








最近一周AI科技圈又有啥新进展
谷歌发布Gemini 2.5 Pro,多项基准测试夺冠并支持200万tokens长上下文
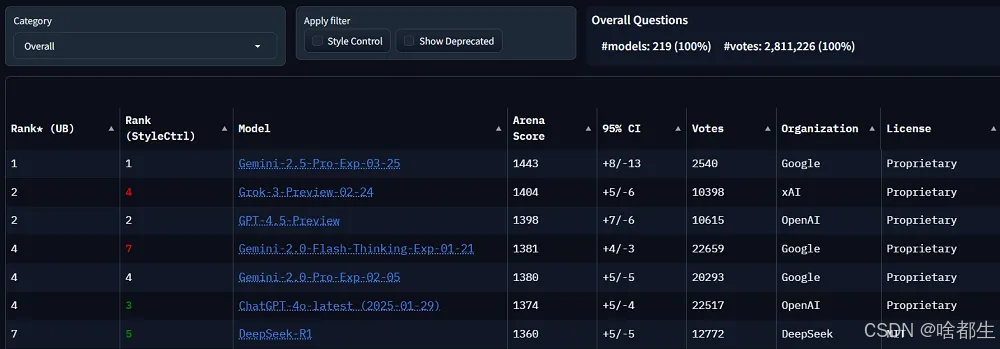
谷歌推出Gemini 2.5 Pro实验版本,该模型在大模型竞技场中以1443分的成绩领先,比第二名高出39分。在Humanity’s Last Exam测试中得分较OpenAI o3-mini提升近5%,提升比例达34%。此外,Gemini 2.5 Pro支持100万tokens上下文窗口,即将升级至200万tokens,还具备原生多模态处理能力,擅长创建美观的Web应用和智能体编程
https://mp.weixin.qq.com/s/U5AO2-oj84F726DZYIMUyQ
华为ModelEngine全流程AI开发工具链正式开源
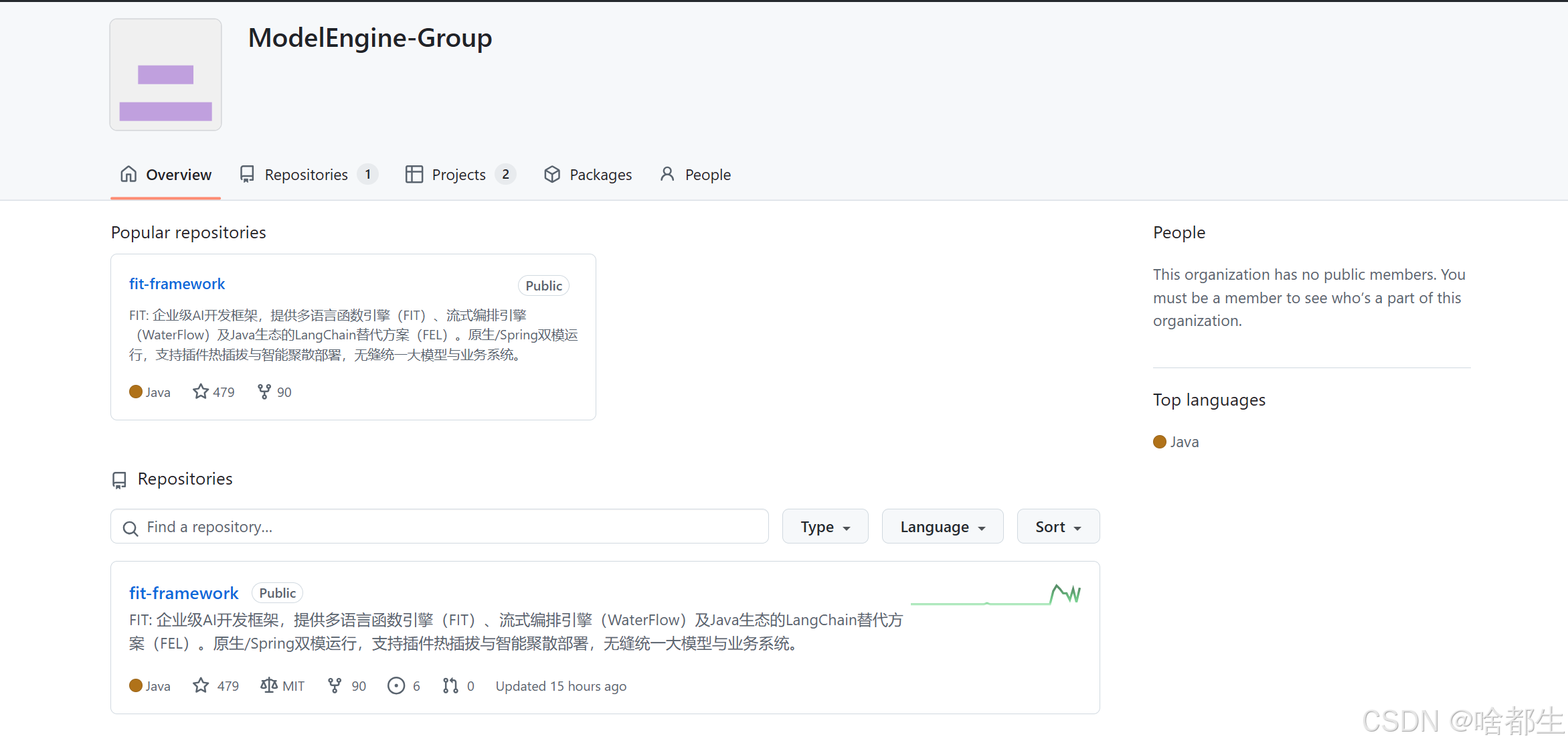
华为ModelEngine AI全流程工具链在全球开发者面前正式开源,旨在解决AI行业化落地中的数据工程耗时长、模型训练和应用落地难等问题。该工具链围绕数据使能、模型使能和应用使能打造,内置数据处理算子、完整模型管理流程,并提供低代码编排、RAG框架及自定义插件能力,助力缩短通用大模型基于行业私域数据训练成行业大模型并开发成AI应用的整体周期。代码已托管在GitCode、Gitee和GitHub等平台
https://github.com/ModelEngine-Group
