







目录
高效利用Sentry追踪日志发现问题
1、为什么需要一个日志追踪服务?
面临的问题
程序运行的日志是一个必不可少的东西,可能是一些系统信息,比如 gc 的情况;可能是一些正常的模块处理信息,比如最近更新的配置;还可能是一些在程序运行中,我们不希望出现的错误所带来的信息。通过日志,可以知道我们的程序是不是在正常地运行,看到错误日志,我们还需要利用日志排查错误。
我们知道日志如此重要,并乐于记录日志,然而在发现并解决问题的过程中,日志并没有想象中的高效率。
01 文件过于分散
一般会将不同模块的日志以文件的形式分开保存。即使是将日志写在统一的目录下,不管是系统正常运行还是出现问题的时候都可能需要检查多个日志。
02 内容过于繁杂
不太同于代码崇尚简洁,特别是遇到问题的时候,日志更是越详细越好,巴不得日志能记录下所有上下文信息和关联的代码。但是在查看日志的时候却往往不得不反复前后翻看错误的关联日志信息,同时还要略过大量无关信息,还没开始解决问题脑细胞就死了好多。
03 解决问题的被动性
很可能在程序刚开始运行起来的时候,我们会检查一下情况,看看日志是否正常。但是更多的时候我们根本不会想去看那些冗长的日志。过了一段时间,突然有人告诉我们问题出现了,便又怀着沉重的心情慌张地检查日志开始排查错误。
如何解决
考虑传统的解决方案,规定好统一的日志格式,将所有模块的日志进行适配之后统一管理起来,并建立相应的日志分类与报表,在检查到问题的时候通过邮件的形式通知运维。这样的解决方案对于小公司来说,需要的时间和技术成本还是很大的,真正能提高日志利用的效率,还需要很长的规划与不断的总结。
而我们这样的小公司就中意这样的简单粗暴的方案: 1 个小时搭建整个平台!日志汇集、聚合、主动报警、漂亮的界面,都有了—— Sentry 。
那么 Sentry 到底如何帮助我们有效利用日志发现并解决程序问题的呢?
Sentry 初试
