







深度学习是新兴的机 器学习研究领域,旨在研究如何从数据中自动地提取多层特征 表示,其核心思想是通过数据驱动的方式,采用一系列的非线 性变换,从原始数据中提取由低层到高层、由具体到抽象、由一 般到特定语义的特征。
1 深度学习相关应用领域
1. 1 图像识别
物体检测和图像分类是图像识别的两个核心问题,图像识别是深度学习最早尝试的 应用领域,早在 1989 年,LeCun 等人
发表了关于卷积神经网 络的相关工作,在手写数字识别任务上取得了当时世界上最好 的结果,并广泛应用于各大银行支票的手写数字识别任务中。 百度在 2012 年将深度学习技术成功应用于自然图像 OCR 识 别和人脸识别等问题上,并推出相应的移动搜索产品和桌面应 用。从 2012 年的 ImageNet 竞赛开始,深度学习在图像识别领 域发挥出巨大威力,在通用图像分类、图像检测、光学字符识别 (optical character recognition,OCR)、人脸识别等领域,最好的 系统都是基于深度学习的。图 1 为 2010—2016 年ImageNet 竞 赛的识别错误率变化及人的识别错误率。2012 年是深度学习 技术第一次被应用到 ImageNet 竞赛中,可以看出相对于 2011 年传统最好的识别错误率大幅降低了 41. 1% ,且 2015 年基于 深度学习技术的图像识别错误率已经超过了人类,2016 年最新的 ImageNet 识别错误率已经达到 2. 991% 。
1. 2 语音识别
语 音 识 别( automatic speech recognition,ASR)是指能够让计算机自动地识别语音中所携带 信息的技术。在语音识别领域,深度神经网 络(deep neural network,DNN) 模型给处在瓶颈阶段的传统 GMM-HMM 模型带来了巨大的革新,使得语音识别的准确率又 上了一个新的台阶。目前国内外知名互联网企业(谷歌、科大 讯飞及百度等)的语音识别算法采用的都是 DNN 方法。国内科大讯飞提出的前馈型序列记忆网络( feed-for- ward sequential memory network,FSMN) 语音识别系统,使用大 量的卷积层直接对整句语音信号进行建模,更好地表达了语音 的长时相关性,其效果比学术界和工业界最好的双向 RNN( re- current neural network)语音识别系统识别率提升了 15% 以上。 由此可见,深度学习技术对语言识别率的提高有着不可忽略的 贡献。
1. 3 自然语言处理
自然语言处理(natural language processing,NLP)也是深度 学习的一个重要应用领域,经过几十年的发展,基于统计的模 型已成为 NLP 的主流,同时人工神经网络在 NLP 领域也受到 了理论界的足够重视。世界 上最早的深度学习用于 NLP 的研究工作诞生 于 NEC Labs American,其研究员 Collobert 等人从 2008 年开始采用 embedding 和多层一维卷积的结构,用于词性标注、分块、命名实 体识别、语义角色标注等四个典型 NLP 问题。此外,基于深度学习模型的特征学习还 在语义消歧、情感分析等自然语言处理任务中均超越了 当时最优系统,取得了优异表现。
2 深度学习常用模型
2. 1 自动编码机
自动编/解码网络可看做是传统的多层感知器的变种,其基本想法是将输入信号经过多层神经网络后重构原始的输入,通过非监督学习的方式挖掘输入信号 的潜在结构,将中间层的响应作为潜在的特征表示。
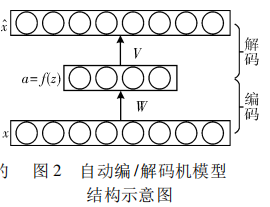
自动编/解码机由将输入信号映射到低维空间的编码机和 用隐含特征重构初始输入的解码机构成。假设输入信号为 x, 编码层首先将其线性映射为 z,然后再施加某种非线性变换, 这一过程可以形式化为 a = f(z) = f(Wx + b) 其中: f (·)为某种非线性函数,常用的有 sigmoid 函数 f( z) = 1 /(1 + exp(- z))和修正线性单元( rectified linear unit,ReLU) 函数 f(z) = max(0,z),也称为激活函数。
2. 2 受限玻尔兹曼机
玻尔兹曼机(Boltzmann machine,BM) 是一种随机的递归 神经网络,由 Hinton 等人提出,是能通过学习数据固有 内在表示、解决复杂学习问题最早的人工神经网络之一,受限 玻尔兹曼机(restricted Boltzmann machine,RBM)是玻尔兹曼机 的扩展,由于去掉了玻尔兹曼机同层之间的连接,所以大大提 高了学习效率。