OpenAI 推出 GPT-4o 原生图像生成功能,挑战谷歌 Gemini 2.5 Pro
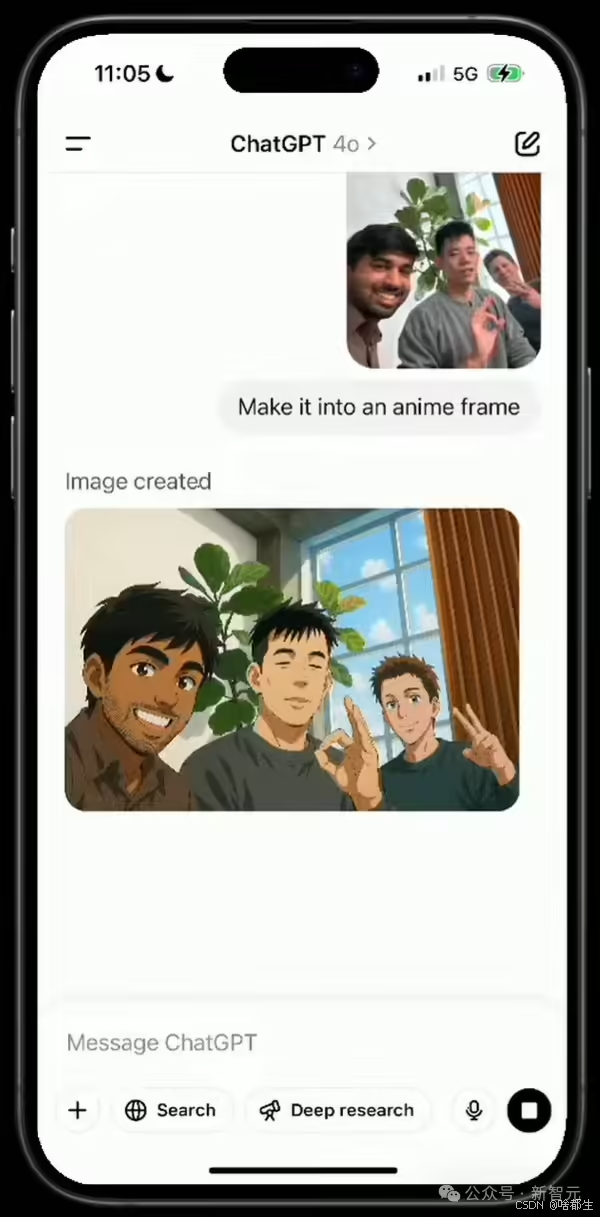
OpenAI 在直播中展示了 GPT-4o 的图像生成技术升级,包括梗图制作、文本渲染、多轮交互生成等功能。GPT-4o 能够处理多达 10-20 个物体的复杂图像生成任务,支持多种风格转换,并且可以精准遵循用户提示,生成实用且具有上下文感知能力的图像。该功能已向 ChatGPT 和 Sora 的所有用户开放
https://www.ithome.com/0/840/746.htm
OpenAI 发布新一代音频模型,涵盖语音转文本与文本转语音功能
OpenAI 推出新一代音频模型,包括 gpt-4o-transcribe(语音转文本)、gpt-4o-mini-transcribe(语音转文本精简版)和 gpt-4o-mini-tts(文本转语音)。其中,gpt-4o-transcribe 单词错误率显著降低,优于现有 Whisper 模型;gpt-4o-mini-transcribe 速度更快、效率更高;gpt-4o-mini-tts 首次支持「可引导性」,开发者可控制语音风格。三款模型定价分别为每分钟 0.006 美元、0.003 美元和 0.015 美元。OpenAI 还推出 Agents SDK 集成,简化开发流程,并举办广播比赛,鼓励用户创作和分享音频

https://mp.weixin.qq.com/s/fab8tYA_Xse5kL6v6uCF0A