Server 的安装教程官网已经非常详细了,如果不要求 HA ,只需要额外确定依赖的 redis 和 postgresql 安装好了就行。
Sentry 不但有多种语言的客户端,还直接支持大量的日志框架,比如 java 的 log4j ,logback 。这就意味着我们之前的代码几乎可以不用做任何修改,而仅仅加一点配置即可。
如果想要快速欣赏一下 Sentry 的芳容,可以现在就尝试一下官方的 saas (当然它是免费的):
Sentry 团队很贴心地让你可以快速建立一个自己的 demo 尝试它的运用。
简单的使用示例
拿官方的 saas 快速认识 Sentry :
注册好你的账户后,会有提示帮助你建立好自己的项目,并选择想要使用的客户端平台或框架(这里以 logback 为例):
(点击查看大图)
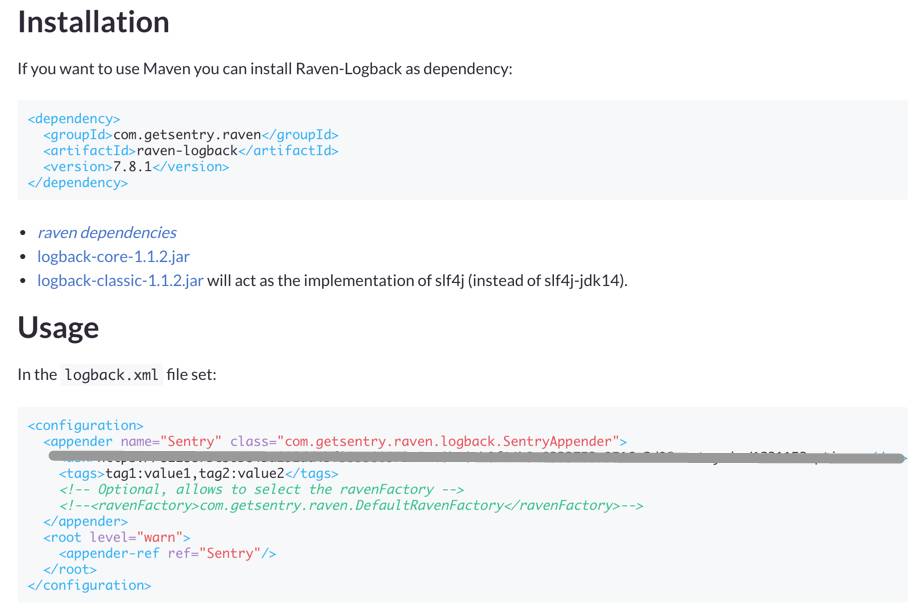
到这里为止,我们就差一步就可以看到效果了:添加一个依赖和一个 logback 的 appender 到你的项目配置里,其他的代码可以一点不变,记日志还是熟悉的配方。
配置好依赖和 appender ,运行一些写入日志的代码后,你就会收到两方面的反馈:
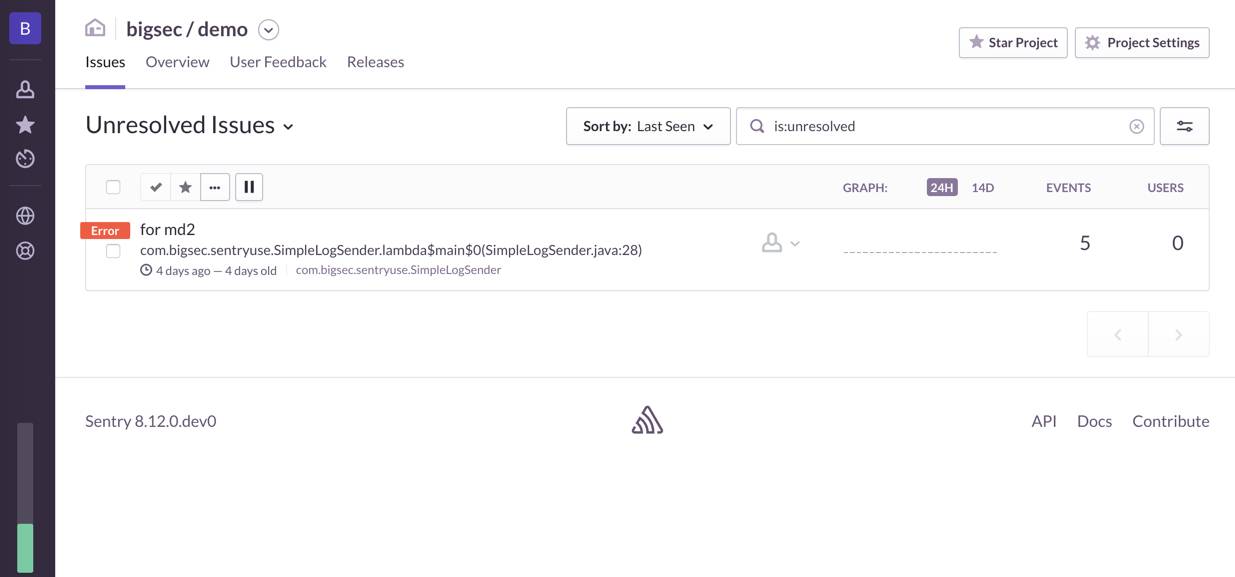
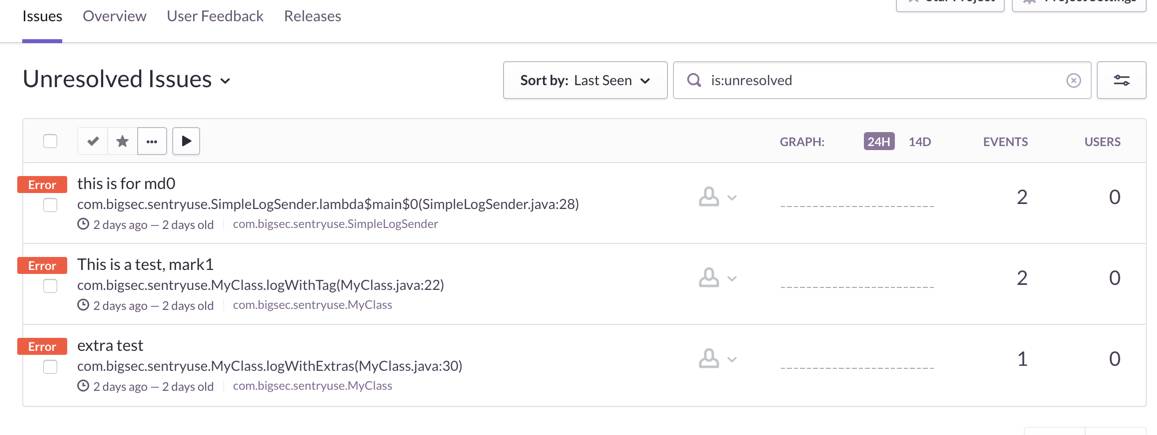
01 面板上出现待解决的 issues :
02 收到新 issues 的邮件:
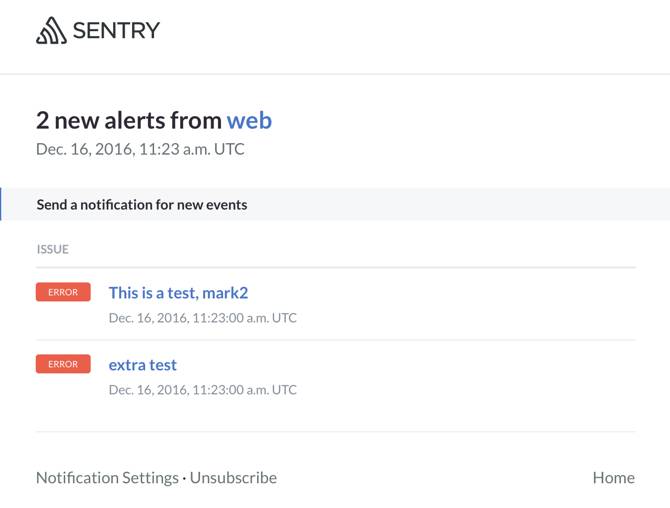
怎么样,对 Sentry 已经有了一个直观的感受了吧。
Sentry 如何解决问题
我们使用 Sentry 就是为了解决日志利用的低效率问题,那么 Sentry 是怎么帮助我们解决的呢。答案就在几个重要的概念中,当然 Sentry 有详尽的官方使用说明和文档。
示例中是加在 appender 中的标签。这个就是 Sentry 的实际连接地址, Sentry 通过这个来知道到底将日志发送到哪里。