2. 3 深度神经网络
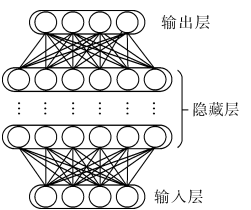
神经网络技术起源于 20 世纪 50、60 年代,当时叫做感知 机,是最早被设计并实现的人工神经网络,是一种二分类的线 性分类模型,主要用于线性分类且分类能力十分有限。输入的 特征向量通过隐含层变换达到输出层,在输出层得到分类结 果。早期感知机的推动者是 Rosenblatt,但是单层感知机遇到 一个严重的问题,即它对稍复杂一些的函数都无能为力(如最 为典型的异或操作)。随着数学理论的发展,这个缺点直到 20 世纪 80 年代才被 Rumelhart、Williams、Hinton、LeCun 等人发明 的多层感知机(multilayer perceptron,MLP) 克服。多层感知机 可以摆脱早期离散传输函数的束缚,使用 sigmoid 或 tanh 等连 续函数模拟神经元对激励的响应,在训练算法上则使用 Werbos 发明的反向传播 BP 算法。
通过增加隐含 层的数量及相应的节点数,可以形成深度神经网络。深度神经 网络一般指全连接的神经网络,该类神经网络模型常用于图像 及语言识别等领域,在图像识别领域由于其将图像数据变成一 维数据进行处理,忽略了图像的空间几何关系,所以其在图像 识别领域的识别率不及卷积神经网络,且由于相邻层之间全连 接,其要训练的参数规模巨大,所以巨大的参数量也进一步限制了全连接神经网络模型结构的深度和广度。
2. 4 卷积神经网络
近几年,卷积神经网络在大规模图像特征表示和分类中取 得了很大的成功。标志性事件是在 2012 年的 ImageNet 大规模
视觉识别挑战竞赛中,Krizhevsky 实现的深度卷积神经网络 模型将图像分类的错误率降低了近 50%。2016 年 4 月著 名的围棋人机大战中以 4 ∶ 1大比分优势战胜李世石的 AlphaGo 人工智能围棋程序就采用了 CNN + 蒙特卡洛搜索树算法。卷 积神经网络最早是由 LeCun 等人在 1998 年提出,用于手写字 符图像的识别
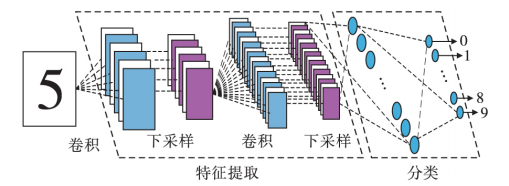
该网络的输入为原始二维图像,经过若干卷积层和全连接 层后,输出图像在各类别下的预测概率。每个卷积层包含卷积、非线性激活函数和最大值池化三种运算。在卷积神经网络中,需要学习一组二维滤波模板 F = f1,…,fNk,与输入特征图 x 进行卷积操作,得到 Nk 个二维特征图 zk = fk * x。采用卷积运算的好处有如下几点:a)二维卷积模板可以更好地挖掘相邻像素之间的局部关系和图像的二维结构;b) 与一般神经网络中的全连接结构相比,卷积网络通过权重共享极大地减少了网络的参数量,使得训练大规模网络变得可行;c)卷积操作对图像上的平移、旋转和尺度等变换具有一定的鲁棒性。得到卷积响应特征图后,通常需要经过一个非线性激活函数来得到激活响应图,如 sigmoid、tanh 和 ReLU 等函数。紧接着,在激活函数响应图上施加一个最大值池化(max pooling)或者平均值池化(average pooling)运算。在这一操作中,首先用均匀的网格将特征图划分为若干空间区域,这些区域可以有重叠部分,然后取每个图像区域的平均值或最大值作为输出。此外在最大值池化中,通常还需要记录所输出最大值的位置。已有研究工作证明了最大值池化操作在图像特征提取中的性能优于平均值池化,因而近些年研究者基本都采用了最大值池化。池化操作主要有如下两个优点:a) 增强了网络对伸缩、平移、旋转等图像变换的鲁棒性;b)使得高层网络可以在更大尺度下学 习图像的更高层结构,同时降低了网络参数,使得大规模的网络训练变得可行。由于卷积神经网络的参数量较大,很容易发 生过拟合,影响最终的测试性能。研究者为克服这一问题提出 了很多改进的方法。Hinton 等人提出了称为“dropout”的优 化技术,通过在每次训练迭代中随机忽略一半的特征点来防止过拟合,取得了一定的效果;Wan 等人进一步扩展了这一想法,在全连接层的训练中,每一次迭代时从网络的连接权重中随机挑选的一个子集置为 0,使得每次网络更新针对不一样的网络结构,进一步提升了模型的泛化性。此外还有一些简单有效的工程技巧,如动量法、权重衰变和数据增强等。
2. 5 循环神经网络