阿里推出视觉推理模型QVQ-Max,可分析推理图片视频并助力多场景应用
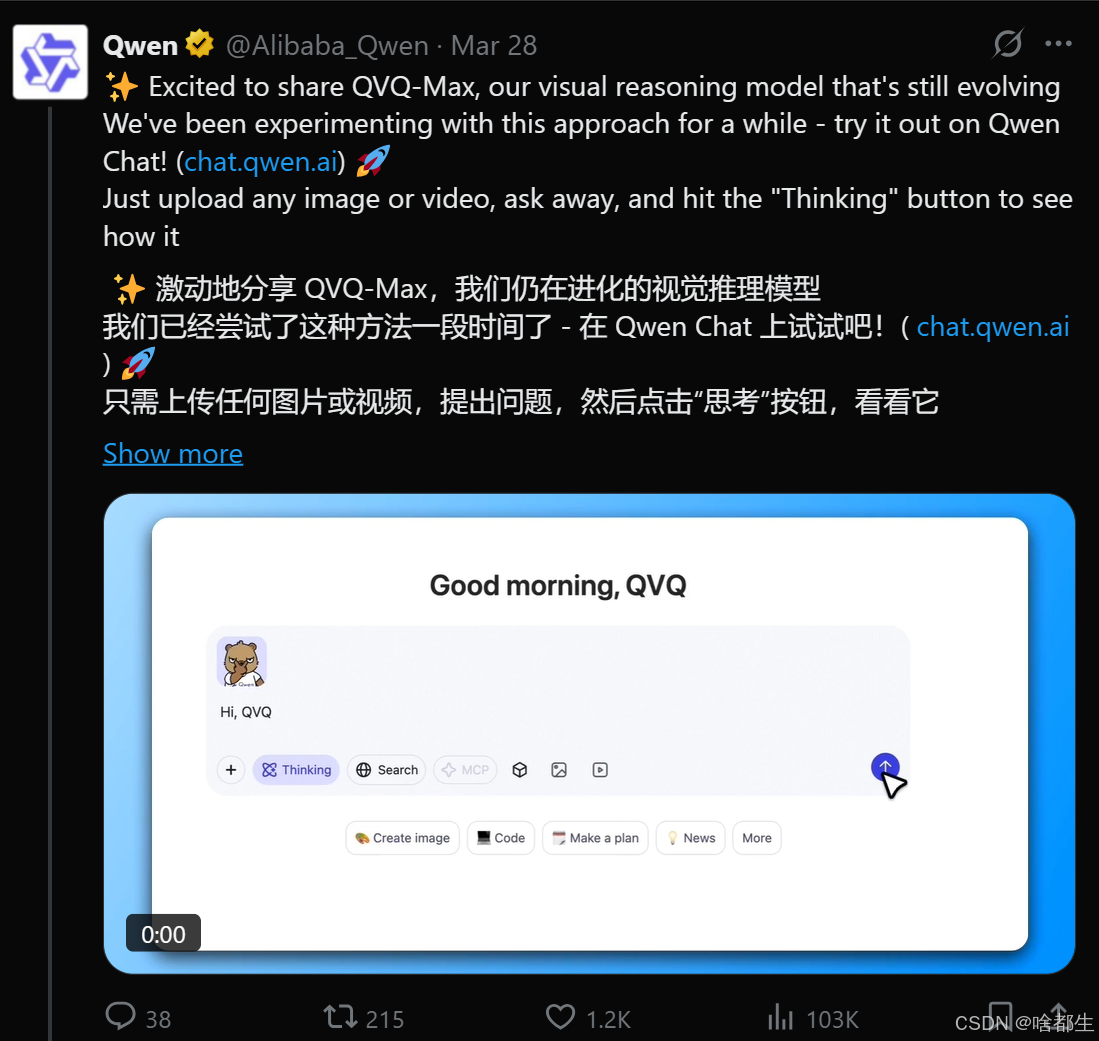
阿里通义千问团队发布新一代视觉推理模型QVQ-Max,具备细致观察、深入推理和灵活应用三大核心能力。它能快速识别图片和视频中的关键元素,结合背景知识进行分析推理,还能设计插画、生成短视频脚本等。该模型已上线Qwen Chat,用户上传图片或视频并提问即可使用其推理能力,未来还将持续优化和扩展功能
https://qwenlm.github.io/blog/qvq-max-preview/
阿里云Qwen2.5-Omni开源,7B全模态模型性能全球领先
阿里云正式开源通义千问Qwen2.5-Omni-7B,这是通义系列首个端到端全模态大模型,可处理文本、图像、音频和视频等多种输入,并实时生成文本与语音输出。该模型在OmniBench等权威测评中刷新纪录,性能远超Google的Gemini-1.5-Pro等同类模型。Qwen2.5-Omni采用创新的Thinker-Talker双核架构及多项新技术,支持多模态输入与流式处理,语音生成测评分数达4.51,与人类持平。其7B的小尺寸使其在产业应用中更具优势,可在手机等终端轻松部署。目前,该模型已在魔搭社区和Hugging Face开源,用户可免费下载商用并体验
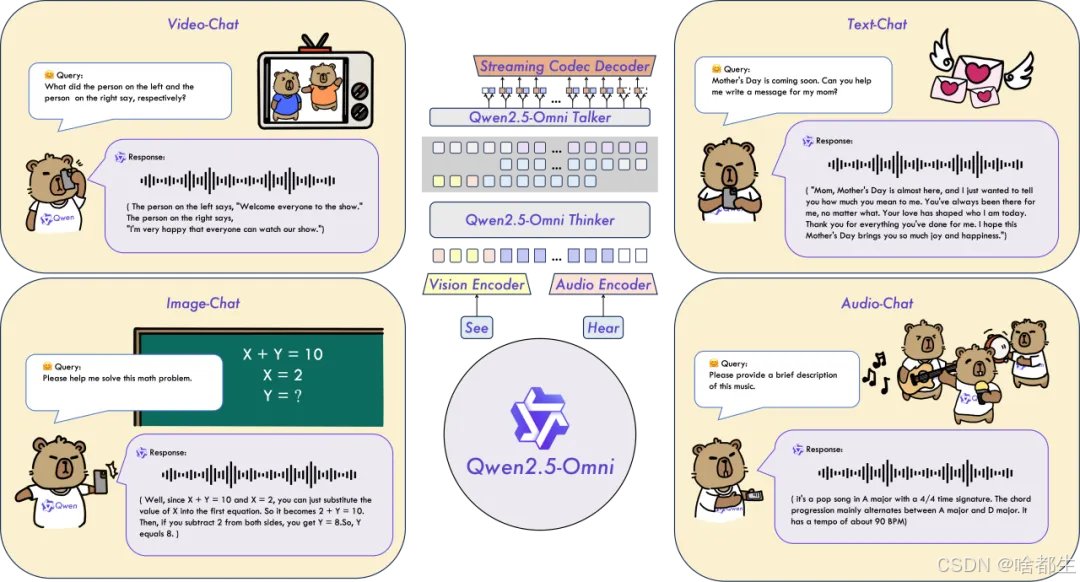
https://github.com/QwenLM/Qwen2.5-Omni
豆包新版深度思考功能开启测试,支持边想边搜