从上面的图可以发现有 3 个 error 标记的 issue 标签,实际上代码里面发送了 5 条 error 的日志。这是 Sentry 很重要的一点:
我们需要看的不是单单一条日志,而是一类日志。
一些聚集的日志才能尽可能地反映整个错误的情况,即一个 issue ,而这些有关联的日志在 Sentry 这边就转化为这个 issue 的关联的 events 。
回想一下我们通过日志文件来排查错误的时候,是不是就是自己耐心地运用肉眼过滤掉一系列无关的日志,然后大脑中聚合好这些有关联的日志,尽可能全面地了解一个错误呢。
除了帮我们省掉这些事情,Sentry 提供了更丰富的数据来充实这些 events ,点击一个 issue ,便会进入这个 issue 的详细信息:
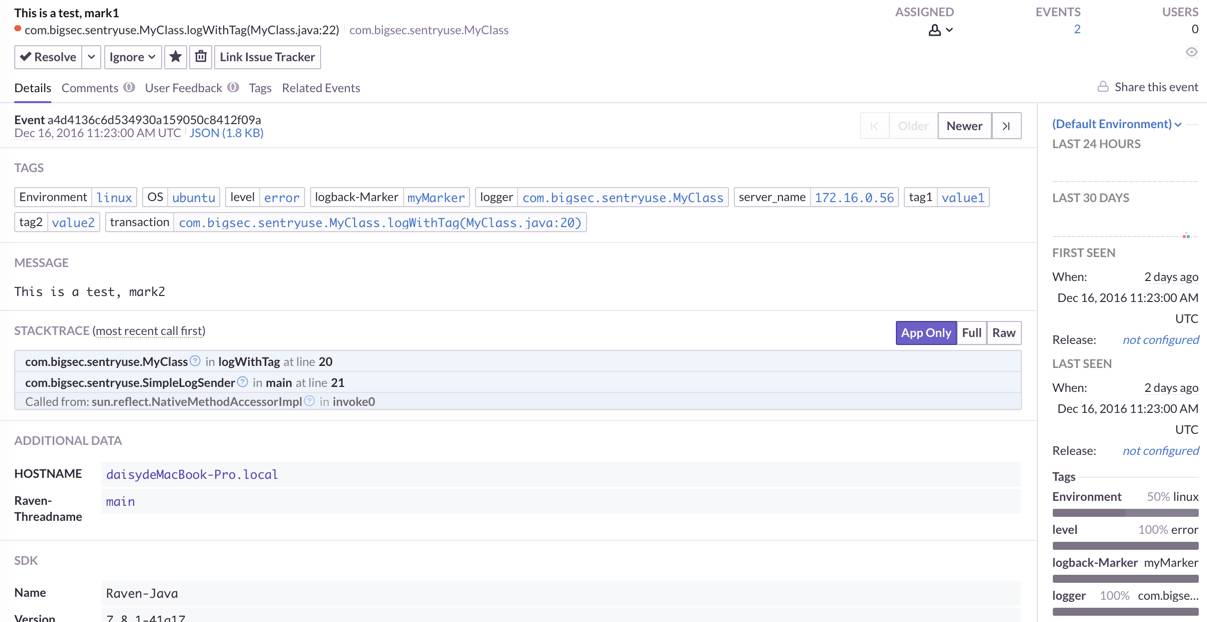
(点击查看大图)
不仅可以看到我们主动加上的 message , stacktrace , Sentry 还帮我们加上了一些额外的 tags (我们也需要自己去定义一些有用的 tags ),尽可能多的展现一个 issue 发生前的状况。另外一个亮点在右边,展示了这个 issue 的一些统计信息。
Sampling
Sentry 不是为了日志存储,也不会将所有日志都记录下来(毕竟使用关系型数据库作为持久化存储)。每个发送到 Sentry 的日志都是一个提供 issue 信息的事件(event),而每个项目发送到 Sentry 的事件都有一个数量上限,一旦超过这个上限 Sentry 就会忽略掉重复的内容。
Sentry 是我们所有日志的一个关于错误,问题的分析子集。体现在界面上的 events 信息,也是 Sentry 聚合之后的样本。
聚合策略
Sentry 按照策略将日志事件进行聚合,从而提供一个 issue的events 。这么做就是为了智能地帮助我们组合关联的日志信息,减少人工的日志信息的提取工作量,关注一个 issue 首先关注这些聚合的事件。但是这个策略分组并不会那么智能,Sentry 主要按照以下几个方面,优先级从高到低进行日志事件的聚合:
