







YARN基本流程
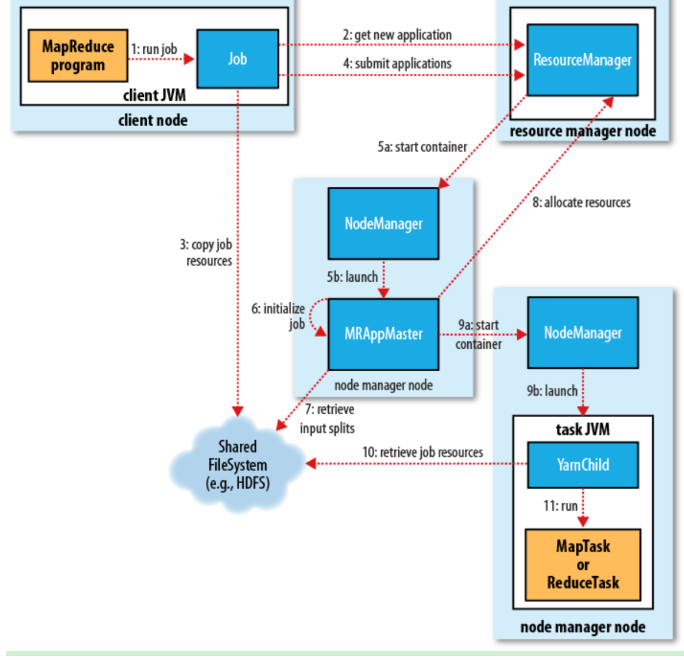
Job submission(作业提交)
Client通过RPC从ResourceManager中获取一个Application ID 检查作业输出配置,计算输入分片 拷贝作业资源(job jar、配置文件、分片信息)到HDFS,以便后面任务的执行Job initialization(作业初始化)
ResourceManager将作业递交给Scheduler(有很多调度算法,一般是根据优先级)Scheduler为作业分配一个Container,ResourceManager就加载一个application master process并交给NodeManager管理ApplicationMaster主要是创建一系列的监控进程来跟踪作业的进度,同时获取输入分片,为每一个分片创建一个Map task和相应的reduce task Application Master还决定如何运行作业,如果作业很小(可配置),则直接在同一个JVM下运行Task assignment(任务分配)
ApplicationMaster向Resource Manager申请资源(一个个的Container,指定任务分配的资源要求)一般是根据data locality来分配资源Task execution(任务执行)
ApplicationMaster根据ResourceManager的分配情况,在对应的NodeManager中启动Container 从HDFS读取任务所需资源(job jar,配置文件等),然后执行该任务Progress and status update(进度、状态更新)
定时将任务的进度和状态报告给ApplicationMaster Client定时向ApplicationMaster获取整个任务的进度和状态Job completion(作业完成)
Client定时检查整个作业是否完成 作业完成后,会清空临时文件、目录等
MR 工作原理
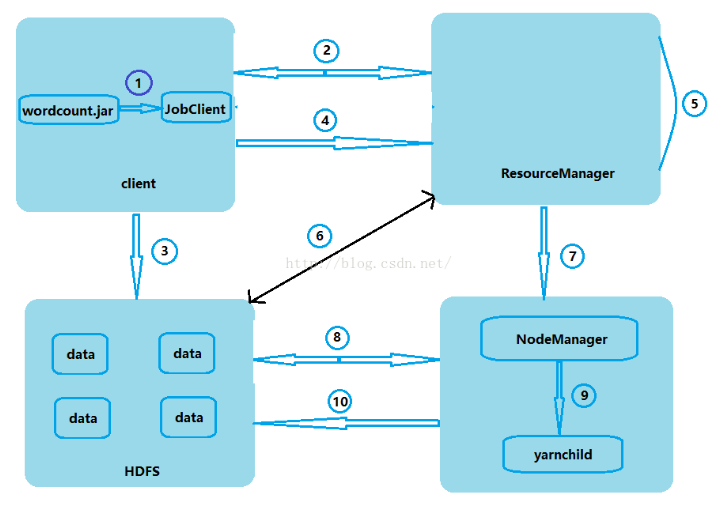
当我们执行hadoop jar wordcount.jar com.myhadoop.mr.WordCount /words /wcout0917这条命令时,会启动一个Job任务,该任务会被交给JobClient处理。
JobClient会通过RPC协议得到了ResourceManager的一个代理对象,然后开始与ResourceManager进行通信,JobClient会把JobID交给ResourceManager,ResourceManager会返回给JobClient一个地址的前缀,JobClient会把这个地址前缀拼接上JobID做为文件要存放的路径(拼接JobID的目的是为了防止地址重复)。
