








为什么不让用keys
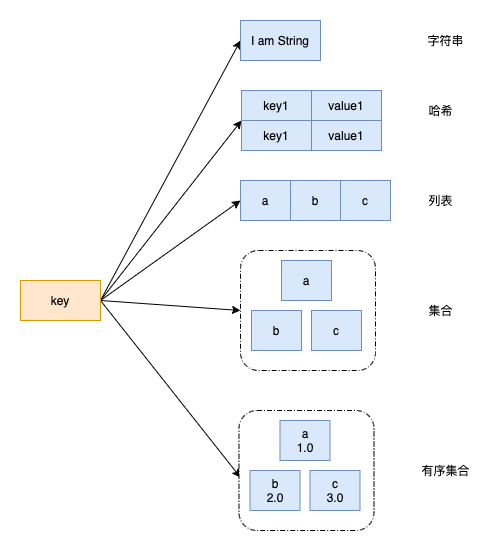
我们都知道Redis其实就是一个大map,而使用keys的时候会遍历这个map中所有key并返回符合条件的key
// 返回所有的key
keys *
// 返回以test为前缀的key
keys test*
这个命令有很明显的缺点,一次性返回所有符合条件的key,会造成Redis服务卡顿。因为Redis是单线程的程序,顺序执行命令,其他命令必须等到当前keys指令执行完毕才能继续
所以一般情况下keys*命令是禁止使用的
使用scan要小心
为了解决keys的问题,Redis在后续的版本中提供了scan命令及其相关的命令
SCAN遍历数据库中的键
SSCAN遍历set中的键
HSCAN遍历hash中的键
ZSCAN遍历zset中的键盘(包括元素成员和元素分值)。
scan相关的命令使用格式如下
SCAN cursor [MATCH pattern] [COUNT count]
127.0.0.1:6379> scan 0 match testKey* count 2
1) "1"
2) 1) "testKey4"
2) "testKey1"
3) "testKey2"
4) "testKey3"
127.0.0.1:6379> scan 1 match testKey* count 2
1) "13"
2) 1) "testKey5"
2) "testKey"
127.0.0.1:6379> scan 13 match testKey* count 2
1) "15"
2) 1) "testKey6"
127.0.0.1:6379> scan 15 match testKey* count 2
1) "0"
2) (empty list or set)
当我们用scan遍历的时候,先指定游标为0,然后查询结果中会返回下次遍历需要传入的游标。直到最后返回的游标为0,才能判断已经遍历完毕。
注意返回结果为空时,并不表明遍历结束,只有当返回的游标为0时才能表明遍历结束
另外还有一个注意的点是,count参数只能大概用来控制返回的结果,返回的数量并不严格按照count,有可能比count多,也有可能比count少,上面的demo就是一个很明显的例子,为什么会这样呢?我们后续来分析
