







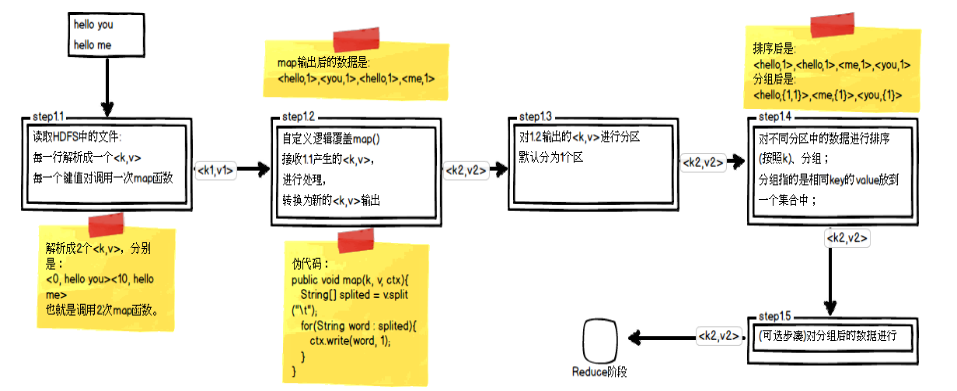
回顾Map阶段五大步骤
其中,step1.3就是一个分区操作。通过前面的学习我们知道Mapper最终处理的键值对key/value,是需要送到Reducer去合并的,合并的时候,有相同key的键/值对会送到同一个Reducer节点中进行归并。哪个key到哪个Reducer的分配过程,是由Partitioner规定的。Hadoop内置Partitioner
MapReduce的使用者通常会指定Reduce任务和Reduce任务输出文件的数量(R)。用户在中间key上使用分区函数来对数据进行分区,之后在输入到后续任务执行进程。一个默认的分区函数式使用hash方法(比如常见的:hash(key) mod R)进行分区。hash方法能够产生非常平衡的分区,鉴于此,Hadoop中自带了一个默认的分区类HashPartitioner,它继承了Partitioner类,提供了一个getPartition的方法,它的定义如下所示:
package org.apache.hadoop.mapreduce.lib.partition;
import org.apache.hadoop.mapreduce.Partitioner;
/** Partition keys by their {@link Object#hashCode()}. */
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value, int numReduceTasks) {
// 默认使用key的hash值与上int的最大值,避免出现数据溢出 的情况
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
// 这段代码实现的目的是将key均匀分布在Reduce Tasks上,例如:如果Key为Text的话,
// Text的hashcode方法跟String的基本一致,都是采用的Horner公式计算,得到一个int整数。
// 但是,如果string太大的话这个int整数值可能会溢出变成负数,所以和整数的上限值Integer.MAX_VALUE(
// 即0111111111111111)进行与运算,然后再对reduce任务个数取余,这样就可以让key均匀分布在reduce上。- 定制Partitioner
定制partitioner需继承Partitioner
package com.zz.hadoop.dc.mr;
import java.io.IOException;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.zz.hadoop.dc.factory.Factory;
import com.zz.hadoop.dc.po.DataInfo;
/**
* 统计每个手机号使用的流量, 并按照手机号类型(移动、联通、电信)进行分区输出
*/
public class DataCount {
public static void main(String[] args)
throws IOException, ClassNotFoundException, InterruptedException {
Configuration config = new Configuration();
Job job = Job.getInstance(config);
job.setJarByClass(DataCount.class);
job.setMapperClass(DCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DataInfo.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setReducerClass(DCReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DataInfo.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置分区类
job.setPartitionerClass(DCPartitioner.class);
// 设置启动reducer数量(若 reduce数量 >= partitioner数量, 则多余的分区为空;
// 若 reduce数量 < partitioner数量, 则会出错。)
job.setNumReduceTasks(4);
job.waitForCompletion(true);
}
/** 每运行一次mapper就是一个mapper对象,不存在线程安全问题 */
public class DCMapper extends Mapper<LongWritable, Text, Text, DataInfo> {
// 每context.write()一次就已经序列化了, 不存在同一引用问题
private Text k2 = new Text();
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
String line = v1.toString();
String[] fields = line.split("\t");
// tel
String tel = fields[1];
// upPayLoad(上行流量)
long up = Long.parseLong(fields[8]);
// downPayLoad(下行流量)
long dn = Long.parseLong(fields[9]);
DataInfo data = new DataInfo(tel, up, dn);
this.k2.set(tel);
// context.write(new Text(tel), data);
context.write(k2, data);
}
}
/** Reduce */
public class DCReduce extends Reducer<Text, DataInfo, Text, DataInfo> {
@Override
protected void reduce(Text k2, Iterable<DataInfo> v2s, Context context)
throws IOException, InterruptedException {
long up = 0;
long dn = 0;
for (DataInfo dataInfo : v2s) {
up += dataInfo.getUpPayLoad();
dn += dataInfo.getDownPayLoad();
}
context.write(k2, new DataInfo(k2.toString(), up, dn));
}
}
/** 分区 */
public static class DCPartitioner extends Partitioner<Text, DataInfo> {
private static Map<String, Integer> provider = Factory.getMap();
// 模拟移动、联通、电信分段号对应的分区码
static {
provider.put("138", 1);
provider.put("139", 1);
provider.put("155", 2);
provider.put("156", 2);
provider.put("180", 3);
provider.put("181", 3);
}
@Override
public int getPartition(Text k2, DataInfo v2, int numPartition) {
String sub = k2.toString().substring(0, 3);
Integer code = provider.get(sub);
if (null == code) {
code = 0;
}
return code;
}
}
}
// 封装对象(须implements Writable)
package com.zz.hadoop.dc.po;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class DataInfo implements Writable {
private String tel;
private long upPayLoad;
private long downPayLoad;
private long totalPayLoad;
public DataInfo() {
super();
}
public DataInfo(String tel, long upPayLoad, long downPayLoad) {
super();
this.tel = tel;
this.upPayLoad = upPayLoad;
this.downPayLoad = downPayLoad;
this.totalPayLoad = upPayLoad + downPayLoad;
}
// ...省略get、set
/** 注意:filed type、 filed order 依次顺序序列化、和反序列化 */
@Override
public void readFields(DataInput in) throws IOException {
this.tel = in.readUTF();
this.upPayLoad = in.readLong();
this.downPayLoad = in.readLong();
this.totalPayLoad = in.readLong();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.tel);
out.writeLong(this.upPayLoad);
out.writeLong(this.downPayLoad);
out.writeLong(this.totalPayLoad);
}
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