在全连接的 DNN 和 CNN 中,每层神经元的信号只能向上 一层传播,样本的处理在各个时刻相互独立,因此该类神经网络无法对时间序列上的变化进行建模,如样本出现的时间顺序对于自然语言处理、语音识别、手写体识别等应用非常重要。为了适应这种需求,就出现了另一种神经网络结构———循环神经网络(RNN)。RNN 中神经元的输出可以在下一个时间戳直接作用到自身,即第 i 层神经元在 t 时刻的输入,除了(i - 1)层神经元在 t - 1 时刻的输出外,还包括其自身在 t 时刻的输入。
为了适应不同的应用需求,RNN 模型出现了不同的变种, 主要包括以下几种:
a)长短 期 记 忆 模 型
b)Simples RNN(SRN)
c)Bidirectional RNN
此外针对不同的应用需求还出现了一些包括深度 RNN 模型(deep RNN)回声状态网络( echo state networks)、门控 RNN 模型( gated recurrent unit,GRU)、时钟频率驱动的RNN(clockwork RNN)模型等。
2. 6 多模型融合的神经网络
除了单个的神经网络模型,还出现了不同神经网络模型组合的神经网络,如 CNN 和 RBM、CNN 和 RNN 等,通过将各个 网络模型的优势组合起来可以达到最优的效果。将 CNN 与 RNN 相结合用于对图像描述的自动生成,使得该组合模型能够根据图像的特征生成文字描述或者根据文字产生相应内容的图片。随着深度学习技术的发展,相信会有越来越多性能优异的神经网络模型出现在大众的视野,如近期火热的生成对抗网络( generative adversarial networks,GAN) 及相应变种 模型为无监督学习的研究开启了一扇门窗。
3 基于深度学习的优化方法
3. 1 数据并行
当训练的模型规模比较大时,可以通过数据并行的方法来加速模型的训练,数据并行可以对训练数据做切分,同时采用多个模型实例对多个分块的数据同时进行训练。数据并行的大致框架如图 10 所示。在训练过程中,由于数据并行需要进行训练参数的交换,通常需要一个参数服务器,多个训练过程相互独立,每个训练的结果,即模型的变化量 ΔW 需要提交给参数服务器,参数服务器负责更新最新的模型参数 W' = W - η × ΔW,之后再将最新的模型参数 W'广播至每个训练过程,以便各个训练过程可以从同一起点开始训练。在数据并行的实现中,由于是采用同样的模型、不同的数据进行训练,影响模型性能的瓶颈在于多 CPU 或多 GPU 间的参数交换。根据参数更新公式,需要将所有模型计算出的梯度提交到参数服务器并更新到相应参数上,所以数据片的划分以及与参数服务器的带宽可能会成为限制数据并行效率的瓶颈。
3. 2 模型并行
除了数据并行,还可以采用模型并行的方式来加速模型的训练。模型并行是指将大的模型拆分成几个分片,由若干个训练单元分别持有,各个训练单元相互协作共同完成大模型的训练。一般来说,模型并行带来的通信和同步开销多于数据并行,因此其加速比不及数据并行,但对于单机内存无法容纳的大模型来说,模型并行也是一个很好的方法,2012 年 ImageNet 冠军模型Axlenet 就是采用两块 GPU 卡进行模型并行训练。
4 深度学习常用软件工具及平台
4. 1 常用软件工具
a)TensorFlow,它由 Google 基于 DistBelief 进行研发的第二 代人工智能系统。
b)以 Keras 为主的深度学习抽象化平台。其本身不具有底层运算协调能力,而是依托于 TensorFlow 或 Theano 进行底层运算,Keras 提供神经网络模块抽象化和训练中的流程优化,可以让用户在快速建模的同时,具有很方便的二次开发能力,加入自己喜欢的模块。
c)以 Caffe、Torch、MXNet、CNTK 为主的深度学习功能性平台。
d)Theano,它是深度学习领域最早的软件平台,专注于底层基本运算。该平台有以下几个特点:
(a)集成 NumPy 的基于Python 实现的科学计算包,可以与稀疏矩阵运算包 SciPy 配合使用,全面兼容 NumPy 库函数;
( b)易于使用 GPU 进行加速,具有比 CPU 实现相对较大的加速比;
(c)具有优异可靠性和速度优势;
(d)可支持动态 C 程序生成;
(e) 拥有测试和自检单元,可方便检测和诊断多类型错误。
4. 2 工业界平台
a)DistBelief 是由 Google 用 CPU 集群实现的数据并行和模型并行框架,该集群可使用上万 CPU core 训练多达 10 亿参数的深度网络模型,可用于语音识别和 2. 1 万类目的的图像分类。
