







Redis缓存污染怎么办?
什么叫做内存污染
内存污染其实指数据进入缓存后使用较少,但一直占用缓存空间不释放,这种就可以称为内存污染,那生产中如何避免内存污染产生呢?内存淘汰策略。
内存淘汰策略分析
内存淘汰策略就可以解决内存污染的问题,但这里需要注意的是,内存淘汰选取不同的策略得到的效果是不一样的,这个需要根据策略具体分析,内存淘汰策略分为如下几种4.0之前是6种,4.0之后是8种。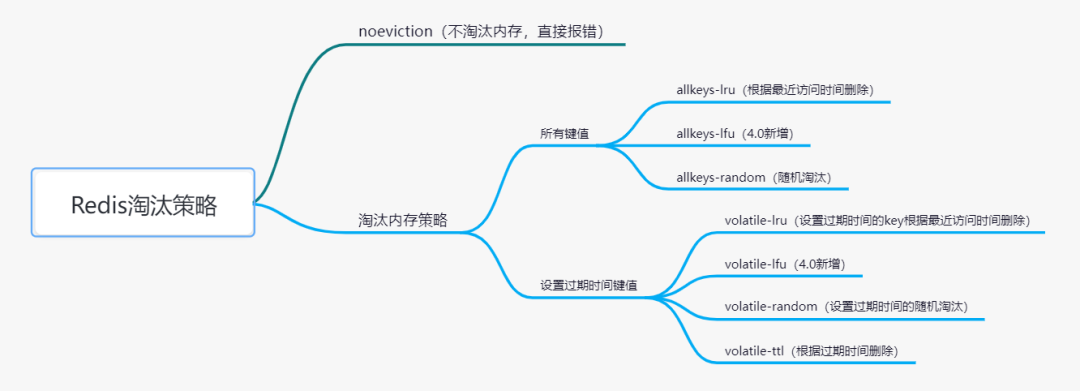
其中noeviction对缓存污染没有效果,因为达到最大内存后只报错而不进行任何淘汰操作。
allkeys-random和volatile-random
allkeys-random指在所有的键值中随机删除键值,而volatile-random指在设置过期时间的所有键值随机删除,这两个除了随机删除的范围不一样,其余差不多类似,因为随机选择并不会根据过期时间,键值访问次数选择,所以对缓存污染这种场景帮助并不是很大。
volatile-ttl
volatile-ttl指在设置过期时间的键值中选择快要过期的,也就是选择存活时间最短的键值淘汰,但存活时间并不能反应访问数据的频率,不过有一种情况,例如商品秒杀时间为半小时,那么商品信息可以预热放入缓存中有效期为半小时,半小时后将不会再访问缓存中的商品数据,这时淘汰是可以避免内存污染的,除此之外或多或少避免不了缓存污染。
allkeys-lru和volatile-lru
volatile-lru和allkeys-lru除取值范围不同外都采用LRU算法,全称Least Recently Used,筛选最近最少使用的键值,这种算法需要维护一个访问顺序链表,MRU端表示最近使用的键值,LRU端表示最近使用最少的键值。
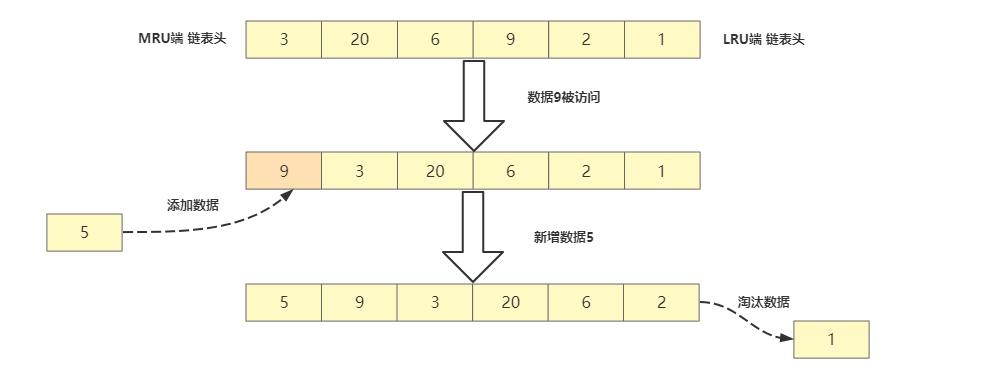
但这种算法有个弊端就是消耗内存,需要另外维护一个链表而且数据移动也会带来性能的消耗,所以Redis将原本的LRU算法进行了改进,在Redis中的每个键值都会去维护一个叫RedisObject的数据结构其中元数据中就记录了lru字段。
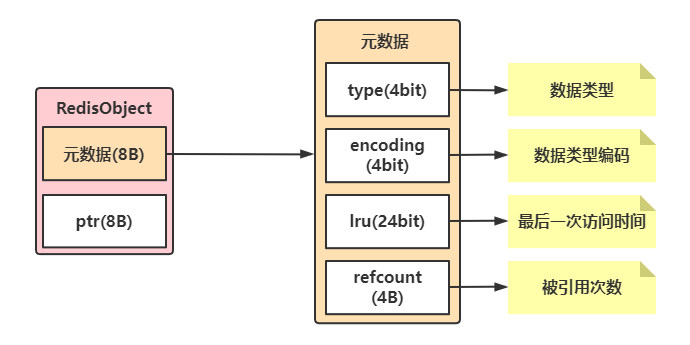
Redis默认会记录每个键值的最后一次访问时间的时间戳,也就是RedisObject中元数据的lru字段,当Redis准备淘汰数据时,第一次默认随机选出N个数据,将这N个数据作为一个候选集,然后比较N个数据中的lru字段,选择最小的淘汰出去。