Client会使用FileSystem把数据写到HDFS系统上的这个拼接好的地址。
JobClient再把刚才数据存放的路径和JobID等描述信息传给ResourceManager,ResourceManager会把这些描述信息记录下来。
ResourceManager把接收的信息进行初始化并且把它们放到自己的任务调度器当中。
ResourceManager要看这个数据有多大,根据数据的大小来决定起多少个Mapper和多少个Reducer
NodeManager与ResourceManager通过心跳机制进行通信,NodeManager会向ResourceManager申请任务。
NodeManager申请到任务之后,便会到HDFS系统下载相应的jar包。
NodeManager下载完jar包之后,它会另外起一个java进程(yarnchild)来处理,在这个进程中有Mapper和Reducer
Reducer把数据都处理完之后,再把结果重新再写到HDFS系统上。
MR原理
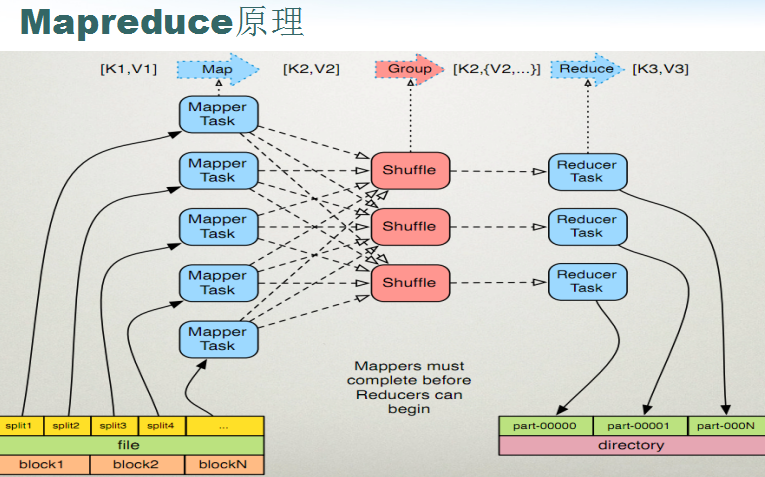
如下图所示:一个file文件可能被物理切分成block1、block2…blockN块,一个块又被切分成了多个切片(切片个数可配),每个切片对应着一个MapperTask,每个Mapper把处理后的结果(Map)传给shuffle处理,shuffle处理完之后再交给Reducer进行处理,Reducer处理完之后把处理结果写到结果文件当中,每个Reducer对应一个结果文件。
MR (1.0版本) 执行流程
(1)、客户端提交一个mr的jar包给JobClient(提交方式:hadoop jar …)
(2)、JobClient通过RPC和JobTracker(RM)进行通信,返回一个存放jar包的地址(HDFS)和jobId
(3)、client将jar包写入到HDFS当中(path = hdfs上的地址 + jobId)
(4)、开始提交任务(任务的描述信息,不是jar, 包括jobid,jar存放的位置,配置信息等等)
(5)、JobTracker进行初始化任务
(6)、读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个MapperTask
(7)、TaskTracker通过心跳机制领取任务(任务的描述信息)
(8)、下载所需的jar,配置文件等
(9)、TaskTracker启动一个java child子进程,用来执行具体的任务(MapperTask或ReducerTask)
(10)、将结果写入到HDFS当中















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