1. Stacktrace
2. Exception
3. Template
4. Messages
要注意的是,如果日志记录比较随意,聚合的效果可能不尽如人意。例如:两个无关的事件但是 stacktrace 相同,那么 Sentry 会将它们分到同一个 issue 下。
alerts digest & limit
默认 Sentry 的 alerts 会发送邮件(你也可以推送 slack!)。当一个 issue 产生或者一组 issue 产生时,项目相关的成员都会受到邮件。但是并不是每次 issue 有更新就会产生 alert 。
考虑到用户也不希望被一箩筐的报警邮件给轰炸,因为过多相当于没有, Sentry 除了对重复的报警进行抑制,还会追加一段时间内更新 issue 的摘要(digest)到下一个报警,这样,用户邮件上接收到的信息会充分压缩,不用苦恼于过多的邮件。另外,每个用户可以根据自己的喜好自行配置报警的时间间隔。
总结
Sentry 还有有很多亮点,比如敏感信息过滤, release 版本跟踪,关键字查找,受影响用户统计,权限管理等(部分可能需要我们通过代码提供内容)可以通过 Sentry 进行问题分配与跟踪。Sentry 的 plugin 模块还可以集成大量的第三方工具如: slack , jira 。
对我们来说最大的便利就是利用日志进行错误发现和排查的效率变高了。
01 及时提醒
报警的及时性:不需要自己再去额外集成报警系统,一旦产生了 issue 便以邮件通知到项目组的每个成员。
02 问题关联信息的聚合
每个问题不仅有一个整体直观的描绘,聚合的日志信息省略了人工从海量日志中寻找线索,免除大量无关信息的干扰。
03 丰富的上下文
Sentry 不仅丰富还规范了上下文的内容,也让我们意识到更多的有效内容,提高日志的质量。
最后,完全依赖Sentry?
