







如何将原始信息转化为计算机能看懂的数据?
我们需要将目标的特征转化为计算机所能理解的数据。最常用的方式就是提取现实世界中的对象之属性,并将这些转化为数字。
这里再强调一下贝叶斯定理的核心思想:用先验概率和条件概率估计后验概率。
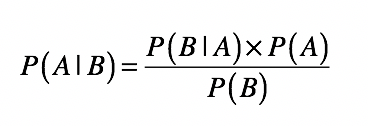
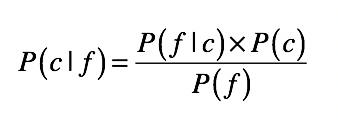
其中,c 表示一个分类(class),f 表示属性对应的数据字段(field)。如此一来,等号左边的 P(c|f) 就是待分类样本中,出现属性值 f 时,样本属于类别 c 的概率。而等号右边的 P(f|c) 是根据训练数据统计,得到分类 c 中出现属性 f 的概率。P©是分类 c 在训练数据中出现的概率,P(f) 是属性 f 在训练样本中出现的概率。
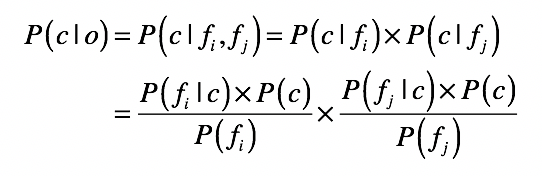
内容比较多,我稍微总结一下。朴素贝叶斯分类主要包括这几个步骤:
1:准备数据:针对水果分类这个案例,我们收集了若干水果的实例,并从水果的常见属性入手,将其转化为计算机所能理解的数据。这种数据也被称为训练样本。
2:建立模型:通过手头上水果的实例,我们让计算机统计每种水果、属性出现的先验概率,以及在某个水果分类下某种属性出现的条件概率。这个过程也被称为基于样本的训练。
3:分类新数据:对于一颗新水果的属性数据,计算机根据已经建立的模型进行推导计算,得到该水果属于每个分类的概率,实现了分类的目的。这个过程也被称为预测。
1:和 KNN 最近邻相比,朴素贝叶斯需要更多的时间进行模型的训练,但是它在对新的数据进行分类预测的时候,通常效果更好、用时更短。
2:和决策树相比,朴素贝叶斯并不能提供一套易于人类理解的规则,但是它可以提供决策树通常无法支持的模糊分类(一个对象可以属于多个分类)。
3:和 SVM 支持向量机相比,朴素贝叶斯无法直接支持连续值的输入。所以,在前面的案例中,我将连续值转化成了离散值,便于朴素贝叶斯进行处理。















 2969
2969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