当需要再次淘汰时,Redis需要挑选比候选集中最小的lru还小的键值,当新的数据进入候选集后,如果候选集的个数达到N个后,才会将候选集中最小的lru淘汰。(这里挑选的可能不止一个,淘汰的也可能不止一个)这样做的好处是利用每次比较的历史结果,将全量比较变为局部比较。
这里的N值是可配置的,可以在redis.conf文件中通过maxmemory-samples字段配置。
在redis官网中有描述Redis优化的LRU算法优劣势,如下所示

redis采用LRU算法的确可以大幅度的提升淘汰的有效性,但LRU只关注最近使用时间,在少量数据访问其实没什么问题,但如果遇到了扫描式单次查询是根本无法解决缓存污染的,所谓扫描式单次查询指的是对大量数据进行一次全体读取,每个数据都会被查询,但是查询的次数唯一,这相当于将所有键值的rul值更新为最新了,这将影响LRU算法的淘汰效果,不能解决缓存污染问题,所以redis4.0基于这点推出LFU算法。
allkeys-lfu和volatile-lfu
lfu在lru的基础上增加了使用次数的统计,为每一个数据添加一个计数器,当使用LFU策略淘汰数据时,首先根据数据的访问次数筛选,把访问次数最小的淘汰,如果访问次数相同,再根据最近一次的访问时间淘汰数据。
这样就能解决扫描式单次查询带来的问题,单次扫描查询后计数器值不会再增加,那么可以根据lfu规则淘汰使用次数最少的数据,这样就能避免缓存污染问题。
LFU算法
LFU算法是在LRU算法的基础上进行的改进,并没有因为新增一个计数器而新增数据结构,仅将redisObject的元数据中占有24个bit位的lru分割为了两部分,前8个bit位用于存储数据的访问次数,后16个bit为存储访问时间戳。
注意点
前8个bit位存储的访问次数最多只有255,这样就确定了lfu并不会每访问键值一次就加一是存在一定规则的非线性递增计数器的方法。
后16个bit位存储的是时间戳,因为长度限制这个时间戳只能精确到分钟,并且超过45天就会轮回一次(2的16次方表示的最大值为65535,65535/60/24约等于45)
lfu_log_factor非线性递增
redis如何采用8个bit位记录每个键值的访问次数呢?首先采用该键值的当前引用数N乘以配置项lfu_log_factor的值+1,再取其倒数,得到一个值p,然后把这个值p和(0,1)内随机值r对比,只有p值大于r值时,计数器+1
// 取(0,1)的随机值
double r = (double)rand()/RAND_MAX;
// 省略超级多代码.......