虽然 Sentry 让我们在使用日志上的效率提高了,但是有几点还是需要注意。
01 不是日志的替代
Sentry 的目的是为了让我们专注于系统与程序的异常信息,目的是提高排查问题的效率,日志事件的量到达一个限制时甚至丢弃一些内容。官方也提倡正确设置 Sentry 接收的日志 level 的同时,用户也能继续旧的日志备份(用 logback 的同学仅仅是保留自己以前的 appender 就好)。
02 不是排查错误的万能工具
Sentry 是带有一定策略的问题分析工具,以样本的形式展示部分原始日志的信息。信息不全面的同时,使用过程中也可能出现 Sentry 聚合所带来的负面影响,特别是日志记录质量不够的情况下。
03 不是传统监控的替代品
与传统的监控系统相比,Sentry 更依赖于发出的日志报告,而另外一些隐藏的逻辑问题或者业务问题很可能是不会得到反馈的。
转自FreeBuf.COM
Sentry - 处理异常日志的正确姿势
在各种系统和应用里,无论你的代码再完美也还是会抛异常,出错误。今天的主角是当今比较流行的异常记录框架 - Sentry,来了解一下。
关于日志管理
应用越做越复杂,输出日志五花八门,有print的,有写stdout的,有写stderr的, 有写logging的,也有自定义xxx.log的。那么这将导致平台应用日志分布在各个地方,无法统一管理。而且可能用的还不止一种开发语言,想规范和统一日志不是一件容易的事。
为什么使用Sentry
Sentry是一个集中式日志管理系统。它具备以下优点:
- 多项目,多用户
- 界面友好
- 可以配置异常出发规则,例如发送邮件
- 支持主流语言接口
从Sentry的文档首页截下来的一张图,可以看到它支持目前主流的编程语言。

安装和快速上手
Sentry支持部署到本地服务器,具体可以参考以下文档:
但作为大多数个人开发者和中小企业,我更建议使用Sentry官网(https://sentry.io/)提供的云服务,你只需要注册一个Sentry账号,就可以快速享受到集中处理异常日志的服务。
Sentry免费版可以:
- 每月10k 错误日志上限
- 支持所有平台和语言,功能无缩水
- 无限项目数量,仅单用户访问,不提供团队功能
具体的价格表可以看这里:
开始配置DSN
你可以认为 DSN(Data Source Name)是Sentry 管理项目需要的PROJECT_ID,每个应用都需要对应一个 PROJECT_ID,以及用于身份认证的 PUBLIC_KEY 和 SECRET_KEY。由此组成一个这样的 DSN:
{PROTOCOL}://{PUBLIC_KEY}:{SECRET_KEY}@{HOST}/{PATH}{PROJECT_ID}PROTOCOL 通常会是 http 或者 https,HOST 为 Sentry 服务的主机名和端口,PATH 通常为空。
在你登入Sentry后台之后,你可以新建一个项目,之后就可以得到类似于下面这样一个DSN。
https://e055040d5@sentry.io/12345有了DSN以后,你就可以在客户端中将错误日志上传到Sentry了。
配置客户端
这里我主要以Python为例,其他编程语言的客户端配置可以参考官网文档,步骤大同小异。
首先通过pip安装Sentry SDK。
pip install raven --upgrade然后初始化客户端。
from raven import Client
DSN = 'https://****@sentry.io/****'
client = Client(DSN)最后,在你需要记录异常的代码为止调用client.captureException()即可。
try:
1 / 0
except ZeroDivisionError:
client.captureException()很多时候我们的异常信息应该包含更多的上下文信息,这样对于我们做后续分析会有更多帮助,那么你可以在Sentry捕获异常前加入这些上下文。
try:
processing(user, data)
