







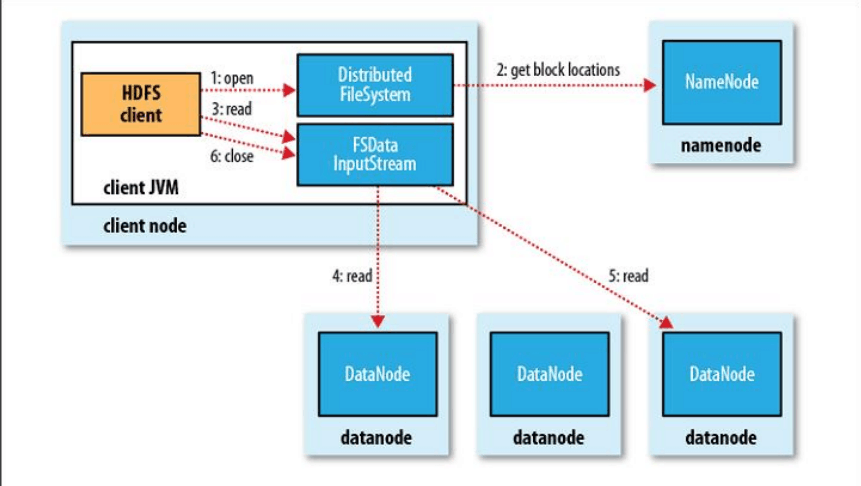
HDFS的读操作
1.通过客户端发出open的命令,给分布式文件系统
2.分布式文件系统再从namenode上获得所要读取的文件的block的位置。
3.客户端向FSDataInputStream发送读的命令。
4.Datanode将所有的block块拼接起来发送给FSDataInputStream使客户看到完整的文件而不是分割成的一块一块的文件。(4,5一个操作)
6.关闭FSDataInputStream 通道。
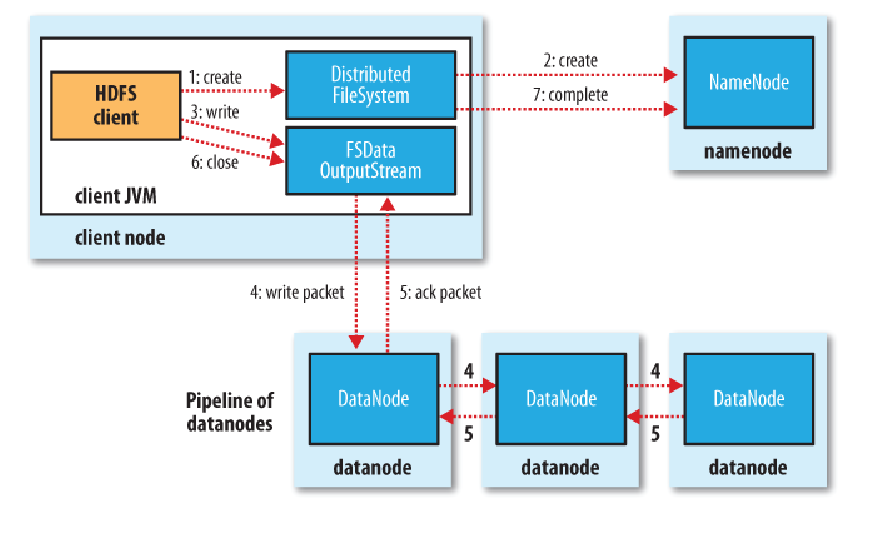
HDFS的写操作
1.通过客户端发送创建命令给分布式文件系统
2.文件系统发送给namenode询问是否可以创建文件。
3.可以的话客户端发送写的命令,给FSDataInputStream
4.向Datanode写入文件,写完一个block之后在写下一个(流水线式的)并且同时也在复制文件副本。
5.都完成后返回信息给FSDataInputStream
6.关闭FSDataInputStream(关闭流)
这里对读写操作的解释比我的要好,大家可以看看
http://www.aboutyun.com/thread-6779-1-1.html
HDFS2.0
1.NameNode HA:
有两个namenode 一个处于active状态,一个处于standby状态 两者都是从Journanode中存放数据,来保证数据的一致性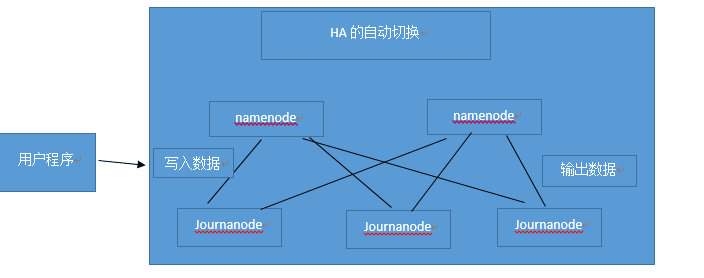
2.NameNode Federation(联邦):两个namenode分别管理不同的目录,两者无交叉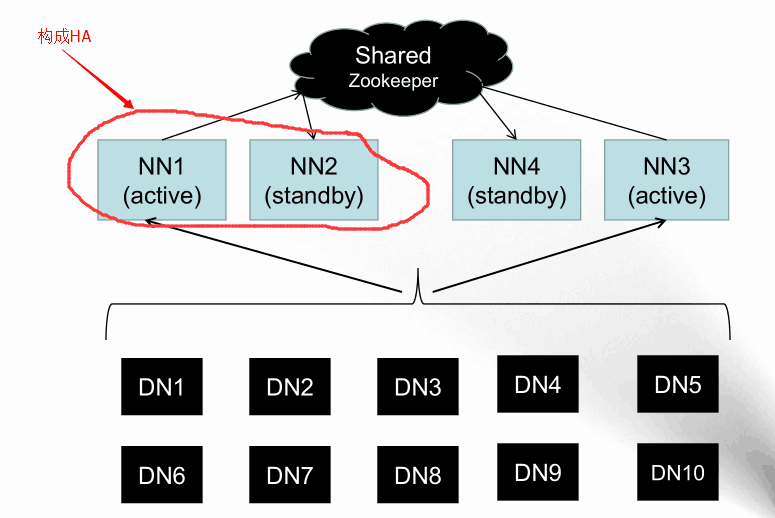
3.HDFS快照
1.数据的备份,防止误操作
2.记录某一时刻的数据
4.HDFS缓存
目的:
1.防止内存资源浪费
2.能够与其他框架共享内存资源
实现
1.可通过命令对一级文件进行加入和移除操作(有局限不能针对到块,不能自动缓存)
2.可设置缓存失效时间
3.独立管理未与Yarn集成在一起(可自设置缓存大小)
4.以pool的形式组织缓存(自己不太清楚)
5.HDFS ACL :权限管理(对文件权限的补充)
6.异构层级存储结构
背景
1.HDFS将文件抽象成统一的Disk
2.一个集群中存储的介质繁多
多种任务需同时运行在hadoop集群上(不同性能要求的数据可存储在不同的介质上 )
实现 :
1.HDFS仅提供异构的存储结构性能未知
2.提供API,控制数据的写入介质存储
3.提供管理工具控制各种介质的使用大小
参考:小象学院hadoop教程 董西成
http://dongxicheng.org/















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