scan系的命令最终都调用了同一个方法,所以他们的实现逻辑是一样的,只不过遍历的对象有所差别。
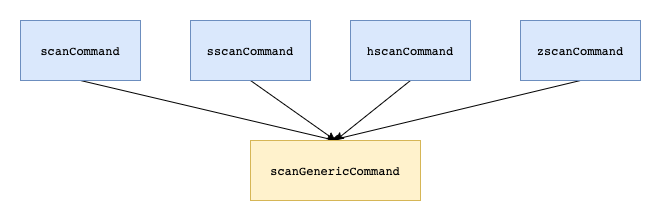
当数据的encoding为ziplist,intset时,会直接返回所有的数据(因为ziplist,intset存储的元素比较少)
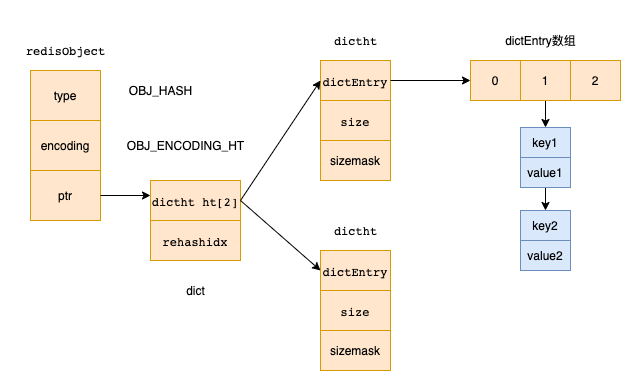
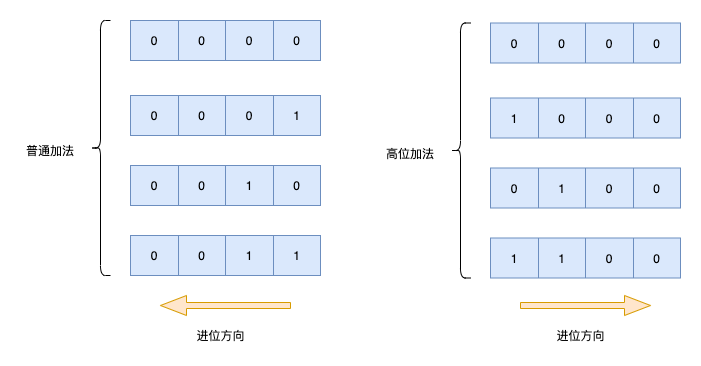
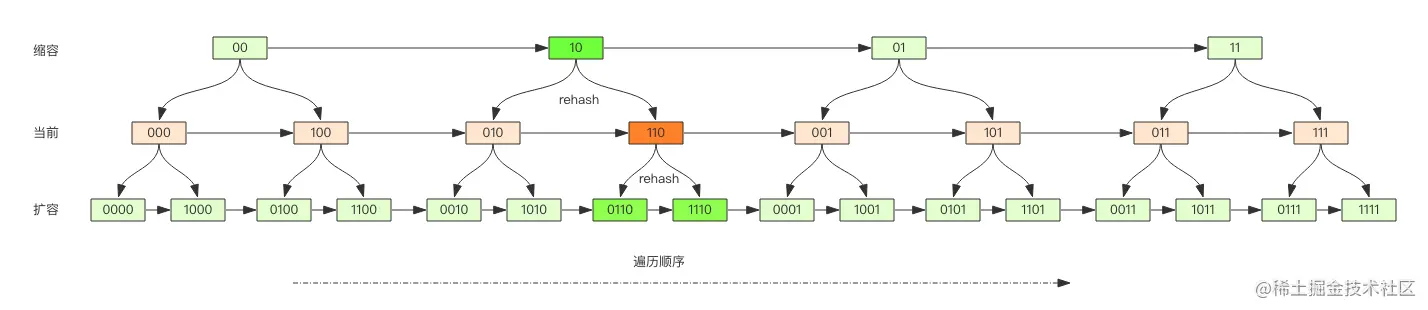
SCAN命令中的count参数为什么只能大概控制返回的数量?
// db.c/scanGenericCommand
do {
cursor = dictScan(ht, cursor, scanCallback, NULL, privdata);
} while (cursor &&
maxiterations-- &&
listLength(keys) < (unsigned long)count);
先根据cursor遍历数组,遍历的过程中并不会实时校验count值,只有遍历完一次cursor才会校验,如果数量已经大于等于count值了则不再遍历,否则接着遍历。
有待验证
因此遍历完的key总是大于count的,但是后续还会有根据pattern筛选的过程,因此count参数只能一个大概控制返回数量的作用
参考博客
命令实现
[1]https://www.jianshu.com/p/be15dc89a3e8
scan详解
[2]http://redisdoc.com/database/scan.html#scan
原理解析与踩坑
[3]https://www.lixueduan.com/post/redis/redis-scan/
踩坑记录
[4]https://blog.51cto.com/u_15127597/4726910
scan实现原理
[5]https://blog.csdn.net/weixin_43705457/article/details/105255962















 1642
1642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