b)Facebook 实现了多 GPU 训练深度卷积神经网络的并行框架,结合数据并行和模型并行的方式来训练卷积神经网络模 型,使用 4 张 NVIDIA TITAN GPU 可在数天内训练 ImageNet1 000分类的网络。
c)Paddle( parallel asynchonous distributed deep learning)是由国内的百度公司搭建的多机 GPU 训练平台,其将数据放置于不同的机器,通过参数服务器协调各机器的训练,Paddle平台也可以支持数据并行和模型并行。
d)腾讯为加速深度学习模型训练也开发了并行化平台———Mariana,其包含深度神经网络训练的多 GPU 数据并行框架、深度卷积神经网络的多 GPU 模型并行和数据并行框架,以及深度神经网络的 CPU 集群框架。该平台基于特定应用的训练场景,设计定制化的并行训练平台,用于语音识别、图像识别以及在广告推荐中的应用。
通过对以上几种工业界平台的介绍可以发现,不管是基于CPU 集群的 DistBelief 平台还是基于多 GPU 的 Paddle 或 Mariana平台,针对大规模神经网络模型的训练基本上都是采用基于模型的并行方案或基于数据的并行方案,或是同时采用两种并行方案。由于神经网络模型在前向传播及反向传播计算过程存在一定的数据相关性,当前其在大规模 CPU 集群或者GPU 集群上训练的方法并不多。
5 深度学习相关加速技术
1 CPU 加速技术
2GPU 加速技术
3FPGA 加速技术
6 存在问题与研究展望
尽管深度学习技术在图像处理、语音识别、自然语言处理等领域取得了突破性的进展,但仍有许多问题亟待解决。
a)无监督数据的特征学习。当前,标签数据的特征学习仍然占据主导地位,而真实世界存在着海量的无标签数据,将这些无标签数据逐一添加人工标签,显然是不现实的。因此,随着深度学习技术的发展,必将越来越重视对无标签数据的特征学习,以及将无标签数据进行自动添加标签技术的研究。
b)基于模型融合的深度学习方法。相关研究表明,单一的深度学习模型往往不能带来最好的效果,而通过增加深度来提高模型效果的方法会有一定的局限性,如梯度消失问题、计算过于复杂、模型的并行性有限等问题,因此通过融合其他模型或者多种简单模型进行平均打分,可能会带来更好的效果。
c)迁移学习。迁移学习可以说是一种“站在巨人肩上”的学习方法,可以在不同领域中进行知识迁移,使得在一个领域中已有的知识得到充分的利用,无须每次都将求解问题视为全新的问题。一个好的迁移学习方法可以大大加快模型的训练速度。
d)嵌入式设备。目前深度学习技术正往嵌入式设备靠近,即原来的训练往往在服务器或者云端,而嵌入式设备通过网络将待识别的任务上传至云端,再由云端将处理结果发送到嵌入式端。随着嵌入式设备计算能力的提升、新型存储技术以及储电技术的进步,在嵌入式端完成实时训练是完全可能的,到时就可能实现真正的人工智能。因此,嵌入式设备成为将来的研究重点,包括军/民用无人机、无人车/战车、无人潜水器等智能化装备。
e)低功耗设计。鉴于嵌入式设备对功耗非常敏感,具有功耗优势的 FPGA 芯片可能成为研究的一个热点,设计基于FPGA 类似 Caffe 的可编程深度学习软件平台会是一个研究方向。
f)算法层优化。由于深度学习技术巨大的计算量和存储需求,不仅要在硬件上进行加速,算法模型优化上也可以锦上添花,如稀疏编码、层级融合、深度压缩等相关技术也会继续研究。
g)脉冲神经网络。脉冲神经网络目前虽然在精度上并不具有与机器学习算法一样的水准,一方面因为学习算法,另一方面因为信息编码,然而脉冲神经网络是更接近生物学现象和观察的模型。未来在脉冲神经网络研究上的突破也是人工智能研究上的一个重点。
h)非精确计算。鉴于神经网络模型对计算精度不是特别敏感,因此非精确计算越来越引人瞩目,被认为是降低能耗最有效的手段之一。通过牺牲可接受的实验精度来换取明显的资源节约(能耗、关键路径延迟、面积),可以将非精确计算和硬件神经网络相结合来扩大应用范围、提高错误恢复能力和提高能源节约程度,使得该神经网络成为未来异构多核平台的热门备选加速器。
i)模型压缩。深度学习仍在不断进步,目前网络的规模开始朝着更深但是参数更少的方向发展,如微软提出的深度残差网络和 Standford 提出的稀疏神经网络,该研究体现了深度神经网络中存在参数的冗余性。可以预见未来的算法研究会进一步压缩冗余参数的存在空间,从而网络可能具有更好的精度但是却拥有更少的参数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









