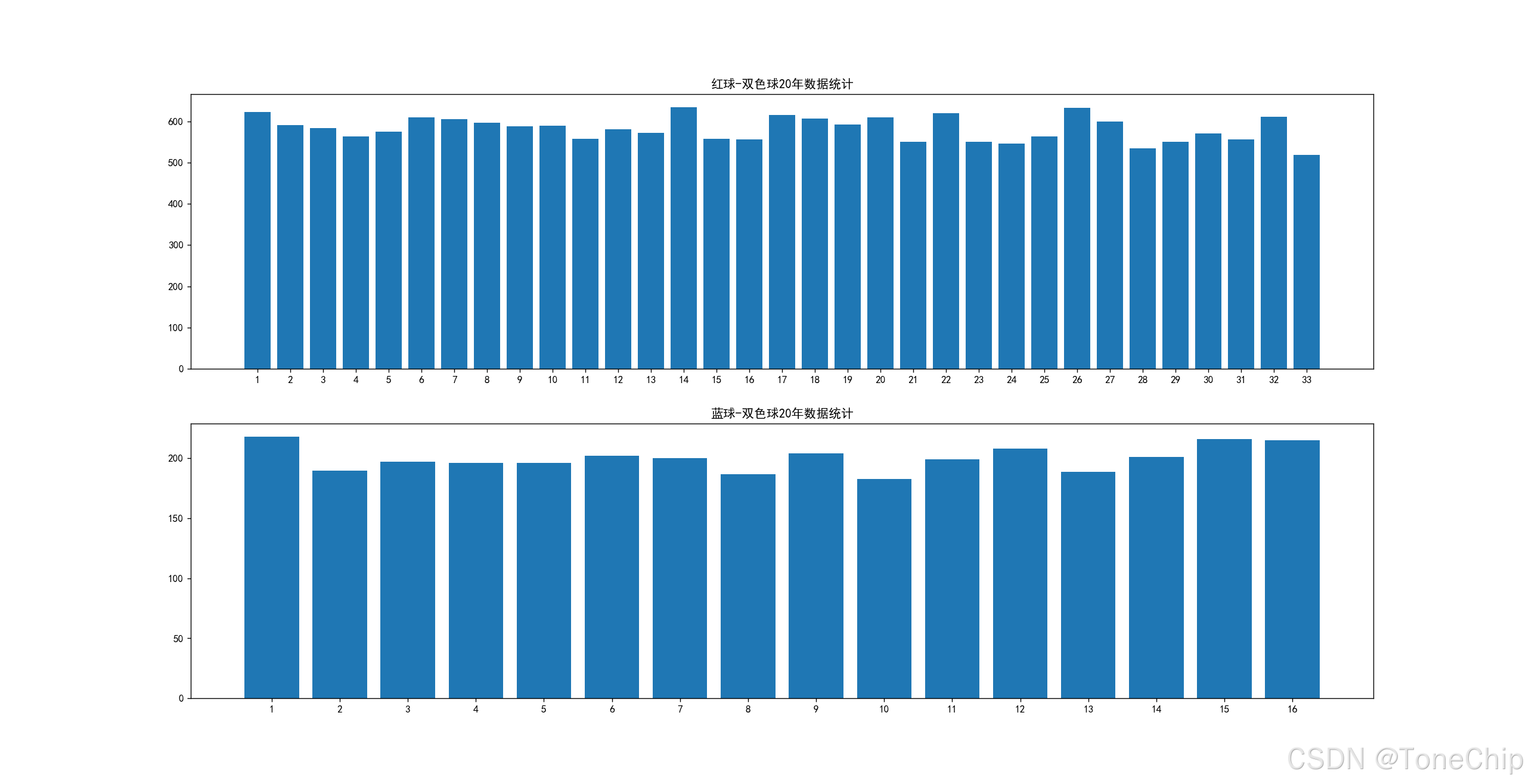
4.做一个简单的统计分析
我们通过统计每个球的在近20年出现的次数,来画一份柱状图



















 3941
3941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