豆包新版深度思考功能正式开启测试,其核心亮点在于将推理过程与搜索深度相结合,支持边思考边搜索。在制定方案和规划时,豆包可通过多轮搜索完善结果;在辅助专业文章写作中,可深度挖掘资料并提供创新思路;在模糊条件搜索时,能精准锁定目标答案
https://mp.weixin.qq.com/s/GmLjK5Zl0-xWUCzqKTrLGg
昆仑万维发布全球首款音乐推理大模型Mureka O1
昆仑万维正式发布Mureka O1和Mureka V6两款AI音乐模型,其中Mureka O1为全球首款音乐推理大模型,采用自研MusiCoT技术,性能超越Suno,登顶SOTA。Mureka V6支持10种语言的音乐创作,并引入ICL技术优化声场与混音设计。两款模型支持多种音乐风格与情感表达,并提供歌曲参考和音色克隆功能,用户可上传音频或音色进行创作。此外,Mureka还开放API服务与模型微调功能,助力开发者构建AI音乐生态
https://mp.weixin.qq.com/s/1JPYXUwX-1JAVpz3IgygtQ
美团开发内部大模型 LongCat,AI 策略聚焦主动进攻
美团 CEO 王兴在财报电话会议中表示,美团已开发内部大语言模型 LongCat,并将其应用于日常工作,推出 AI 编码、智能会议与文档助手等工具。美团的 AI 策略为“主动进攻”,计划推出原生人工智能产品,并持续投资打造内部大模型。2024 年,美团收入达 3375.92 亿元,同比增长 22%,核心本地商业分部收入同比增长 20.9%,到店业务订单量同比增长超 65%