except:
client.user_context({
'user': user.email,
'data': json.dumps(data)
})
client.captureException()一些经验之谈
当然,我们不可能在每处可能发生异常的代码为止都调用Sentry,也不可能去修补过去的代码将Sentry一一植入,一个好的建议是,无论何时,你的程序都有统一的异常处理机制,最好是全局的。这样的话,你只要将Sentry写在全局的异常处理器即可。
另外Sentry还对流行的开发框架提供了特别的支持,比如Flask,Django等等,在这些应用中你只要配置就行,不需要你去写什么全局的异常处理(虽然写起来也不难)。
Flask的例子:
sentry = Sentry(dsn='http://public_key:secret_key@example.com/1')
def create_app():
app = Flask(__name__)
sentry.init_app(app)
return appDjango的例子:
import os
import raven
INSTALLED_APPS = (
'raven.contrib.django.raven_compat',
)
RAVEN_CONFIG = {
'dsn': 'http://public_key:secret_key@example.com/1',
# If you are using git, you can also automatically
# configure the release based on the git info.
'release': raven.fetch_git_sha(os.path.abspath(os.pardir)),
}异常报告和提醒
一旦你完成上面的配置,以后系统发生的所有错误异常都会被自动记录到Sentry,查看报告就是一件轻松愉快的事情了。
默认情况下,一旦异常发生,5分钟内就会有一封邮件送到你邮箱,包含了异常信息的大致描述。

当然你还可以将异常报警集成到更多系统中,比如HICHAT,SLACK,IRC,WEBHOOKS,在Sentry后台提供了相应的入口。
在Sentry的项目 Dashboard 你可以浏览到更详细的报告,比如按照异常信息的类别进行分类和过滤,也可以统计近期异常的状态和频率,非常方便。

Sentry还提供了异常信息的聚合,同样的错误有可能在多处抛出,传统的日志统计起来就不是很方便,在Sentry一目了然。
另外你还可以针对异常问题进行分配和跟踪,例如指派团队的某个成员去处理某一类问题,对于长时间没有再发生的问题自动标记为解决等等。
总结
Sentry 还有有很多亮点,比如敏感信息过滤, release 版本跟踪,关键字查找,受影响用户统计,权限管理等。Sentry 的 plugin 模块还可以集成大量的第三方工具如: SLACK , JIRA 。
对我们来说最大的便利就是利用日志进行错误发现和排查的效率变高了。但是,我们能不能完全依赖Senry呢?有几点值得探讨:
不是日志的替代品
Sentry 的目的是为了让我们专注于系统与程序的异常信息,目的是提高排查问题的效率,日志事件的量到达一个限制时甚至丢弃一些内容。官方也提倡正确设置 Sentry 接收的日志 level 的同时,用户也能继续旧的日志备份。
不是排查错误的万能工具
Sentry 是带有一定策略的问题分析工具,以样本的形式展示部分原始日志的信息。信息不全面的同时,使用过程中也可能出现 Sentry 聚合所带来的负面影响,特别是日志记录质量不够的情况下。
不是传统监控的替代品
与传统的监控系统相比,Sentry 更依赖于发出的日志报告,而另外一些隐藏的逻辑问题或者业务问题很可能是不会得到反馈的。















 1834
1834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