// baseval当前键值的引用数,初始值并不是0,而是5由常量LFU_INIT_VAL赋值
// 避免因为刚刚加入缓存马上就被淘汰
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
除了当前键值的引用次数影响外,最主要的还是redis.conf配置的lfu_log_factor,那么这个值需要如何设置呢?官方给了我们数据参考https://redis.io/docs/manual/eviction/
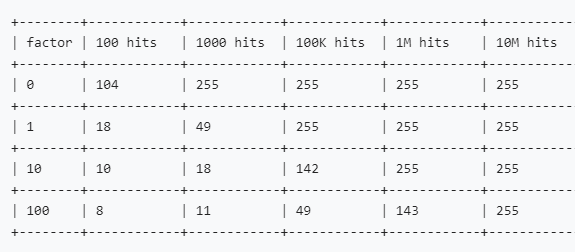
从上图我们可以看出lfu_log_factor的值越大,那么越容易区分大请求量的数据,但lfu_log_factor越大,访问次数增加的也就越慢,键值淘汰的几率就会增加,所以这需要根据请求量酌情选择,一般lfu_log_factor设置为10就够用了,能够区分10万请求的访问数据。
lfu_decay_time衰减机制
根据lfu的非线性递增的计数器方法确实能弥补lru的缺陷,但如果短期内存在大量键值的多次访问,这时访问次数相对还是大的,短时间内无法将键值淘汰出内存,这时还是存在缓存污染的问题,这就要说到lfu的另外一种衰减机制。
简单解释就是lfu利用衰减因子配置项lfu_decay_time,控制键值访问次数的衰减,lfu计算当前时间和最近一次访问时间的差值,转换为分钟,然后lfu算法将这个差值除上衰减因子lfu_decay_time的值,得到的结果就是访问数count需要衰减的值。
测试
除了看这些基本的概念外,我们还可以通过实操去真正了解淘汰策略
设置最大的内存,为了方便看出效果,我设置的尽可能的小(不能太小自测时将最大内存设置为20m最后命中率极低只有60%左右)
127.0.0.1:6379> config set maxmemory 50m ### 设置最大内存50m
OK
#### 也可以在redis.conf文件中修改,需要重启服务稍微有点麻烦
淘汰策略配置
127.0.0.1:6379> config set maxmemory-policy allkeys-lfu
OK
127.0.0.1:6379> CONFIG GET maxmemory-policy
1) "maxmemory-policy"
2) "allkeys-lfu"
模拟100万个请求
[root@zzf993 bin]# ./redis-cli --lru-test 1000000
#每秒执行Get的数量 命中次数,命中率 没有命中次数,没有命中率
168000 Gets/sec | Hits: 42706 (25.42%) | Misses: 125294 (74.58%)
143000 Gets/sec | Hits: 78923 (55.19%) | Misses: 64077 (44.81%)
…
150500 Gets/sec | Hits: 133414 (88.65%) | Misses: 17086 (11.35%)
170250 Gets/sec | Hits: 153961 (90.43%) | Misses: 16289 (9.57%)
…
147250 Gets/sec | Hits: 144298 (98.00%) | Misses: 2952 (2.00%)
137000 Gets/sec | Hits: 134462 (98.15%) | Misses: 2538 (1.85%)
一开始由于数据库中没有数据(测试前最好清空redis数据库),命中率自然低,随着时间的推移命中率变高
> 有兴趣可以查看`./redis-cli --help`,命令获取更多指令















 159
159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