https://www.ithome.com/0/840/222.htm
腾讯发布自研深度思考模型混元T1,推理能力显著提升
腾讯正式推出自研深度思考模型混元T1正式版,该模型在推理能力上表现出色,尤其擅长超长文处理。在多项基准测试中,混元T1取得优异成绩,如在MMLU-PRO中得分87.2分,仅次于o1。其采用的Hybrid-Mamba-Transformer融合架构,有效降低了计算复杂度和内存占用,同时针对长序列处理进行了优化,解码速度提升2倍。混元T1已上线腾讯云,企业用户可通过官网申请试用
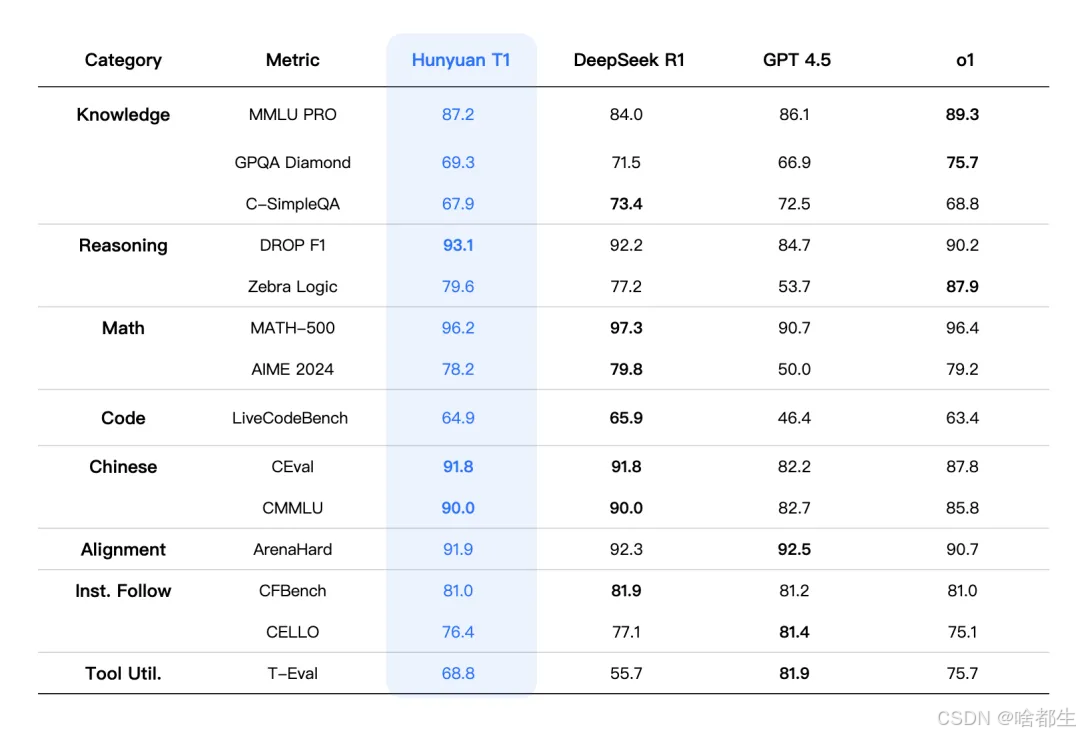
https://llm.hunyuan.tencent.com/#/chat/hy-t1
vivo进军机器人领域,聚焦家庭消费级产品
vivo在博鳌亚洲论坛2025年年会上宣布成立“vivo机器人Lab”,正式进军机器人行业。vivo计划利用其在AI大模型、影像技术及混合现实领域的积累,着重研究机器人的“大脑”和“眼睛”,目标是打造面向个人和家庭场景的消费级机器人产品。据预测,到2028年我国机器人整机市场规模约在20至50亿元,2035年规模可达约500亿元,2045年后人形机器人整机市场规模有望达到约10万亿元级别
https://mp.weixin.qq.com/s/a7-Sch6mpOSvg6kQTAXfuw



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











